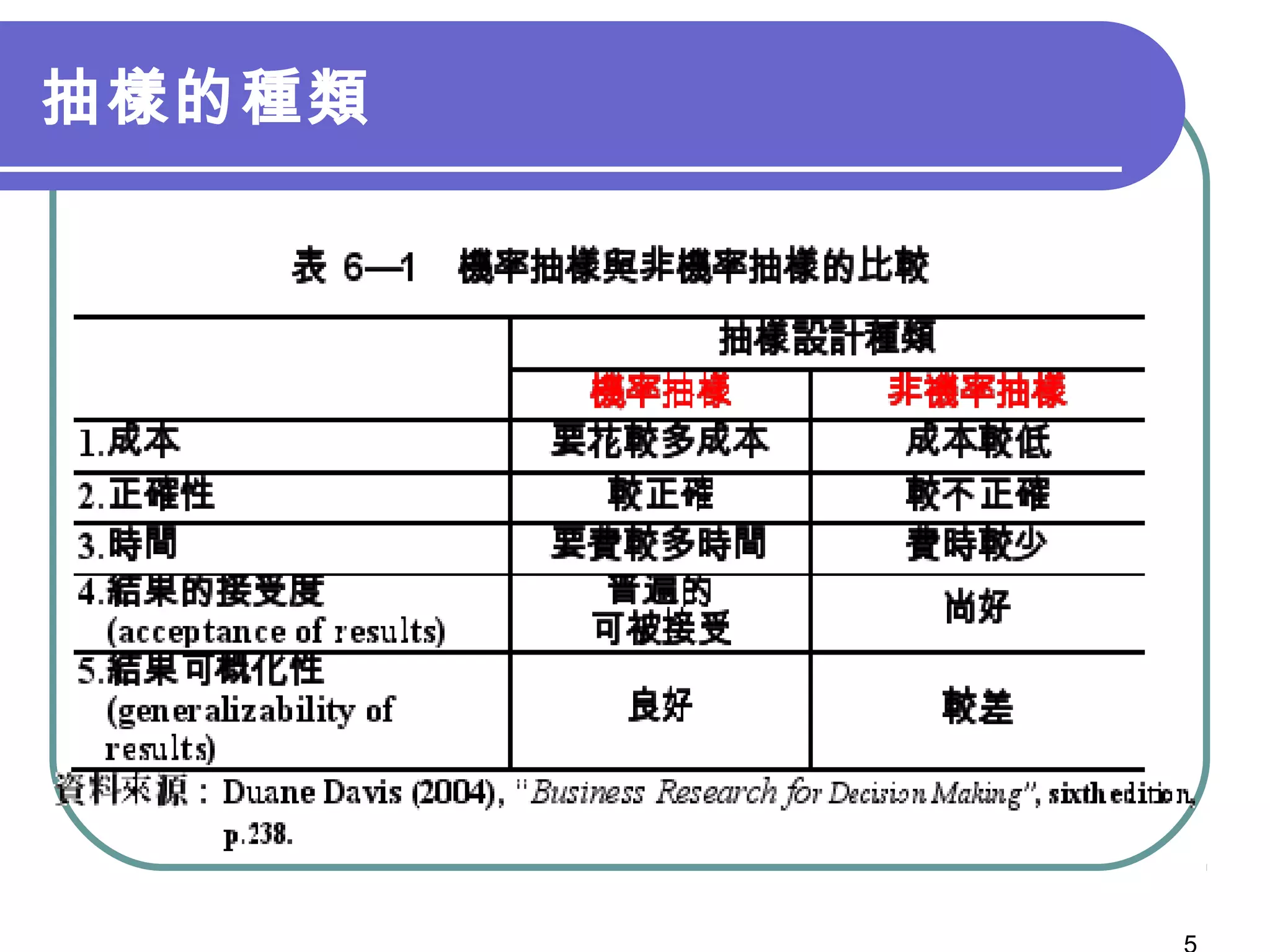
