



















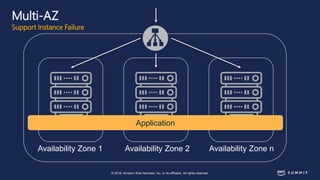
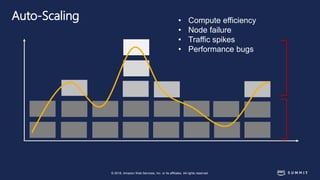



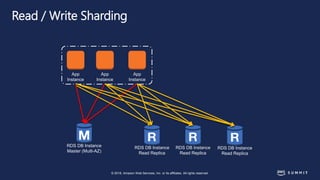
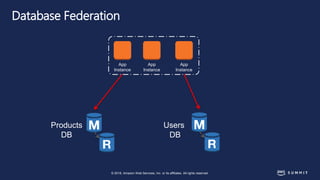
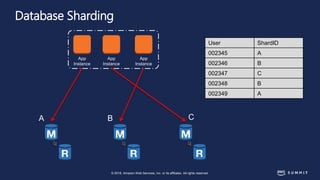
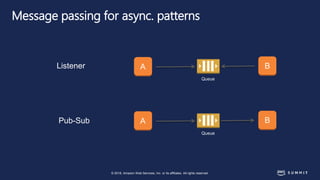
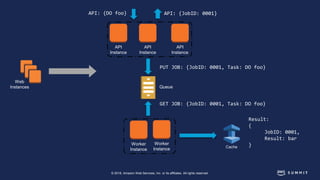
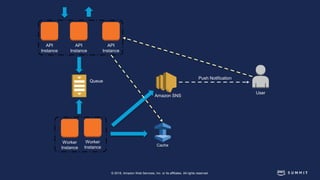

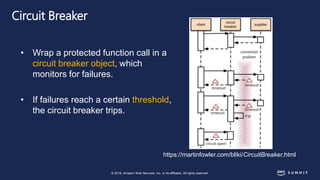
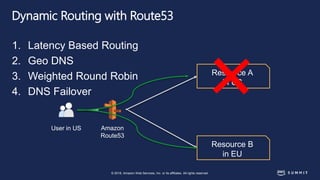

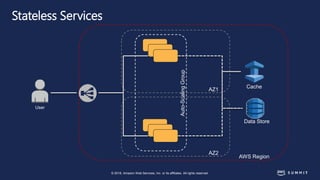

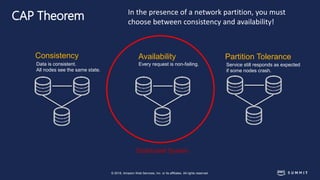

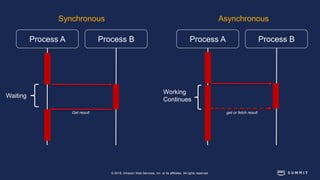






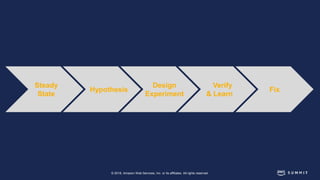






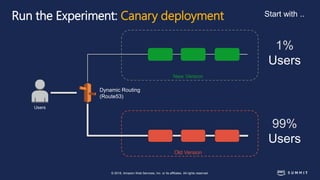










The document discusses chaos engineering, defined as the practice of experimenting on distributed systems to build confidence in their ability to handle failures. It emphasizes the importance of identifying weaknesses through controlled failures and outlines strategies for building resilient architectures, such as infrastructure as code and auto-scaling. Additionally, it addresses challenges in adopting chaos engineering within teams and the cultural changes required to implement it effectively.



































































