























![{
"service": {
"name": "redis",
"tags": ["slave"],
"port": 8000,
"check": {
"script": "/usr/local/bin/check_redis.py",
"interval": "10s"
}
}
}
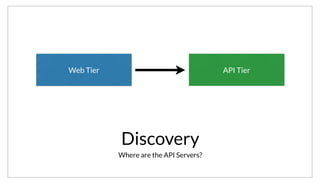
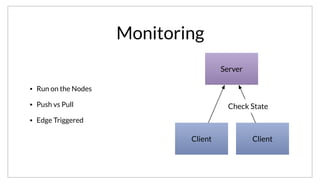
As an example, here is a simple JSON registration for a redis service. We are declaring the service name, providing a tag, indicating its a ‘slave’ node, the
port and lastly a health check. We’ve provided a nagios compatible check that is run on a 10 second interval to check health.](https://image.slidesharecdn.com/untitled-150309081332-conversion-gate01/85/Consul-Service-oriented-at-Scale-34-320.jpg)







![Watchers
$ consul watch -type nodes
[
{
"Node": "foo",
"Address": "10.1.10.38"
}
]
$ consul watch -type nodes /usr/bin/setup_dns.sh
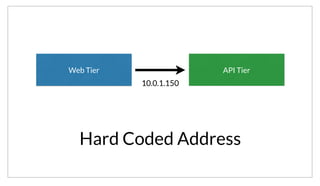
As an example, a watcher can be setup to watch for changes to the nodes list. Any time a new node joins or leaves the cluster, the handler will be invoked.
If we invoke it without a handler, we just get the current result set. We can also specify a handler which gets updates over stdin and is free to react in any
way. For example, we could update our BIND configuration.](https://image.slidesharecdn.com/untitled-150309081332-conversion-gate01/85/Consul-Service-oriented-at-Scale-48-320.jpg)
![Events
$ consul watch -type event -name test cat
[{“ID”:”8cf8a891-b08b-6286-8f68-44c6930cafe0”,
“Name":"test",
“Payload":"c2FtcGxlLXBheWxvYWQ=",
“NodeFilter":"",
“ServiceFilter":"redis",
“TagFilter":"",
“Version":1,
"LTime":4}]
$ consul event -service redis -name test sample-payload
Event ID: 8cf8a891-b08b-6286-8f68-44c6930cafe0
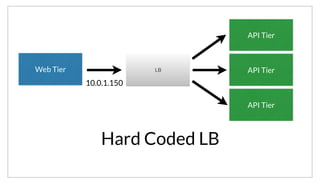
As an example, here we are firing an event named “test”, targeting the “redis” service and providing a “sample-payload”. If we had been running a
watcher, it could filter to only “test” events. Here we can see the handler receives the event, with the base64 encoded payload.](https://image.slidesharecdn.com/untitled-150309081332-conversion-gate01/85/Consul-Service-oriented-at-Scale-50-320.jpg)

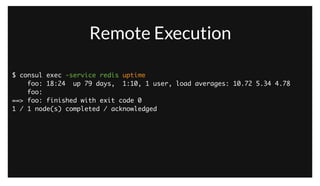






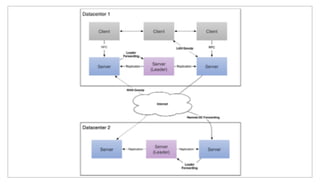










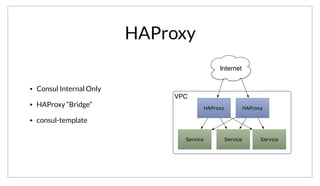




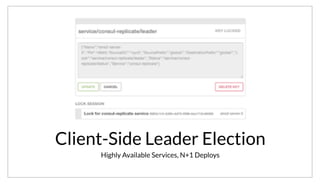

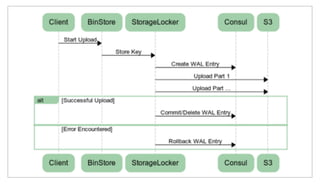














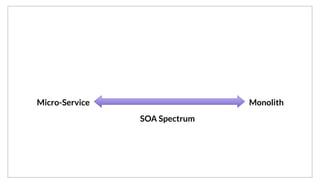
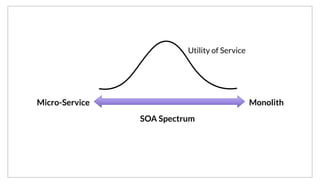
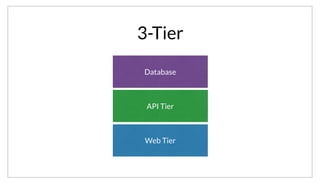
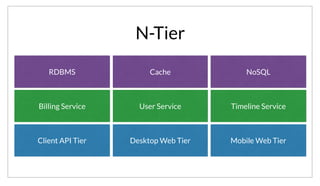
The document discusses the purpose and benefits of service-oriented architecture (SOA) at scale, emphasizing the importance of decentralized services and their configurations. It introduces Consul, a tool designed to tackle challenges in service discovery, health checks, configuration, and orchestration, offering features like a hierarchical key/value store and an event system. Overall, the goal of both SOA and Consul is to promote faster development, better scalability, and easier management of complex service ecosystems.










































































































