Downloaded 366 times







![(b) has a finite variance that is time-invariant;
and
(c) has a theoretical correlogram that diminishes
as the lag length increases.
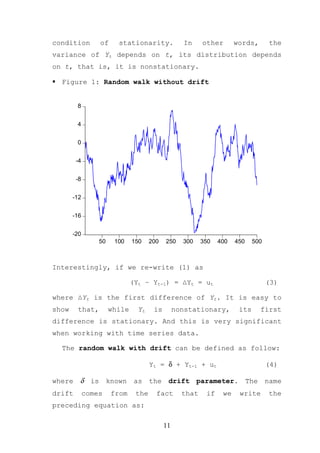
In its simplest terms a time series Yt is said to be
weakly stationary (hereafter refer to stationary) if:
(a) Mean: E(Yt) = µ (constant for all t);
(b) Variance: Var(Yt) = E(Yt-µ)2 = σ2 (constant for
all t); and
(c) Covariance: Cov(Yt,Yt+k) = γk = E[(Yt-µ)(Yt+k-µ)]
where γk, covariance (or autocovariance) at lag k,is
the covariance between the values of Yt and Yt+k, that
is, between two Y values k periods apart. If k = 0, we
obtain γ0, which is simply the variance of Y (=σ2); if
k = 1, γ1 is the covariance between two adjacent values
of Y.
Suppose we shift the origin of Y from Yt to Yt+m
(say, from the first quarter of 1970 to the first
quarter of 1975 for our GDP data). Now, if Yt is to be
stationary, the mean, variance, and autocovariance of
Yt+m must be the same as those of Yt. In short, if a
time series is stationary, its mean, variance, and
autocovariance (at various lags) remain the same no
matter at what point we measure them; that is, they
are time invariant. According to Gujarati (2003), such
time series will tend to return to its mean (called
mean reversion) and fluctuations around this mean
(measured by its variance) will have a broadly
constant amplitude.
7](https://image.slidesharecdn.com/causalitymodels-121015014433-phpapp01/85/Causality-models-7-320.jpg)
















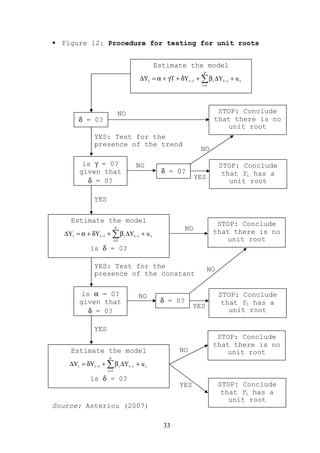
![model and moving to the next model. This procedure is
illustrated in Figure 12. It needs to be stressed here
that, although useful, this procedure is not designed
to be applied in a mechanical fashion. Plotting the
data and observing the graph is sometimes very useful
because it can clearly indicate the presence or not of
deterministic regressors. However, this procedure is
the most sensible way to test for unit roots when the
form of the data-generating process is unknown.
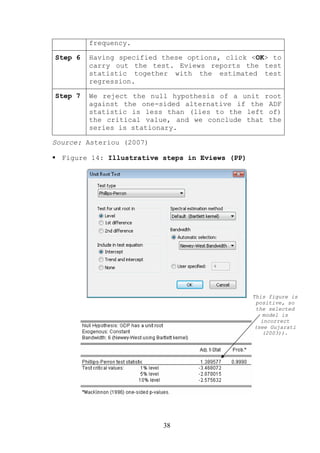
In practical studies, researchers use both the ADF
and the Phillips-Perron (PP) tests21. Because the
distribution theory that supporting the Dickey-Fuller
tests is based on the assumption of random error terms
[iid(0,σ2)], when using the ADF methodology we have to
make sure that the error terms are uncorrelated and
they really have a constant variance. Phillips and
Perron (1988) developed a generalization of the ADF
test procedure that allows for fairly mild assumptions
concerning the distribution of errors. The regression
for the PP test is similar to equation (15).
∆Yt = α + δYt-1 + et (20)
While the ADF test corrects for higher order serial
correlation by adding lagged differenced terms on the
right-hand side of the test equation, the PP test
makes a correction to the t statistic of the
coefficient δ from the AR(1) regression to account for
the serial correlation in et.
21
Eviews has a specific command for these tests.
32](https://image.slidesharecdn.com/causalitymodels-121015014433-phpapp01/85/Causality-models-32-320.jpg)

