Download to read offline





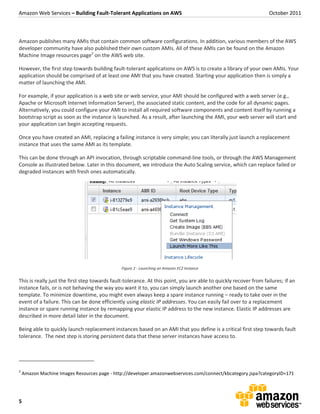











The document discusses building fault-tolerant applications on Amazon Web Services (AWS). Some key ways to achieve fault tolerance highlighted in the document include: 1) Using Amazon Machine Images (AMIs) which contain application software configurations that can be easily launched across multiple server instances for redundancy. 2) Leveraging services like Auto Scaling to automatically launch new instances when demand increases or failures occur, Elastic Load Balancing to distribute traffic across instances, and Availability Zones which provide isolated infrastructure in each zone. 3) Storing data in fault-tolerant services like Amazon S3, SimpleDB, and RDS to ensure data availability even if server instances fail.



















![[CPT DevOps Meetup] Developing Modern Applications in the Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/devopsdeveloping-modern-applications-in-the-cloud-no-notes-190718062311-thumbnail.jpg?width=640&height=640&fit=bounds)










































