



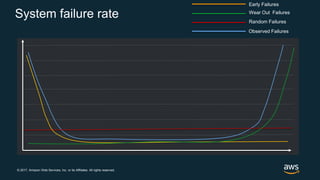
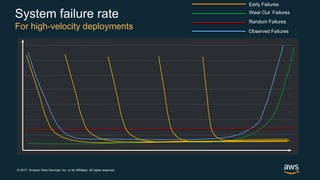




















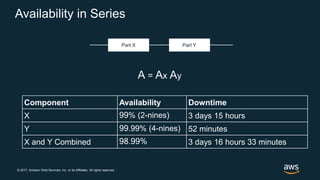

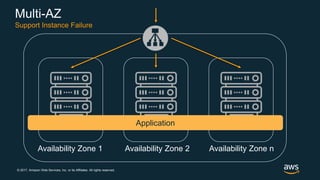
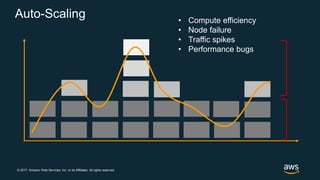




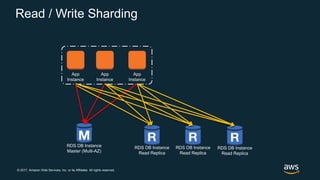
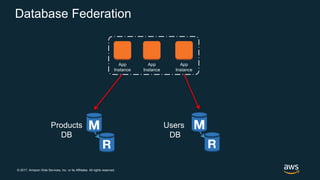
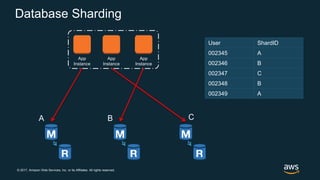
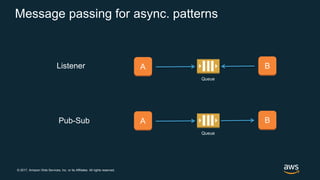
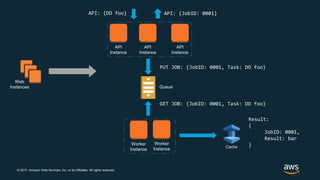
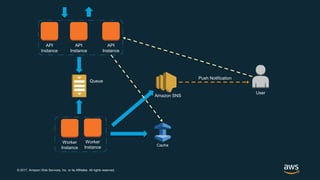
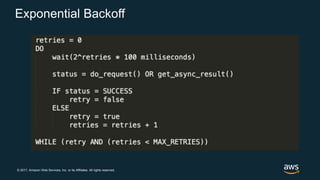
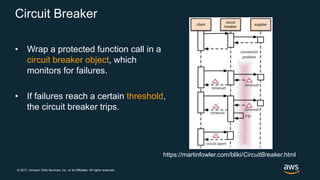
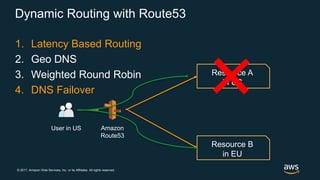
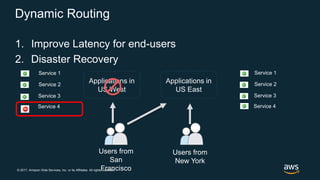

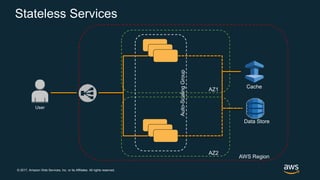

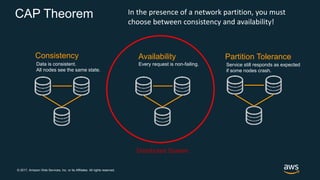

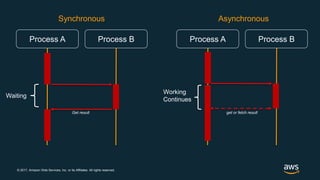







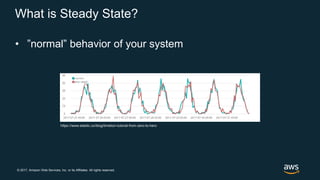


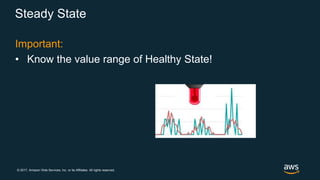








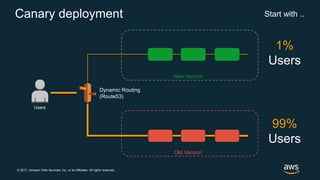














The document discusses chaos engineering, which is the practice of intentionally breaking systems to identify and mitigate weaknesses, thereby increasing their resilience. It emphasizes the importance of controlled experiments in production environments to enhance system reliability and outlines various failure injection techniques and methodologies for conducting these experiments. Key concepts include understanding system availability, employing immutable infrastructure, and leveraging tools like Netflix's chaos monkeys for testing purposes.

























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









