





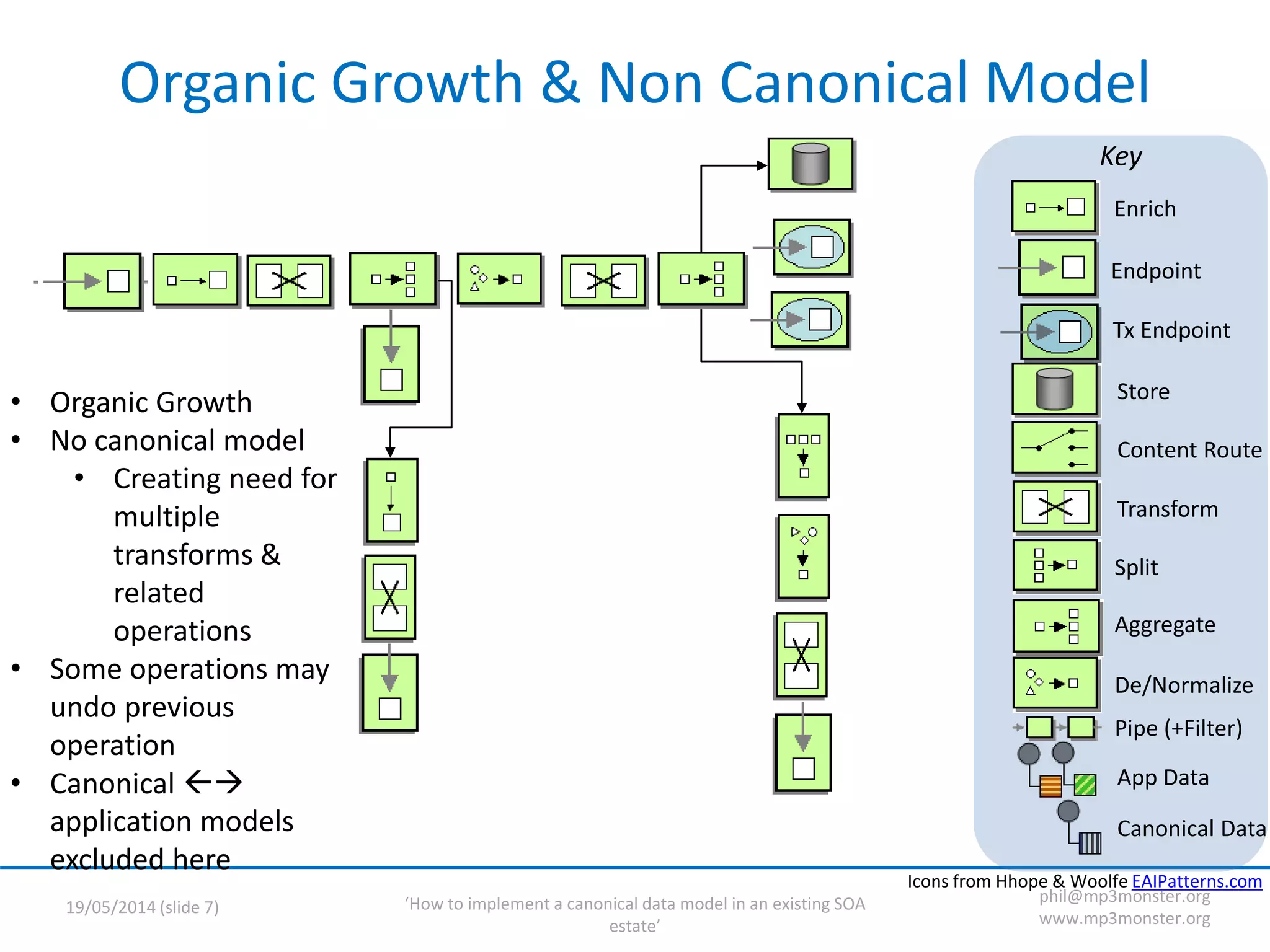
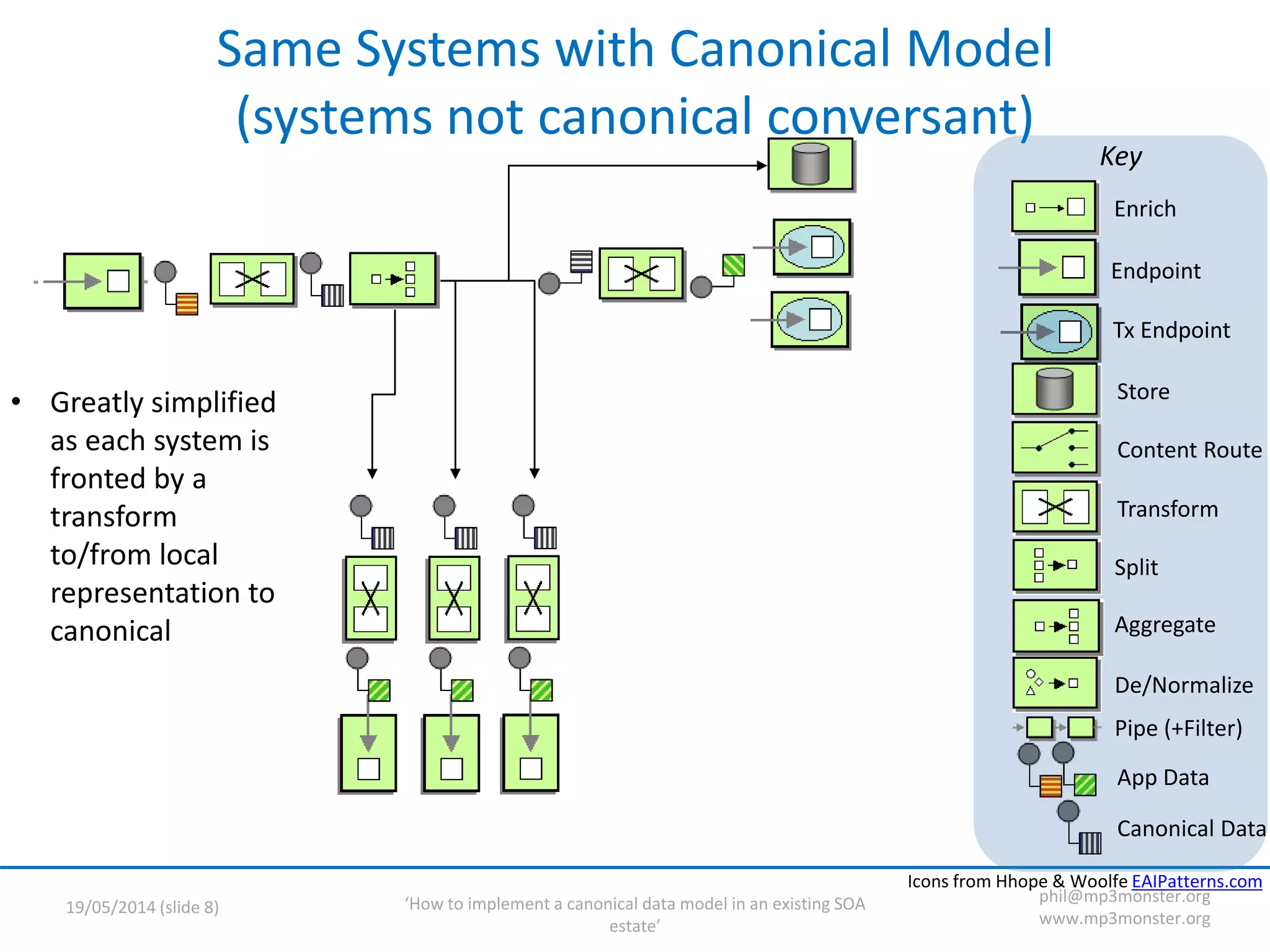
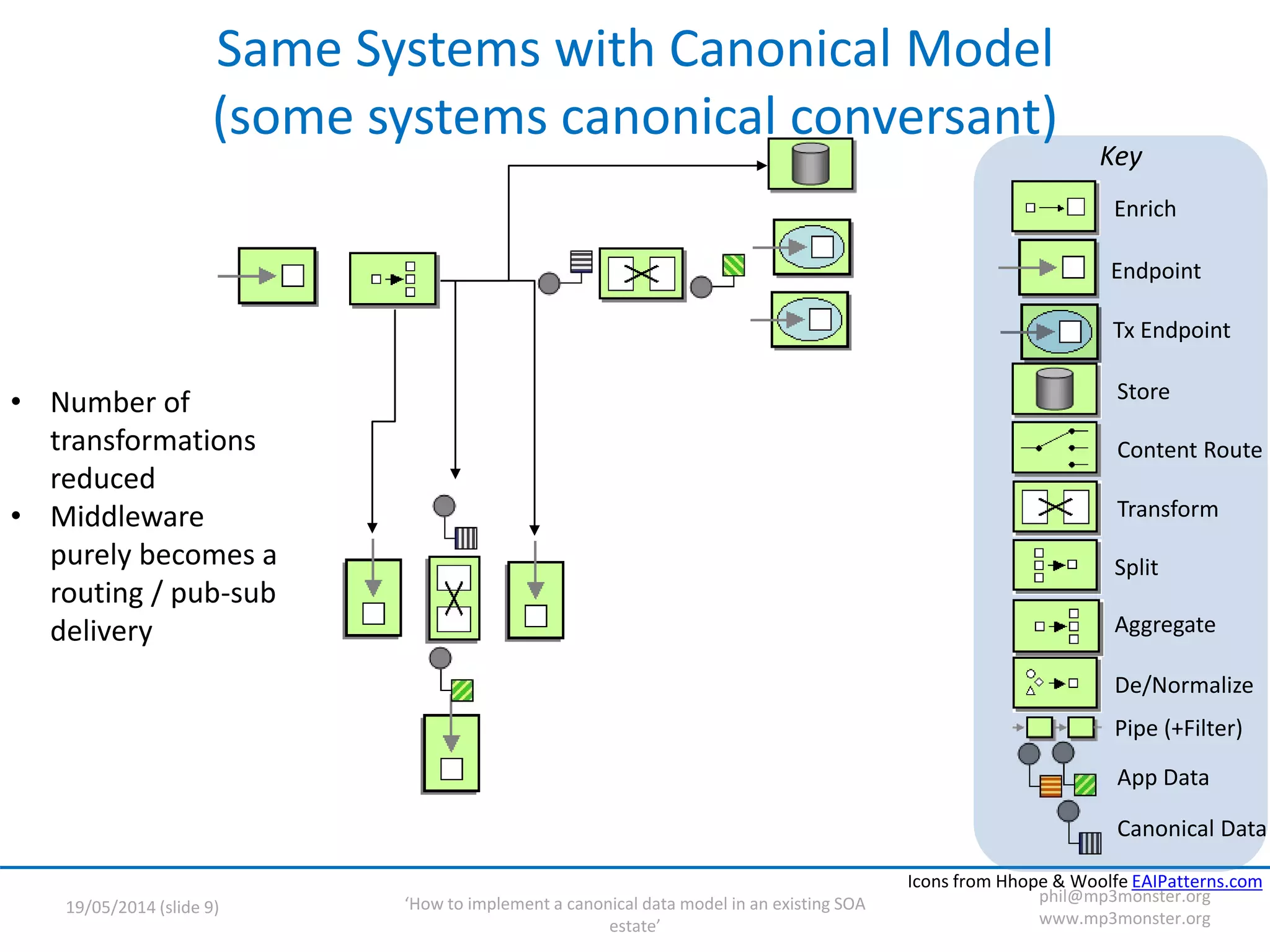











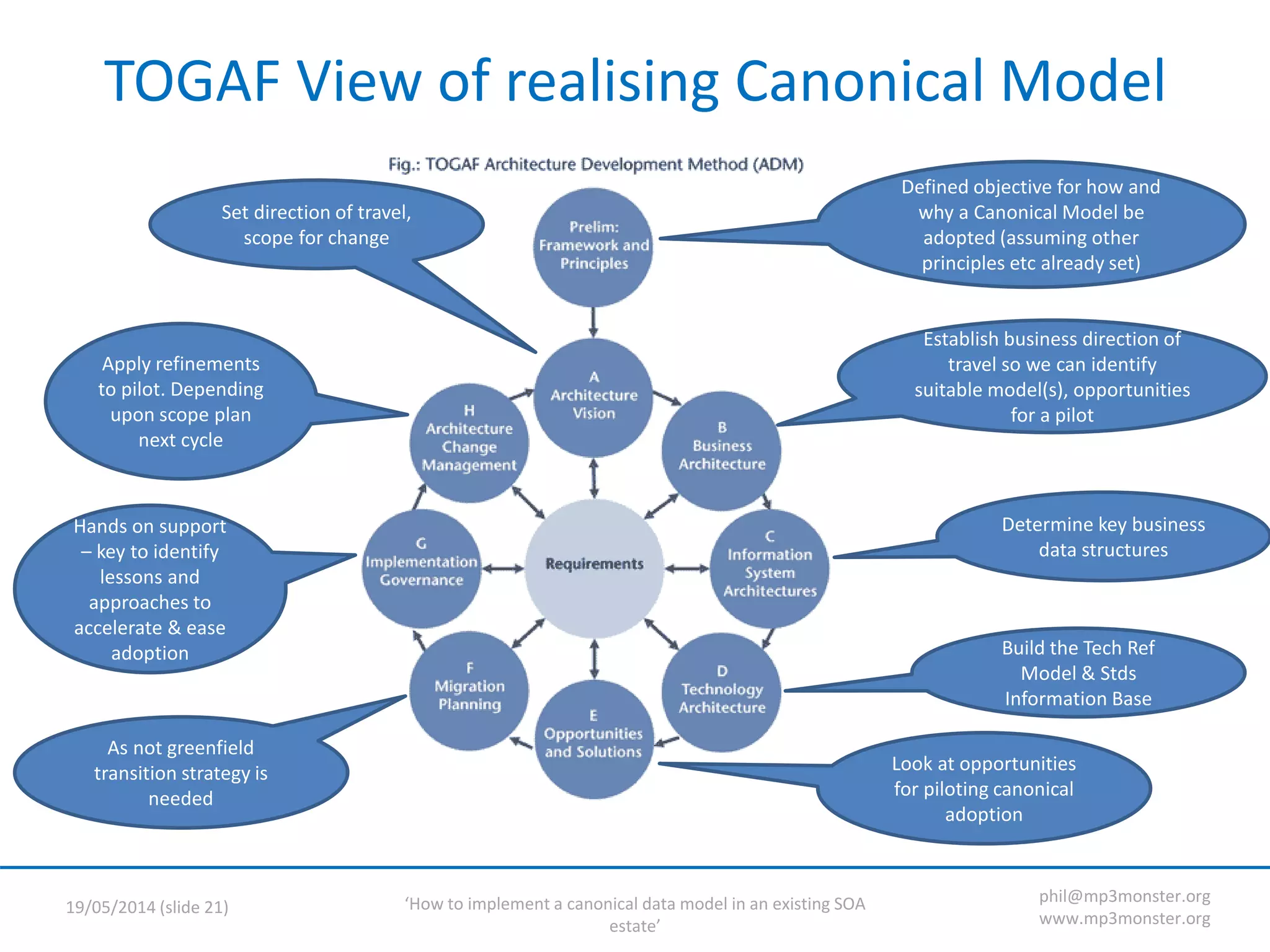