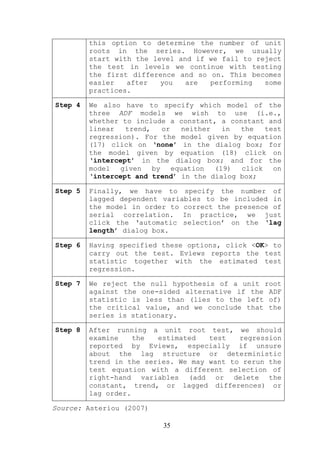
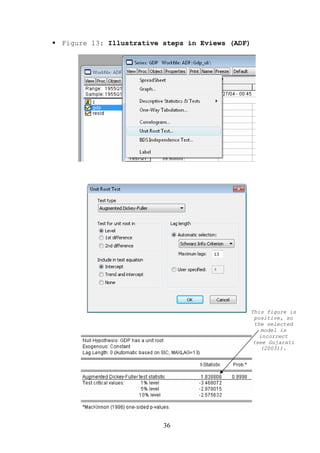


![where we assume that both Yt and Xt are stationary and
uyt and uxt are uncorrelated white-noise error terms.
These equations are not reduced-form equations since
Yt has a contemporaneous impact on Xt, and Xt has a
contemporaneous impact on Yt. The illustrative example
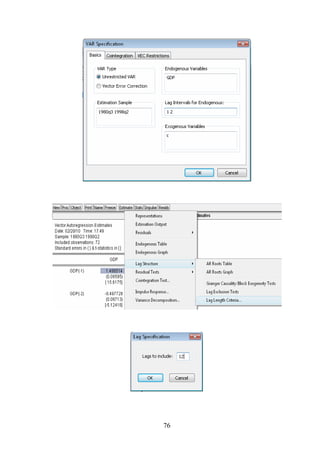
is presented in Figure 15 (open the file VAR.wf1).
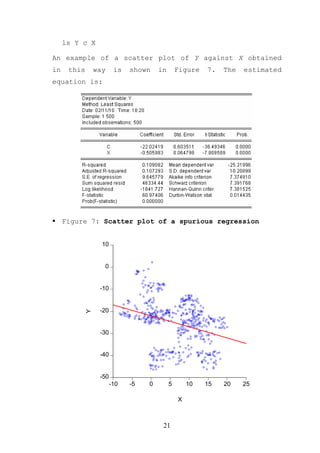
Figure 15: An illustration of VAR in Eviews
Vector Autoregression Estimates
Date: 02/20/10 Time: 15:46
Sample (adjusted): 1975Q3 1997Q4
Included observations: 90 after adjustments
Standard errors in ( ) & t-statistics in [ ]
GDP M2
GDP(-1) 1.230362 -0.071108
(0.10485) (0.09919)
[11.7342] [-0.71691]
GDP(-2) -0.248704 0.069167
(0.10283) (0.09728)
[-2.41850] [0.71103]
M2(-1) 0.142726 1.208942
(0.11304) (0.10693)
40](https://image.slidesharecdn.com/causalitymodels-121015014433-phpapp01/85/Causality-models-40-320.jpg)
![[1.26267] [11.3063]
M2(-2) -0.087270 -0.206244
(0.11599) (0.10972)
[-0.75237] [-1.87964]
C 4.339620 8.659425
(3.02420) (2.86077)
[1.43497] [3.02696]
R-squared 0.999797 0.998967
Adj. R-squared 0.999787 0.998918
Sum sq. resids 6000.811 5369.752
S.E. equation 8.402248 7.948179
F-statistic 104555.2 20543.89
Log likelihood -316.6973 -311.6972
Akaike AIC 7.148828 7.037716
Schwarz SC 7.287707 7.176594
Mean dependent 967.0556 509.1067
S.D. dependent 576.0331 241.6398
Determinant resid covariance 4459.738
Determinant resid covariance 3977.976
Log likelihood -628.3927
Akaike information criterion 14.18650
Schwarz criterion 14.46426
According to Asteriou (2007), the VAR model has some
good characteristics. First, it is very simple because
we do not have to worry about which variables are
endogenous or exogenous. Second, estimation is very
simple as well, in the sense that each equation can be
estimated with the usual OLS method separately. Third,
forecasts obtained from VAR models are in most cases
better than those obtained from the far more complex
simultaneous equation models (see Mahmoud, 1984;
McNees, 1986). Besides forecasting purposes, VAR
models also provide framework for causality tests,
which will be presented shortly in the next section.
However, on the other hand the VAR models have faced
severe criticism on various different points.
41](https://image.slidesharecdn.com/causalitymodels-121015014433-phpapp01/85/Causality-models-41-320.jpg)









