Download to read offline




















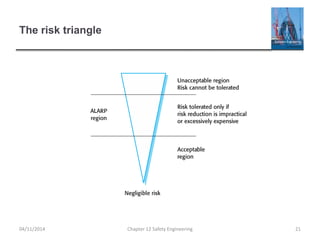


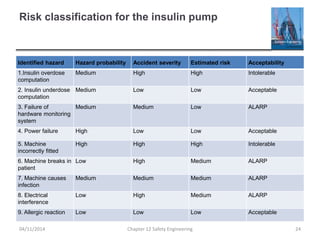


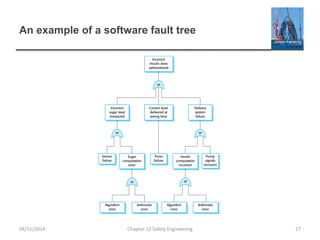





















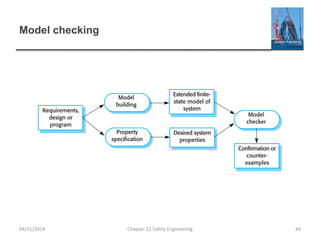


















This document provides an overview of safety engineering concepts and processes. It discusses safety-critical systems and the importance of considering software safety. Safety is defined as a system's ability to operate without danger of injury or damage. Key concepts covered include safety requirements, hazard identification and analysis, risk assessment and reduction strategies, and safety engineering processes. Safety-critical systems must be designed and developed following strict processes to ensure all hazards are identified and mitigated.























































