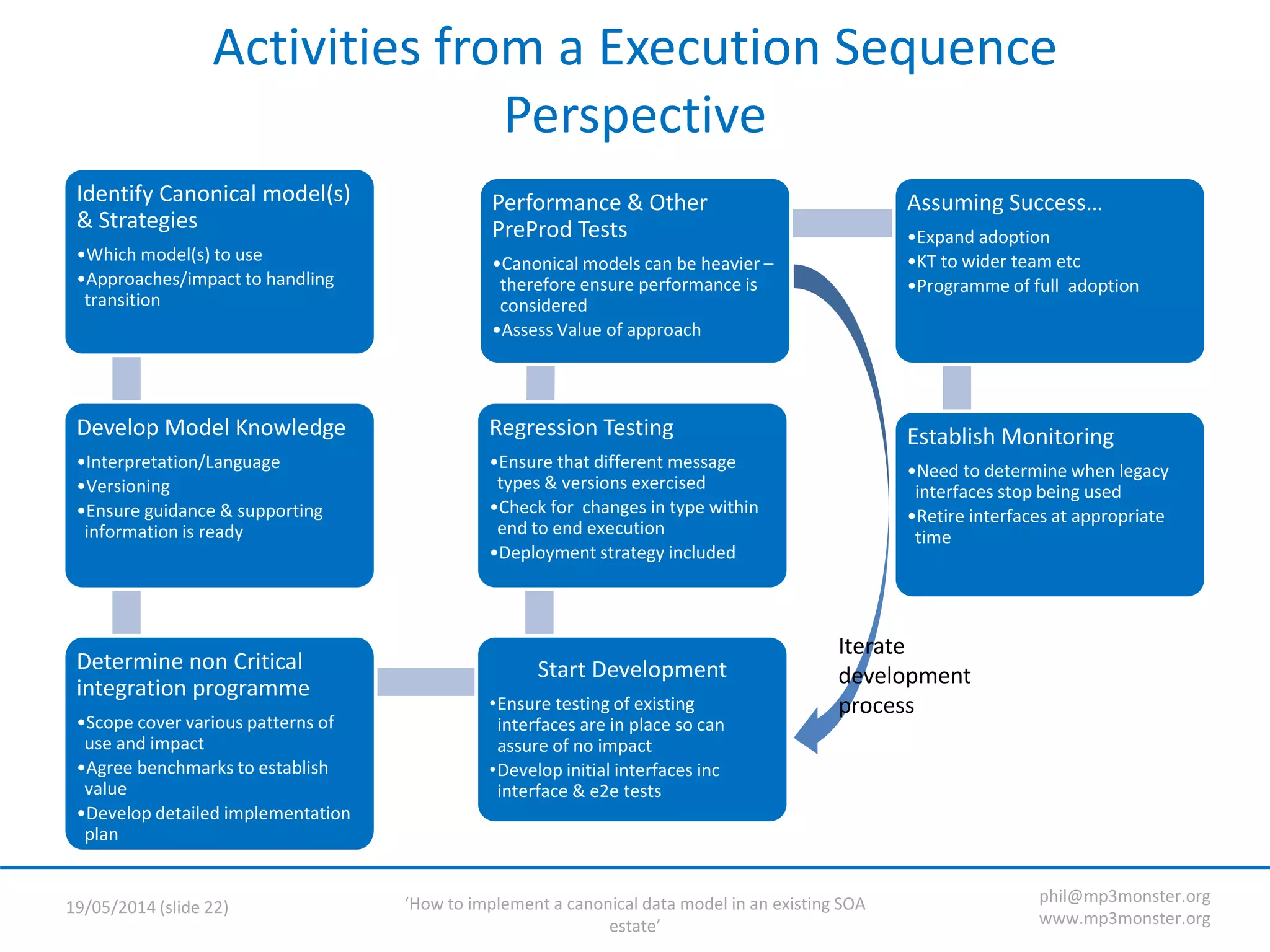




This document discusses strategies for implementing a canonical data model in an existing SOA (service-oriented architecture) environment. It covers assumptions about the current SOA estate, the value of adopting a canonical model, technical strategies needed like interface versioning and transition states, and challenges around abstraction versus endpoint needs. The key points are that a canonical model provides semantic and structural consistency across services, reduces design effort, and enables more information-rich integrations, but the transition requires addressing issues like supporting multiple interface versions and legacy systems.























































































