Downloaded 19 times






![ULTRA-SCALE AIOPS LAB 5
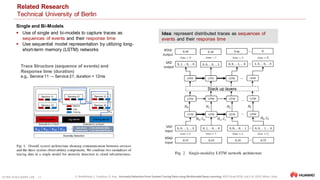
Troubleshooting
Monitoring Data Sources
Logs. Service, microservices, and applications
generate logs, composed of timestamped
records with a structure and free-form text,
which are stored in system files.
Metrics. Examples of metrics include CPU
load, memory available, and the response
time of a HTTP request.
Traces. Traces records the workflow and tasks
executed in response to, e.g., an HTTP
request.
Events. Major milestones which occur within a
data center can be exposed as events.
Examples include alarms, service upgrades,
and software releases.
{"traceId": "72c53", "name": "get", "timestamp": 1529029301238, "id": "df332",
"duration": 124957, “annotations": [{"key": "http.status_code", "value": "200"}, {"key":
"http.url", "value": "https://v2/e5/servers/detail?limit=200"}, {"key": "protocol", "value":
"HTTP"}, "endpoint": {"serviceName": "hss", "ipv4": "126.75.191.253"}]
{“tags": [“mem”, “192.196.0.2”, “AZ01”], “data”: [2483, 2669, 2576, 2560, 2549, 2506,
2480, 2565, 3140, …, 2542, 2636, 2638, 2538, 2521, 2614, 2514, 2574, 2519]}
{"id": "dns_address_match“, "timestamp": 1529029301238, …}
{"id": "ping_packet_loss“, "timestamp": 152902933452, …}
{"id": "tcp_connection_time“, "timestamp": 15290294516578, …}
{"id": "cpu_usage_average“, "timestamp": 1529023098976, …}
2017-01-18 15:54:00.467 32552ERROR oslo_messaging.rpc.server[req-c0b38ace -
default default] Exception during message handling
System’s Components (e.g., OBS, EVS, VPC, ECS) are monitored and generate various types of data:
Logs, Metrics, Traces, Events, Topologies](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-6-320.jpg)
![ULTRA-SCALE AIOPS LAB 6
INNOVATION PATH FORWARD
BACKGROUND & MOTIVATION DESCRIPTION ANTICIPATED IMPACT
Intelligent Log Analysis
Root Cause Localization using Application Logs
Problem
Complex system generates high volumes of logs
for manual analysis/troubleshooting. E.g., a single-
node check using logs takes >15 min
Analyzing logs manuallyis time
consuming and error-prone
IntelligentLog Analysis
Insight. Recent research has shown that it is
possible to identify and model the underlying
structure of application logs using ML [1, 2] Higher levels of visualization and abstraction are required (Bird's-eye
view, zoom in/out)
MAIN ACHIEVEMENT
Extracting valuableinsights form massive, noisyand
unstructured logs
Pattern mining and NLP are used to abstract and summarize
massive logs
Help O&M teams improving efficiency of troubleshooting using
logs
ASSUMPTIONS & LIMITATIONS
Processing requires historical logs to learn normality
No real-time processing. Only on-demand operation is available
Status
Higher levels of visualization and abstraction are
effective for operators to quickly troubleshoot
system using logs
Next steps
Research other forms of visualization (e.g., Kernel
Density Estimation, Network Diagrams,
Correlation Matrices)
TechnologyTransition
Evaluation of infrastructures to process ultra-scale
logs (e.g., batch versus stream processing)
Potential End Users
Service Owners, DevOps and SRE
Log Analysis
Log analysis can be integrated into traditional log
platforms
HOW IT WORKS
Performance is a challenge! Processing million
log records per second is difficult
1. Fast log template mining using
Drain algorithm
2. Language-aware log parsing
and keyword extraction using
NLP approaches (www.spacy.io)
3. Time-series classification using
Poisson model
(en.wikipedia.org/wiki/Poisson_d
istribution)
4. Grouping using Pearson
algorithm
(en.wikipedia.org/wiki/Pearson_c
orrelation_coefficient)
5. Distance-aware correlation
Fig.
