


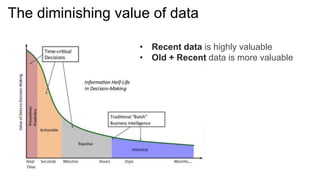



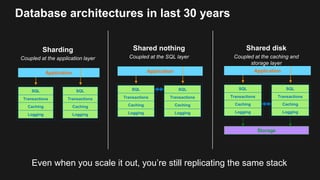
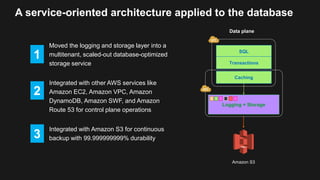
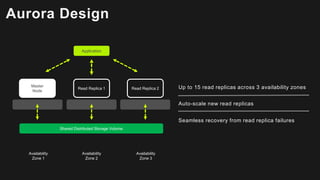
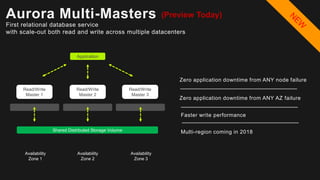



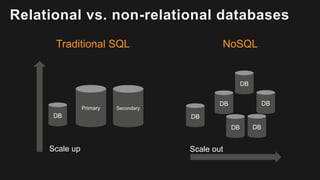
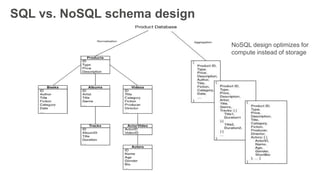
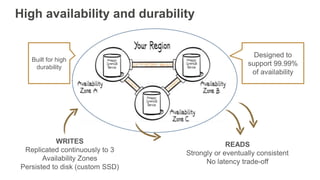


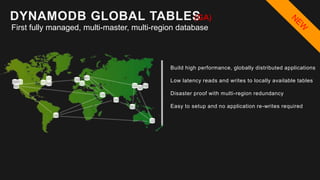
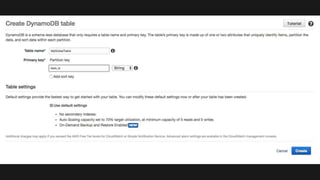
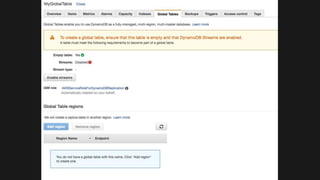
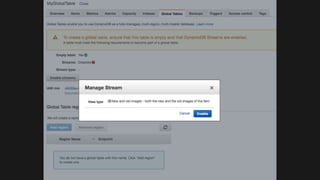
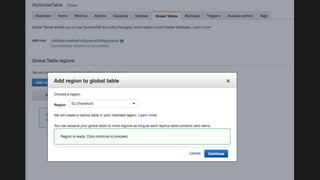
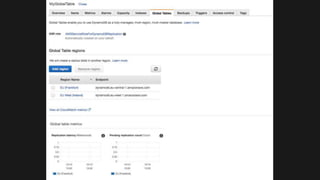
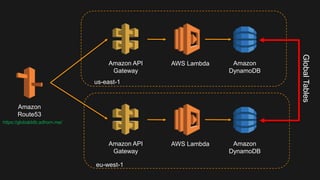

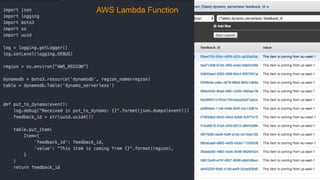

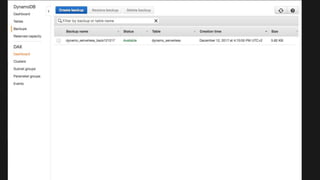
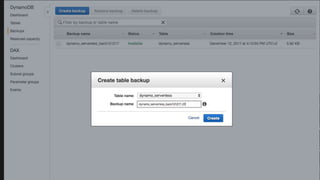
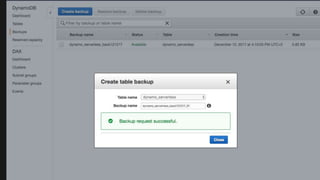
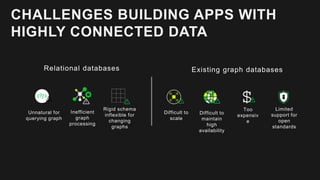
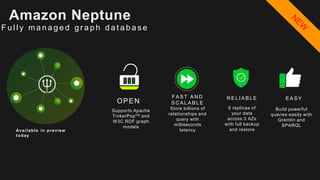

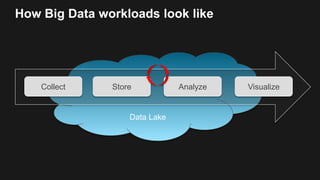
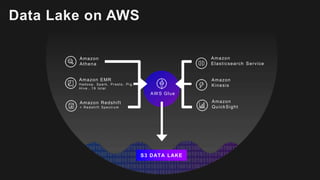
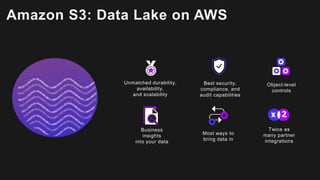

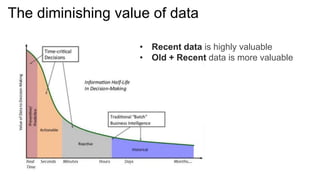
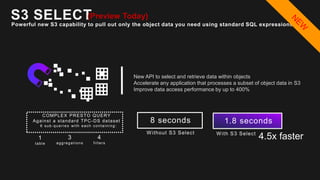




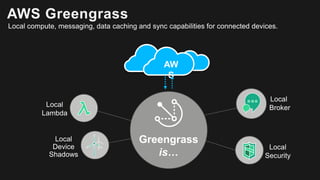
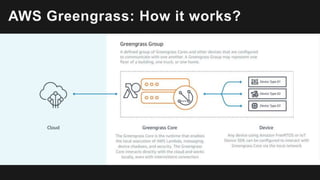

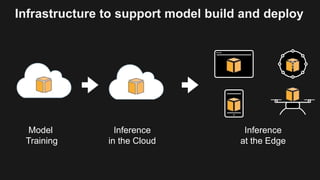
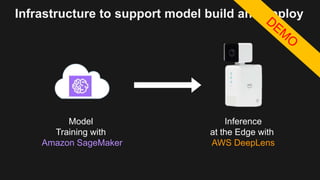


The document outlines the capabilities and advantages of Amazon Aurora, emphasizing its speed, cost-effectiveness, and compatibility with MySQL and PostgreSQL. It also covers the evolution of databases, detailing features of both relational and non-relational databases, including Amazon DynamoDB and Amazon Neptune, alongside AWS tools for data management and analytics. Key topics include the importance of recent data, the benefits of serverless databases, and the role of IoT in enhancing business decisions.























































