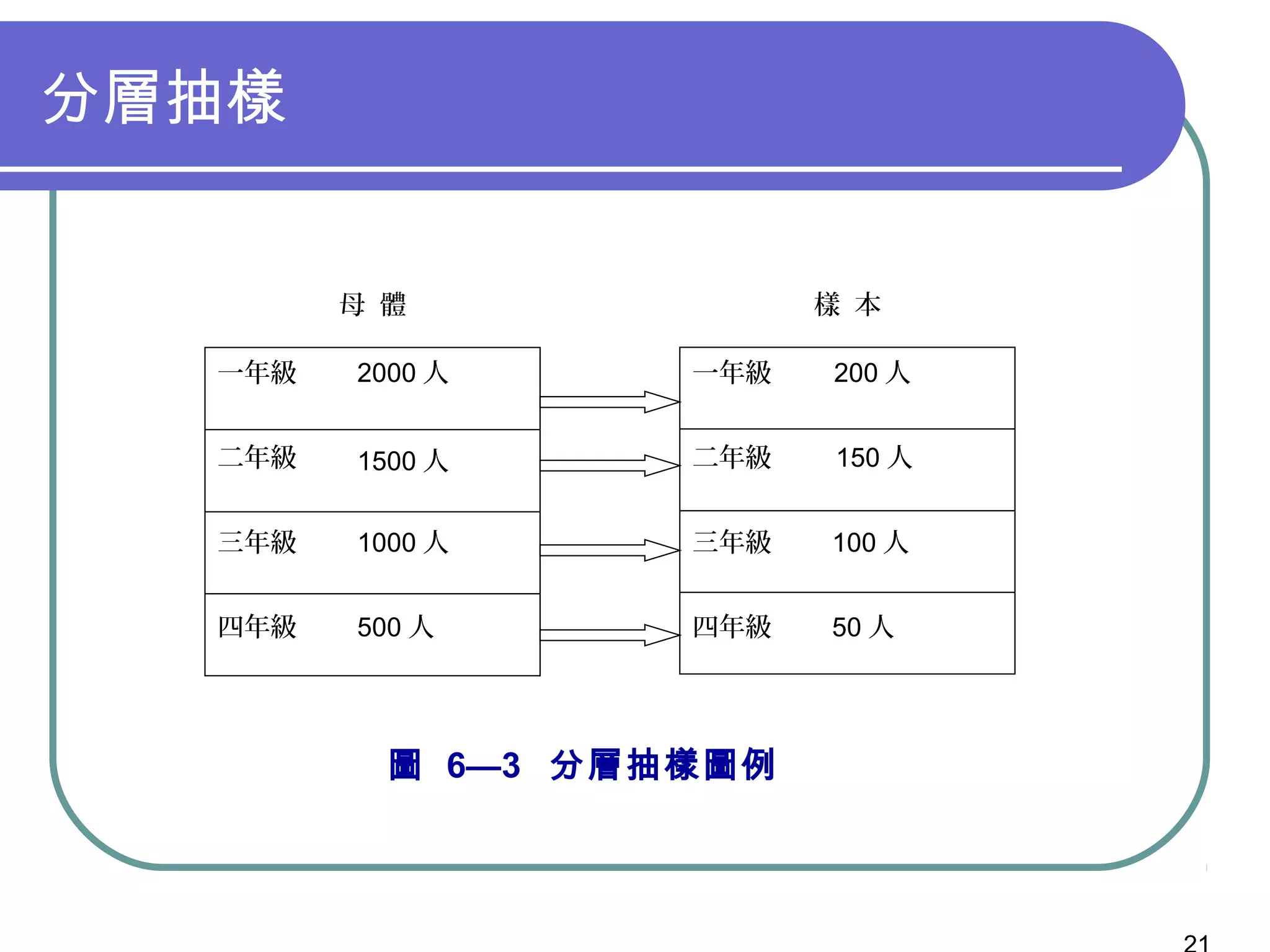
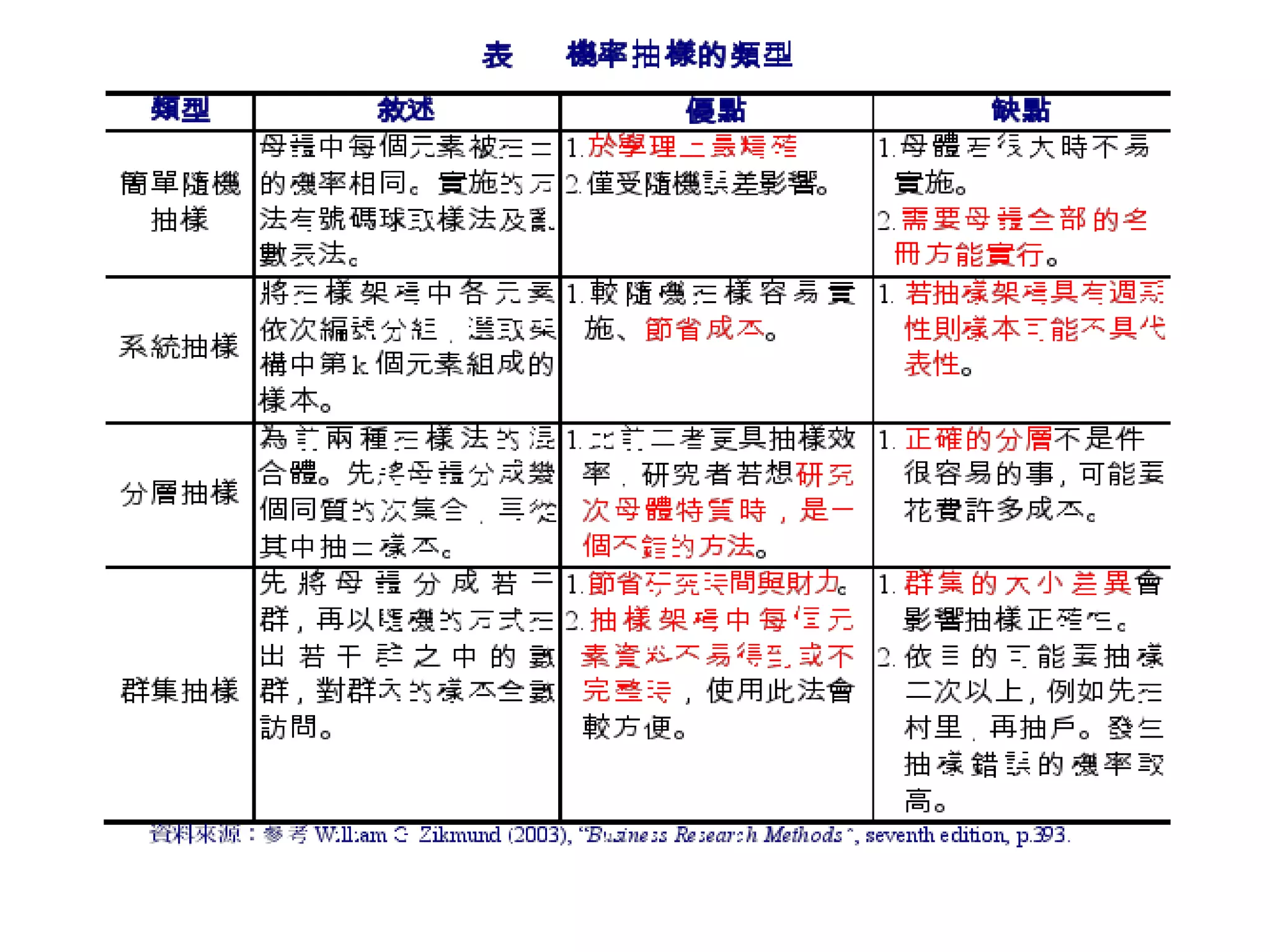