![In this model24, the parameter γ0 denotes the short-
run reaction of Yt after a change in Xt. The long-run
effect is given when the model is in equilibrium
where:
Yt* = β 0 + β1 X *
t (32)
and for simplicity, we assume that:
X * = X t = X t −1 = ... = X t − p
t (33)
From (31), (32), and (33), we have:
Yt* = a 0 + a 1Yt* + γ 0 X * + γ 1X * + u t
t t
Yt* (1 − a 1 ) = a 0 + ( γ 0 + γ 1 )X * + u t
t
a0 γ + γ1 *
Yt* = + 0 Xt + u t
1 − a1 1 − a1
Yt* = β 0 + β1 X * + u t
t (34)
Therefore, the long-run elasticity between Y and X is
captured by β1=(γ0+γ1)/(1-a1). It is noted that, we need
to make the assumption that a1 < 1 (why?) in order
that the short-run model (31) converges to a long-run
solution.
The ECM can be rewritten as follows:
∆Yt = γ0∆Xt – (1-a)[Yt-1 – β0 – β1Xt-1] + ut (35)
∆Yt = γ0∆Xt – π[Yt-1 – β0 – β1Xt-1] + ut (36)
(please show that the ECM model (35) is the same as
the original model (31)?)
24
We can easily expand this model to a more general case for large numbers of lagged terms.
52](https://image.slidesharecdn.com/causalitymodels-121015014433-phpapp01/85/Causality-models-52-320.jpg)







![mean that the variables in the model might form
several equilibrium relationships. In general, for n
number of variables, we can have only up to n-1 co-
integrating vectors.
Having n > 2 and assuming that only one co-
integrating relationship exists, where there are
actually more than one, is a very serious problem that
cannot be resolved by the EG single-equation approach.
Therefore, an alternative to the EG approach is needed
and this is the Johansen approach26 for multiple
equations.
In order to present this approach, it is useful to
extend the single-equation error correction model to a
multivariate one. Let’s assume that we have three
variables, Yt, Xt and Wt, which can all be endogenous,
i.e., we have that (using matrix notation for Zt =
[Yt,Xt,Wt])
Zt = A1Zt-1 + A2Zt-2 + … + AkZt-k + ut (37)
which is comparable to the single-equation dynamic
model for two variables Yt and Xt given in (31). Thus,
it can be reformulated in a vector error correction
model (VECM) as follows:
∆Zt = Γ1∆Zt-1 + Γ2∆Zt-2 + … + Γk-1∆Zt-k-1 + ΠZt-1 + ut (38)
where the matrix Π contains information regarding the
long-run relationships. We can decompose Π = αβ’ where
α will include the speed of adjustment to equilibrium
26
For clearer, please read Li, X. (2001) ‘Government Revenue, Government Expenditure, and Temporal
Causality: Evidence from China’, Applied Economics, Vol.33, pp.485-497.
60](https://image.slidesharecdn.com/causalitymodels-121015014433-phpapp01/85/Causality-models-60-320.jpg)
![coefficients, while β’ will be the long-run matrix of
coefficients.
Therefore, the β’Zt-1 term is equivalent to the error
correction term (Yt-1 – β0 – β1Xt-1) in the single-
equation case, except that now β’Zt-1 contains up to (n
– 1) vectors in a multivariate framework.
For simplicity, we assume that k = 2, so that we
have only two lagged terms, and the model is then the
following:
∆Yt ∆Yt −1 Yt −1
∆X t = Γ1 ∆X t −1 + Π X t −1 + e t (38)
∆W W
∆Wt t −1 t −1
or
∆Yt ∆Yt −1 α11 α 12 Y
β11 β 21 β 31 t −1
∆X t = Γ1 ∆X t −1 + α 21 α 22
X t −1 + e t
(39)
∆W ∆W α α β12 β 22 β 32 W
t t −1 31 32 t −1
Let us now analyse only the error correction part of
the first equation (i.e., for ∆Yt on the left-hand
side) which gives:
Π1Zt-1 = ([α11β11 + α12β12][α11β21 + α12β22]
Yt −1
[α11β31 + α12β32]) X t −1 (40)
W
t −1
Equation (40) can be rewritten as:
Π1Zt-1 = α11(β11Yt-1 + β21Xt-1 + β31Wt-1) +
α12(β12Yt-1 + β22Xt-1 + β32Wt-1) (41)
61](https://image.slidesharecdn.com/causalitymodels-121015014433-phpapp01/85/Causality-models-61-320.jpg)