Existing Log
Analysis services
(e.g., ELK)
10000 error messages
100 templates
30 events
6 eventscorrelated
Fig.
Complex
services
generates
several GB
of logs per
second
as-is
Template mining Template analysis
Visualization
Anomaly detection
Fig. The process of intelligent log analysis
to-be](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-7-320.jpg)

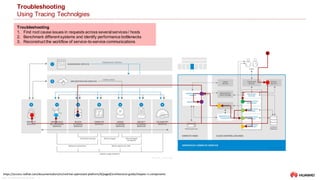
![ULTRA-SCALE AIOPS LAB 9
Tracing Technologies
Systems and pseudo-standards
Fig. Amazon AWS X-Ray
Fig. Google Cloud Trace
Fig. OpenTracing
Tracing Services
‒ Google Stackdriver(cloud.google.com/trace)
‒ Amazon AWS X-Ray (aws.amazon.com/xray)
‒ Lightstep (lightstep.com)
Tracing Systems
‒ Twitter Zipkin (zipkin.io)
‒ Uber Jaeger
‒ OSProfiler
‒ Pivot Tracing (pivottracing.io)
Tracing Standards
‒ opentelemetry.io
‒ OpenTracing
‒ OpenCensus
[1] http://opentracing.io/documentation/
[2] https://github.com/opentracing/specification/blob/master/specification.md
OpenTracing provides a consistent, expressive, vendor-neutral
APIs for popular platforms [1]
2019: The open source
distributed tracing projects
OpenCensus and OpenTracing
were merged into anew project
called OpenTelemetry](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-10-320.jpg)


![ULTRA-SCALE AIOPS LAB 14
Distributed Trace Analysis
Sequence Analysis
Sequence Prediction
‒ Predict elements of a sequence on the basis of the preceding elements
‒ Given si, si+1,…, sj, predict sj+1, si,si+1, i.e., sj →sj+1
‒ Input: 1, 2, 3, 4, 5; output: 6
‒ Applications: weather forecast
Sequence Classification
‒ Predict a class label for a given input sequence.
‒ Given si,si+1,…,sj, determine if it is legitimate, i.e., si,si+1,…,sj →yes or no
‒ Input: 1, 2, 3, 4, 5; output: “normal” or “anomalous”
‒ Applications: trace anomaly detection, DNA sequence classification
Sequence Generation
‒ Generate new output sequence with same general characteristics as the input
‒ Input: [1, 3, 5], [7, 9, 11]; output: [3, 5 ,7]
‒ Applications: text generation
Sequence to Sequence Prediction
‒ Predict an output sequence given an input sequence.
‒ Input: 1, 2, 3, 4, 5; output: 6, 7, 8, 9, 10
‒ Applications: text summarization
1, 2, 3, 4, 5 ► 6
1, 2, 3, 4, 5 ► NORMAL
1, 3, 5 and 7, 9, 11 ► 3, 5 ,7
1, 2, 3, 4, 5 ► 6, 7, 8, 9, 10
Sequence learning: from recognition and prediction to sequential decision making, IEEE Intelligent Systems, 2001,
http://www.sts.rpi.edu/~rsun/sun.expert01.pdf](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-13-320.jpg)


![ULTRA-SCALE AIOPS LAB 17
Distributed Trace Analysis
Using LSTMs
1. Model Openstackbehavior
OPENSTACK_SEQUENCE= [
('keystone', 1.0, 'authenticate user with credentials and generate auth-token'),
('nova-api', 1.0, 'get user request and sends token to Keystone for validation'),
('keystone', 0.2, 'validate the token if not in cache'),
('nova-api', 1.0, 'starts VM creation process'),
('nova-database', 1.0, 'create initial database entry for new VM'),
('nova-scheduler', 1.0, 'locate an appropriate host using filters and weights'),
('nova-database', 1.0, 'execute query'),
('nova-compute', 1.0, 'dispatches request'),
('nova-conductor', 1.0, 'gets instance information'),
('nova-compute', 1.0, 'get image URI from image service'),
('glance-api', 1.0, 'get image metadata'),
('nova-compute', 1.0, 'setup network'),
('neutron-server', .5, 'allocate and configure network IP address'),
('nova-compute', 1.0, 'setup volume'),
('cinder-api', .75, 'attach volume to the instance or VM'),
('nova-compute', 1.0, 'generates data for the hypervisor driver')
]
3. Transform traces into sequences of integers
Train dataset
span_list
trace_id
0 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 6, 1, 6]
1 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 6, 1, 6]
2 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 4, 6, 1, 6]
3 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 4, 6, 6]
4 [3, 5, 3, 5, 8, 9, 8, 6, 7, 6, 2, 6, 6, 1, 6]
... ...