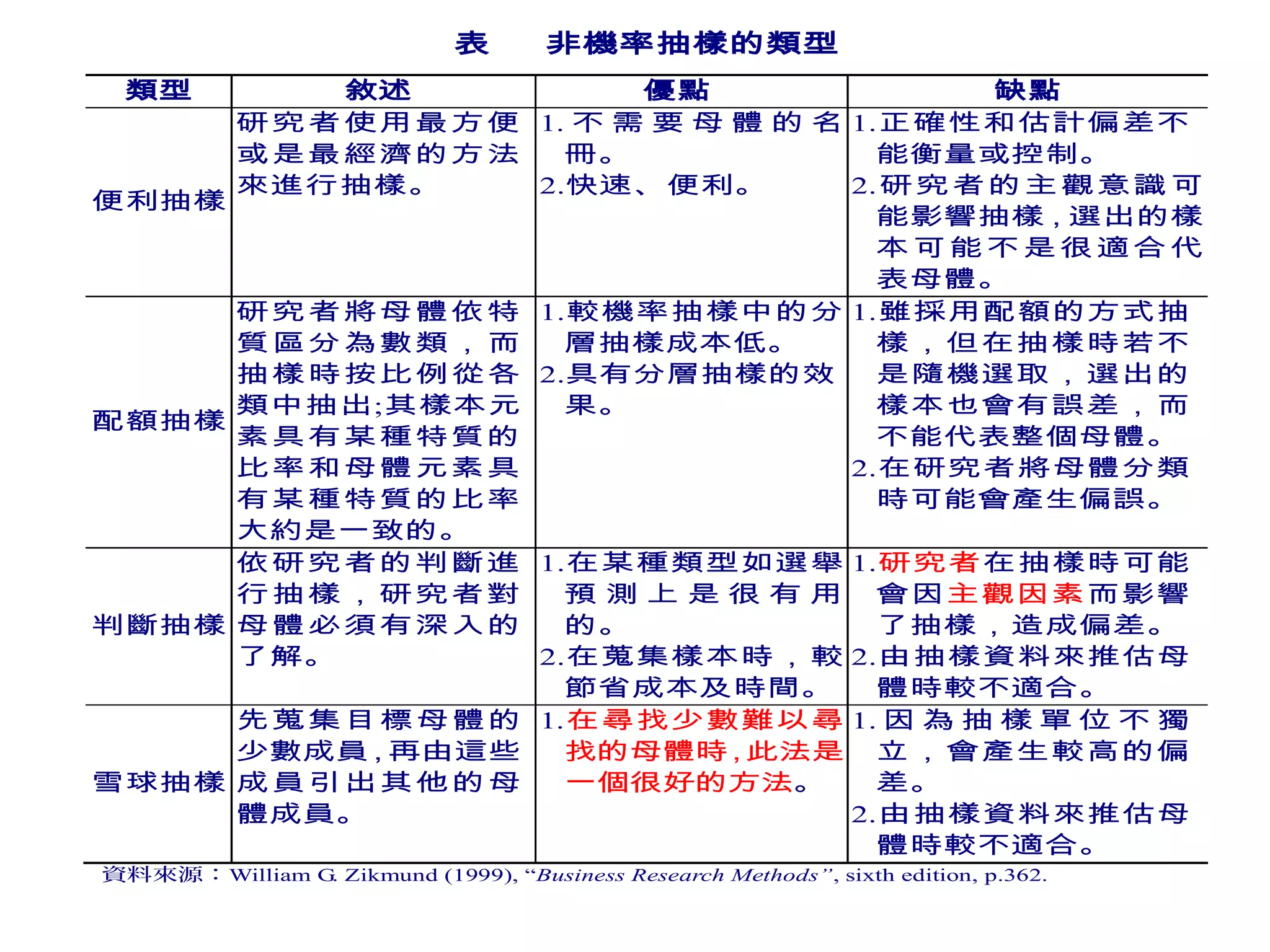
