





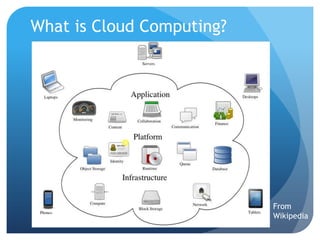


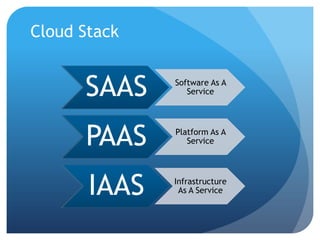





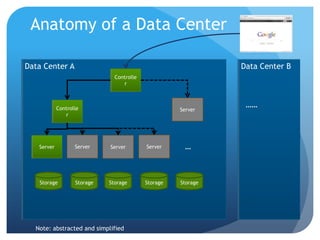
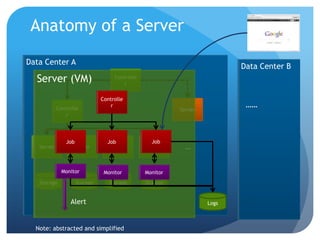
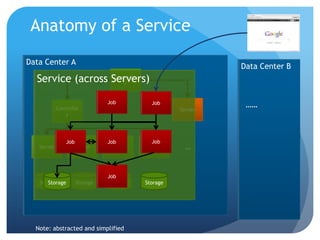

















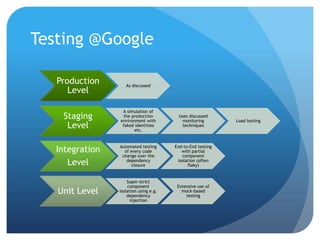

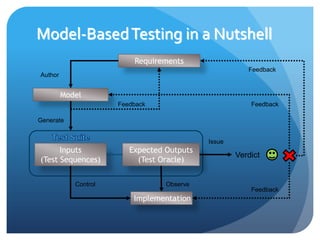

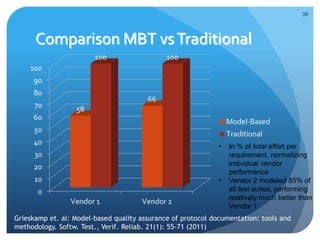







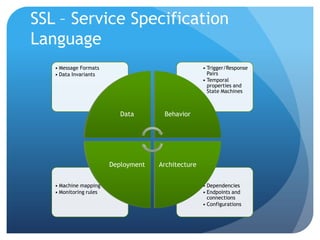


The document discusses runtime analysis challenges and opportunities in cloud computing, specifically focusing on monitoring and testing methodologies used by Google. It highlights distinct approaches such as black-box and white-box monitoring, the role of logs, and model-based testing, while addressing issues like state management and the integration of testing frameworks. Overall, the author emphasizes that while cloud computing introduces new operational paradigms, it doesn't fundamentally change the underlying problems in runtime verification and testing.



































