95 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 6, 1, 6]
96 [3, 5, 3, 5, 8, 9, 8, 6, 7, 6, 2, 6, 4, 6, 6]
97 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 6, 1, 6]
98 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 4, 6, 1, 6]
99 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 4, 6, 1, 6]
[100 rows x 1 columns]
Test dataset
span_list
trace_id
0 [3, 5, 5, 1, 9, 8, 6, 7, 6, 2, 6, 6, 1, 6]
1 [3, 5, 5, 8, 9, 8, 6, 7, 6, 2, 6, 4, 6, 6]
[0,
['keystone',
'nova-api',
'nova-api',
'nova-database',
'nova-scheduler',
'nova-database',
'nova-compute',
'nova-conductor',
'nova-compute',
'glance-api',
'nova-compute',
'nova-compute',
'cinder-api',
'nova-compute']]
Cache Simulation: Probability of execution = 75%
Trace #0
Generate Synthetic Traces (generate_traces())
‒ Create a simple model to generate traces
‒ OPENSTACK_SEQUENCE models sequences of spans which are valid
• e.g., ['keystone‘, 'nova-api', 'nova-api', 'nova-database', 'nova-scheduler', 'nova-database', 'nova-compute', 'nova-
conductor', 'nova-compute', 'glance-api', 'nova-compute', 'nova-compute', 'cinder-api', 'nova-compute']
‒ Each microservice name is encoded into a number using a dictionary (create_coders())
Trace Mutation (mutate_traces())
‒ Selected synthetic traces are mutated
‒ Spans can be deleted or replaced
2. Generate Synthetics Traces](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-16-320.jpg)
![ULTRA-SCALE AIOPS LAB 18
Distributed Trace Analysis
Using LSTMs
[[0 0 3 ... 6 1 6]
[0 0 3 ... 6 1 6]
[0 3 5 ... 6 1 6]
...
[0 0 3 ... 6 1 6]
[0 3 5 ... 6 1 6]
[0 3 5 ... 6 1 6]]
Padding
2. Hot encoding
Tensorflow tutorial: https://github.com/campdav/text-rnn-tensorflow
Keras tutorial: https://github.com/campdav/text-rnn-keras
Code available at: https://github.com/jorge-cardoso/aiops_practice
Subdirectory:dta_lstm
Padding (_pad_traces())
‒ Pad each trace (sequence) with zeros (0), up to a pre-defined maximum length.
‒ This allows to pre-allocate a chain of LSTM units of a specific length
‒ Padding is done using pad_sequences(sequences,...)
One hot encoding (_traces_to_binary())
‒ Enables to represent categorical variables as binary vectors
‒ Each integer value is represented as a binary vector that has all zero values except the index of the integer, which is
marked with a 1
X = pad_sequences(X, maxlen=self.trace_size, dtype=np.int16,
truncating='pre', padding='pre',
value=DEFAULTS['padding_symbol'])
maxlen: int, maximum length of all sequences.
truncating='pre' remove values at the beginning from sequences larger than maxlen
padding='pre' pads each trace at the beginning with a special integer (e.g., 0)
1. Padding
keras.utils.to_categorical(X, num_classes=self.max_n_span_types,
dtype='int32')
X.shape = (n_traces, self.trace_size)
returns shape = (n_traces, self.trace_size, self.max_n_span_types)
[[[1. 0. 0. ... 0. 0. 0.]