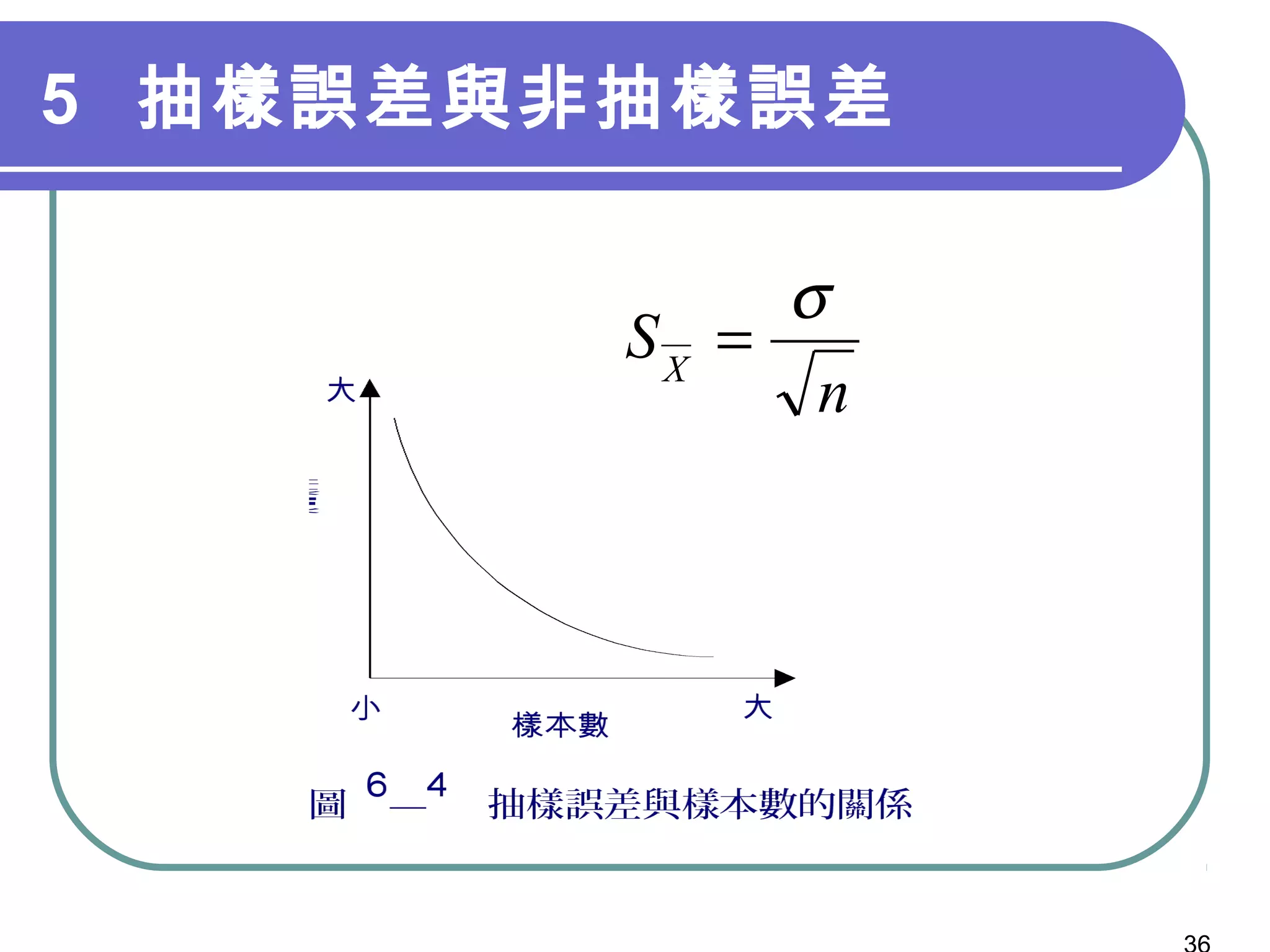
