The document discusses processing graph and relational data using MapReduce and Bulk Synchronous Parallel (BSP) models. It describes how most graph algorithms have irregular dependencies between tasks that arise during execution. It provides examples of graph algorithms and discusses challenges in partitioning graph data for parallel processing. It also summarizes the BSP model and how it can be applied to graph algorithms through examples like single-source shortest path.


![Irregular Algorithms
● Often operate on data structures with
complex topologies:
– Graphs, trees, grids, ...
– Where “data elements” are connected by
“relations”
● Computations on such structures depend
strongly on relations between data elements
– primary source of dependencies between
tasks
more in [ADP] “Amorphous Data-parallelism in Irregular Algorithms”](https://image.slidesharecdn.com/graphprocessingonmrandbsp-110225124133-phpapp02/85/Processing-graph-relational-data-with-Map-Reduce-and-Bulk-Synchronous-Parallel-3-320.jpg)

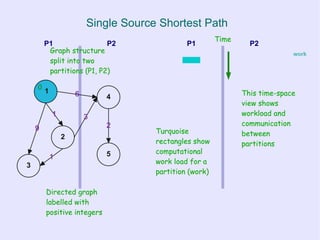
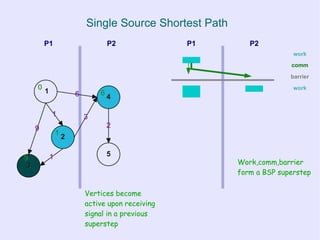
![Iterative Vertex-based Graph Algorithms
● Iteratively:
– Compute local function of a vertex that
depends on the vertex state and local
graph structure (neighbourhood)
– and/or Modify local state
– and/or Modify local topology
– pass messages to neighbouring nodes
● -> “vertex-based computation”
Amorphous Data-Parallelism [ADP] operator formulation:
“repeated application of neighbourhood operators in a specific order”](https://image.slidesharecdn.com/graphprocessingonmrandbsp-110225124133-phpapp02/85/Processing-graph-relational-data-with-Map-Reduce-and-Bulk-Synchronous-Parallel-6-320.jpg)

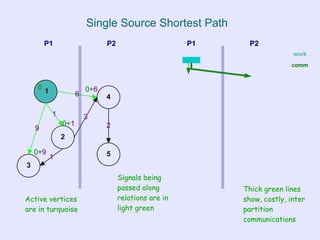
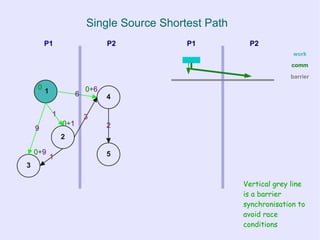







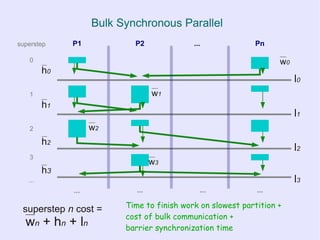
![Bulk Synchronous Parallel
● Advantages
– Simple and portable execution model
– Clear cost model
– No concurrency control, no data races,
deadlocks, etc.
● Disadvantages
– Coarse grained
●Depends on a large “parallel slack”
– Requires well-partitioned problem space for
efficiency (well balanced partitions)
more in [BSP] “A bridging model for parallel computation”](https://image.slidesharecdn.com/graphprocessingonmrandbsp-110225124133-phpapp02/85/Processing-graph-relational-data-with-Map-Reduce-and-Bulk-Synchronous-Parallel-20-320.jpg)


![SSSP - Map-Reduce Naive
● Idea [DPMR]:
– In map phase:
● emit both signals and local vertex
structure and state
– In reduce phase:
● gather signals and local vertex
structure messages
● reconstruct vertex structure and state](https://image.slidesharecdn.com/graphprocessingonmrandbsp-110225124133-phpapp02/85/Processing-graph-relational-data-with-Map-Reduce-and-Bulk-Synchronous-Parallel-23-320.jpg)


![Inline Combiners
● In job configure:
– Initialize a map<NodeId, Distance>;
● In job map operation:
– Do not emit interm. pairs ( emit(nbr.id, dist) ) ;
– Store them in the local map;
– Combine values in the same slots.
● In job close:
– Emit a value from each slot in the map to a
corresponding neighbour
● emit(nbr.id, map[nbr.id])](https://image.slidesharecdn.com/graphprocessingonmrandbsp-110225124133-phpapp02/85/Processing-graph-relational-data-with-Map-Reduce-and-Bulk-Synchronous-Parallel-26-320.jpg)





![MR Graph Processing Design Pattern
● [DPMR] reports 60% 70% improvement over naive
implementation
● Solution closely resembles the BSP model](https://image.slidesharecdn.com/graphprocessingonmrandbsp-110225124133-phpapp02/85/Processing-graph-relational-data-with-Map-Reduce-and-Bulk-Synchronous-Parallel-32-320.jpg)



![References
● [ADP] “Amorphous Data-parallelism in Irregular Algorithms”, Keshav
Pingali et al.
● [BSP] “A bridging model for parallel computation”, Leslie G. Valiant
● [DPMR] “Design Patterns for Efficient Graph Algorithms in
MapReduce”, Jimmy Lin and Michael Schatz](https://image.slidesharecdn.com/graphprocessingonmrandbsp-110225124133-phpapp02/85/Processing-graph-relational-data-with-Map-Reduce-and-Bulk-Synchronous-Parallel-36-320.jpg)















