[1. 0. 0. ... 0. 0. 0.]
[0. 0. 1. ... 0. 0. 0.]
...
]
]](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-17-320.jpg)
![ULTRA-SCALE AIOPS LAB 19
Distributed Trace Analysis
Using LSTMs
X [[0 0 3 ... 6 1 6]
[0 0 3 ... 6 1 6]
[0 3 5 ... 6 1 6]
...
[0 0 3 ... 6 1 6]
[0 3 5 ... 6 1 6]
[0 3 5 ... 6 1
6]]
y [[0 0 5 ... 1 6 0]
[0 0 5 ... 1 6 0]
[0 5 5 ... 1 6 0]
...
[0 0 5 ... 1 6 0]
[0 5 5 ... 1 6 0]
[0 5 5 ... 1 6 0]]
Generate y
‒ Shift traces by one position to the left
‒ Fill new cell with DEFAULTS['padding_symbol']
# X.shape is n_traces
# X.shape.y is self.trace_size
y = np.roll(X, -1, axis=1)
# Pad j array where X array has zeros
y[X == 0] = DEFAULTS['padding_symbol']
# Write the DEFAULTS['padding_symbol'] at the last
position of the shifted array
y[:, -1] = DEFAULTS['padding_symbol']
1. Generate y by shifting X
0 3 5 2 1 7X
y 0 5 2 1 7 0
Shift traces left](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-18-320.jpg)
![ULTRA-SCALE AIOPS LAB 20
Distributed Trace Analysis
Using LSTMs
Create DL model (_build_model())
‒ Use a LSTM network
‒ dropout layer of 0.2 (high, but necessary to avoid quick divergence)
‒ Softmax activation to generate probabilities over the different categories
‒ Because it is a classification problem, loss calculation via categorical cross-entropy compares the output probabilities
against one-one encoding
‒ ADAM optimizer (instead of the classical stochastic gradient descent) to update weights
model = Sequential()
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2, return_sequences=True,
input_shape=(self.trace_size, input_dim)))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2, return_sequences=True))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2, return_sequences=True))
# A Dense layer is used as the output for the network.
model.add(TimeDistributed(Dense(input_dim, activation='softmax')))
if self.gpus > 1:
model = keras.utils.multi_gpu_model(model, gpus=self.gpus)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
1. Create DL model](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-19-320.jpg)
![ULTRA-SCALE AIOPS LAB 21
Distributed Trace Analysis
Using LSTMs
Train the model (fit())
‒ X = Obtains the traces composed of spans
‒ Pad the traces of X
‒ y = Shift the spans of the traces left
‒ Apply an one hot encoding to X and y
‒ Build the model
‒ Fit the model f(X) = y
# X_train has 2 columns: traceId, span_list. Here we select the span_list
X_train = X_train.loc[:, DEFAULTS['span_list_col_name']].values
X = self._pad_traces(X_train)
y = self._shift_traces_left(X)
self._get_lstm_parameters(X)
X = self._traces_to_binary(X)
y = self._traces_to_binary(y)
self.model = self._build_model(input_dim=X.shape[2])
self.model.fit(X, y, epochs=self.epochs, batch_size=self.batch_size, shuffle=True,
validation_split=self.validation_split)
1. Train the model](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-20-320.jpg)
![ULTRA-SCALE AIOPS LAB 22
Distributed Trace Analysis
Using LSTMs
Test Traces
X [[0 0 3 5 5 1 9 8 6 7 6 2 6 6 1 6]
[0 0 3 5 5 8 9 8 6 7 6 2 6 4 6 6]]
X[0]: [0 0 3 5 5 1 9 8 6 7 6 2 6 6 1 6] =
[[0, 0.2625601], [1, 0.38167596], [0, 0.75843567],