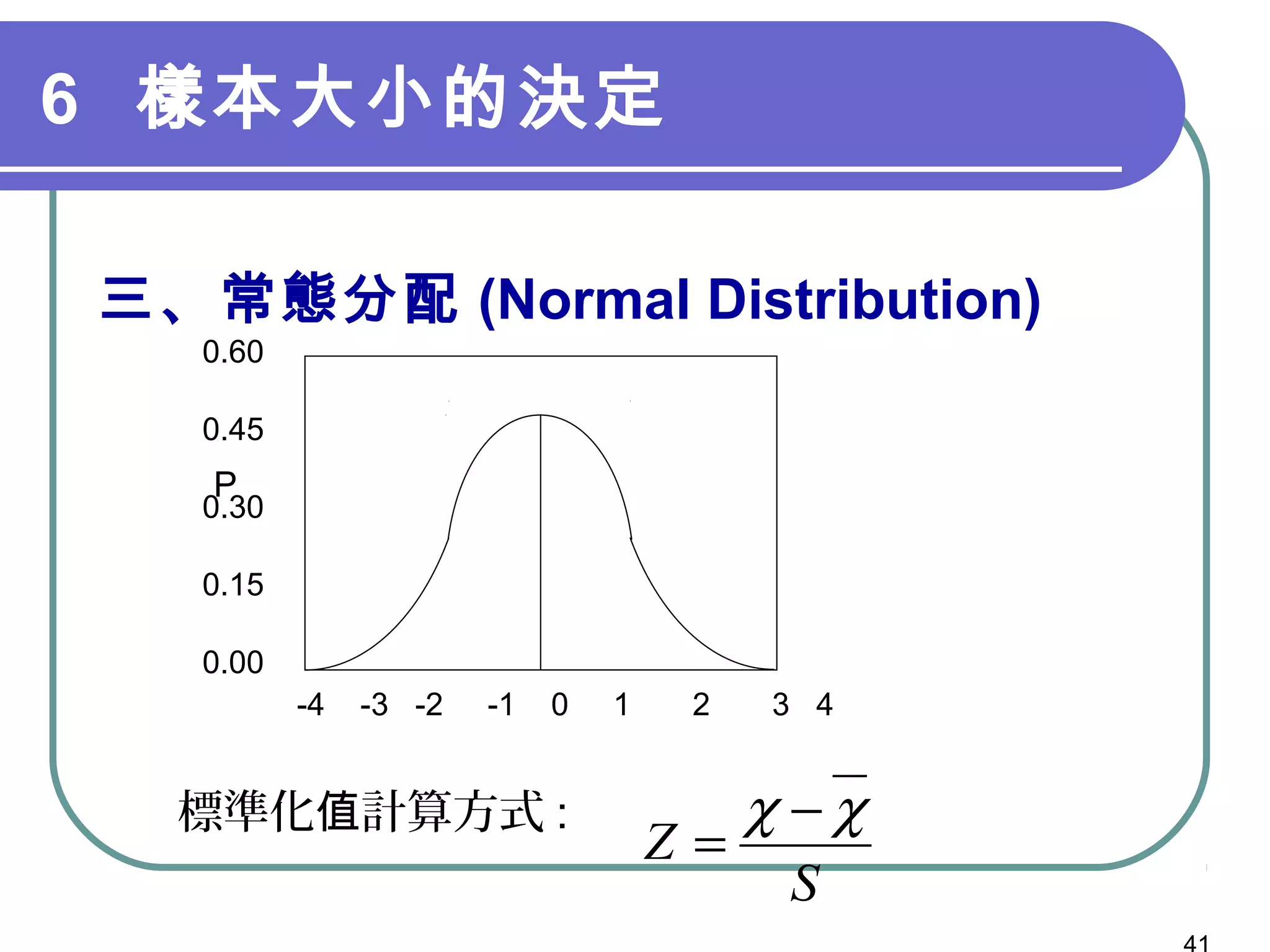
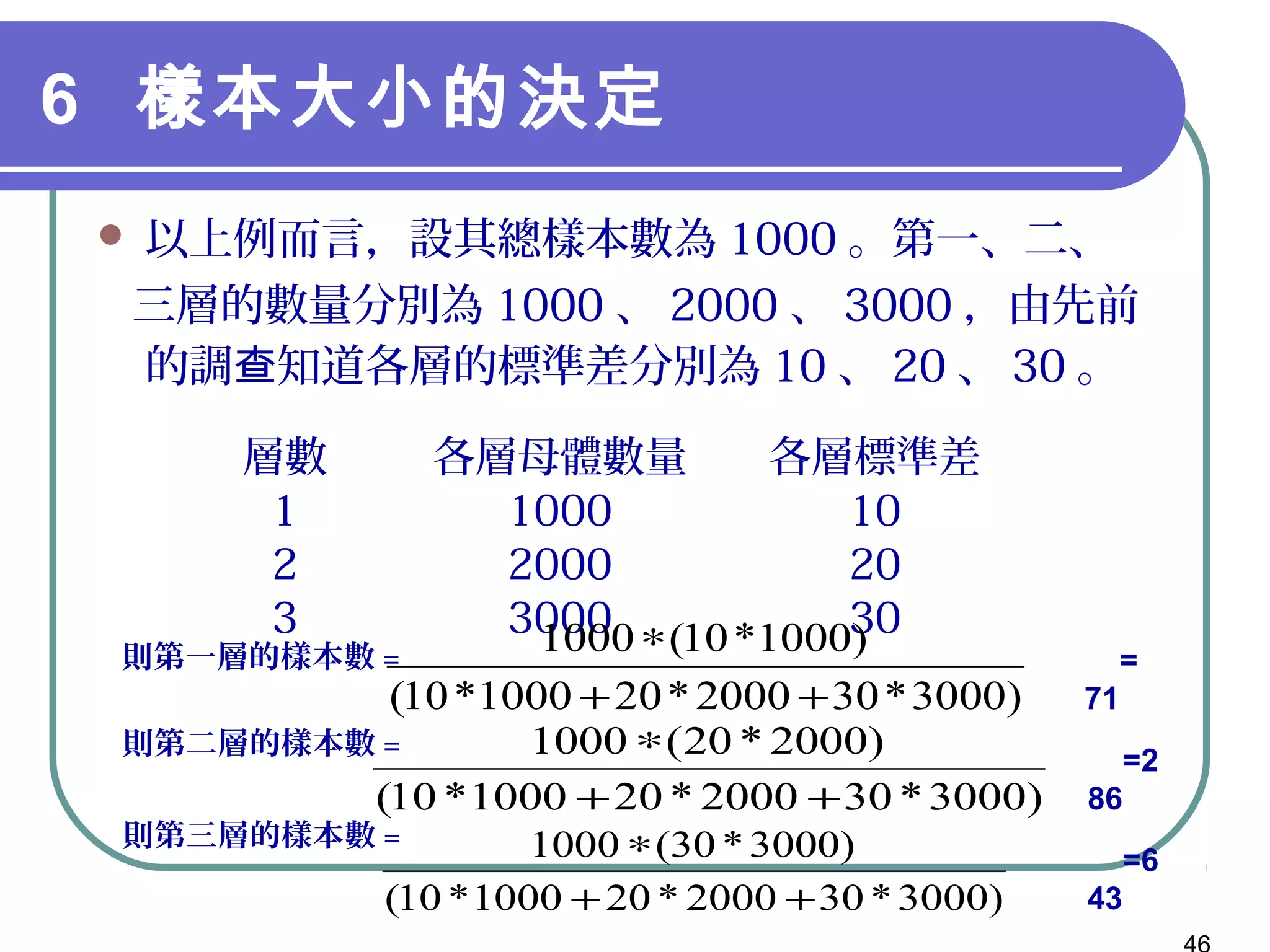
第9章讲述了抽样设计的基本概念和程序,包括概率抽样和非概率抽样的不同方法及其特性。文中强调了如何定义目标母体、选择抽样方法、确定样本大小以及最终的数据收集步骤。此章的内容对研究者在进行有效调查时具有重要指导意义。