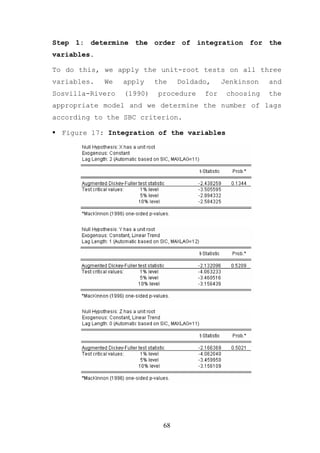



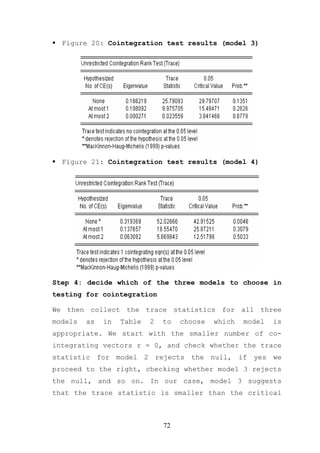














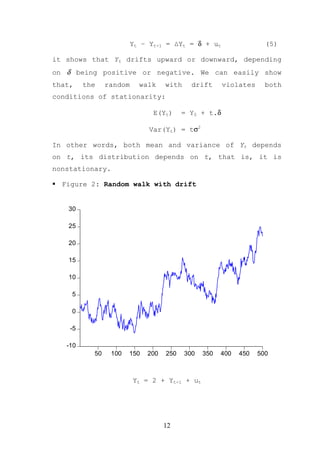
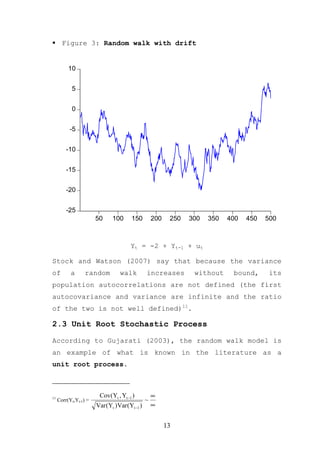
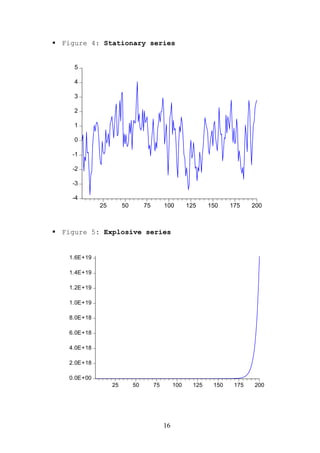
The document provides an overview of time series econometrics concepts including: 1) Time series econometrics analyzes the dynamic structure and interrelationships over time in economic data. It examines stationary and non-stationary stochastic processes. 2) A time series is stationary if its mean, variance, and autocovariance remain constant over time. A random walk process is a type of non-stationary process where the variable fluctuates around a stochastic trend. 3) The document discusses key time series econometrics models and techniques including unit root tests, vector autoregressive models, causality tests, cointegration, and error correction models.





























