[0, 0.8912414], [9, 2.394792e-05], [0, 0.94694203],
[0, 0.9656691], [0, 0.9686248], [0, 0.9666971],
[0, 0.95213455], [0, 0.94981205], [0, 0.93016535],
[0, 0.60129535], [0, 0.5417027], [0, 0.6876041],
[0, 0.82936114]]
X[1]: [0 0 3 5 5 8 9 8 6 7 6 2 6 4 6 6] =
[[0, 0.2625601], [1, 0.38167596], [0, 0.75843567],
[0, 0.8912414], [0, 0.9302344], [0, 0.94507533],
[0, 0.9638574], [0, 0.9665326], [0, 0.9627945],
[0, 0.9435249], [0, 0.9405963], [0, 0.92075515],
[1, 0.3207201], [1, 0.46595544], [0, 0.64980185],
[0, 0.8390282]]
trace_id 0 indices [4]
trace_id 1 indices []
Test traces (predict())
‒ X = Obtains the traces composed of spans
‒ Pad the traces of X
‒ Apply an one hot encoding to X
‒ Calculate: yhat = f(X)
‒ Identify in which spans the anomalies occur
X_test = X_test.loc[:, DEFAULTS['span_list_col_name']].values
X_test = self._pad_traces(X_test)
X_test_bin = self._traces_to_binary(X_test)
yhat = self.model.predict(X_test_bin)
self._identify_anomalies(X_test, yhat, prob=self.threshold)
return self.rank_prob
1. Test unseen traces](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-21-320.jpg)
![ULTRA-SCALE AIOPS LAB 23
Distributed Trace Analysis
Using LSTMs
Identifying Anomalous Traces Sequences (_identify_anomalies())
‒ Mark anomalies based on the difference between y and yhat
‒ y is the shifted version of X
‒ yhat = f(X)
‒ If we cannot predict correctly the shift, this means the trace is did not occur before and is marked as anomalous
y = DTA_LSTM._shift_traces_left(X)
for i in range(len(X)):
rp = self._compare_traces(y[i], yhat[i])
self.rank_prob.append(rp)
if self.explain:
print('X[{}]: {} = {}'.format(i, X[i], rp))
return self.rank_prob
Input X = [0 0 3 5 5 1 9 8 6 7 6 2 6 6 1 6]
Shifted_X = [0 0 5 5 1 9 8 6 7 6 2 6 6 1 6 0]
Prediction
yhat = [0 0 5 5 12 9 8 6 7 6 2 6 6 1 6 0]
X[0]: [0 0 3 5 5 1 9 8 6 7 6 2 6 6 1 6] =
[[0, 0.2625601], [1, 0.38167596], [0, 0.75843567],
[0, 0.8912414], [9, 2.394792e-05], [0, 0.94694203],
[0, 0.9656691], [0, 0.9686248], [0, 0.9666971],
[0, 0.95213455], [0, 0.94981205], [0, 0.93016535],
[0, 0.60129535], [0, 0.5417027], [0, 0.6876041],
[0, 0.82936114]]
Error at index [4]
X[i]: Input: [ 0 0 0 0 0 0 0 0 0 0 0 10 10 17 5 5 7 7 6 6]
y[i]: Output: [ 0 0 0 0 0 0 0 0 0 0 0 10 17 5 5 7 7 6 6 0]
yhat[i]: Predicted: [ 0 0 0 0 0 0 0 0 0 0 0 10 17 5 5 7 7 6 6 0]
Correct prediction](https://image.slidesharecdn.com/2020-11-03-distributedtraceandloganalysisusingml-201106054342/85/Distributed-Trace-Log-Analysis-using-ML-22-320.jpg)



The document discusses the application of artificial intelligence for IT operations (AIOps) to enhance monitoring, automation, and troubleshooting of large-scale distributed systems. It emphasizes the use of machine learning, deep learning, and various analytics technologies to detect, localize, predict, and remediate failures in cloud infrastructures by analyzing monitoring data, particularly distributed traces. Dr. Jorge Cardoso leads Huawei's research on AIOps, focusing on intelligent cloud operations and innovative analytics tools to improve operational reliability and efficiency.






























































