The document discusses a proposed "Cache as a Service" (CaaS) model for cloud computing. It aims to improve I/O performance and cost efficiency for applications with heavy I/O activities by providing remote memory caching as an optional cloud service. The key points are:
1) Current cloud services have limited caching capabilities that hinder performance for I/O intensive applications.
2) The CaaS model proposes dynamically allocating a large pool of remote memory for caching disk data, providing performance gains with minimal extra costs for users.
3) Experiments show the CaaS model improves server consolidation for providers through better performance, increasing profits while keeping user costs similar to no caching.
![Cashing in on the Cache in the Cloud
Hyuck Han, Young Choon Lee, Member, IEEE, Woong Shin, Hyungsoo Jung,
Heon Y. Yeom, Member, IEEE, and Albert Y. Zomaya, Fellow, IEEE
Abstract—Over the past decades, caching has become the key technology used for bridging the performance gap across memory
hierarchies via temporal or spatial localities; in particular, the effect is prominent in disk storage systems. Applications that involve
heavy I/O activities, which are common in the cloud, probably benefit the most from caching. The use of local volatile memory as cache
might be a natural alternative, but many well-known restrictions, such as capacity and the utilization of host machines, hinder its
effective use. In addition to technical challenges, providing cache services in clouds encounters a major practical issue (quality of
service or service level agreement issue) of pricing. Currently, (public) cloud users are limited to a small set of uniform and coarse-
grained service offerings, such as High-Memory and High-CPU in Amazon EC2. In this paper, we present the cache as a service
(CaaS) model as an optional service to typical infrastructure service offerings. Specifically, the cloud provider sets aside a large pool of
memory that can be dynamically partitioned and allocated to standard infrastructure services as disk cache. We first investigate the
feasibility of providing CaaS with the proof-of-concept elastic cache system (using dedicated remote memory servers) built and
validated on the actual system, and practical benefits of CaaS for both users and providers (i.e., performance and profit, respectively)
are thoroughly studied with a novel pricing scheme. Our CaaS model helps to leverage the cloud economy greatly in that 1) the extra
user cost for I/O performance gain is minimal if ever exists, and 2) the provider’s profit increases due to improvements in server
consolidation resulting from that performance gain. Through extensive experiments with eight resource allocation strategies, we
demonstrate that our CaaS model can be a promising cost-efficient solution for both users and providers.
Index Terms—Cloud computing, cache as a service, remote memory, cost efficiency.
Ç
1 INTRODUCTION
THE resource abundance (redundancy) in many large
data centers is increasingly engineered to offer the spare
capacity as a service like electricity, water, and gas. For
example, public cloud service providers like Amazon Web
Services virtualize resources, such as processors, storage,
and network devices, and offer them as services on
demand, i.e., infrastructure as a service (IaaS) which is the
main focus of this paper. A virtual machine (VM) is a
typical instance of IaaS. Although a VM acts as an isolated
computing platform which is capable of running multiple
applications, it is assumed in this study to be solely
dedicated to a single application, and thus, we use the
expressions VM and application interchangeably hereafter.
Cloud services as virtualized entities are essentially elastic
making an illusion of “unlimited” resource capacity. This
elasticity with utility computing (i.e., pay-as-you-go pri-
cing) inherently brings cost effectiveness that is the primary
driving force behind the cloud.
However, putting a higher priority on cost efficiency than
cost effectiveness might be more beneficial to both the user
and the provider. Cost efficiency can be characterized by
having the temporal aspect as priority, which can translate to
the cost to performance ratio from the user’s perspective and
improvement in resource utilization from the provider’s
perspective. This characteristic is reflected in the present
economics of the cloud to a certain degree [1]. However, the
conflicting nature of these perspectives (or objectives) and
their resolution remain an open issue for the cloud.
In this paper, we investigate how cost efficiency in the
cloud can be further improved, particularly with applica-
tions that involve heavy I/O activities; hence, I/O-intensive
applications. They account for the majority of applications
deployed on today’s cloud platforms. Clearly, their perfor-
mance is significantly impacted on by how fast their I/O
activities are processed. Here, caching plays a crucial role in
improving their performance.
Over the past decades, caching has become the key
technology in bridging the performance gap across memory
hierarchies via temporal or spatial localities; in particular,
the effect is prominent in disk storage systems. Currently, the
effective use of cache for I/O-intensive applications in the
cloud is limited for both architectural and practical reasons.
Due to essentially the shared nature of some resources like
disks (not performance isolatable), the virtualization over-
head with these resources is not negligible and it further
worsens the disk I/O performance. Thus, low disk I/O
performance is one of the major challenges encountered by
most infrastructure services as in Amazon’s relational
database service, which provisions virtual servers with
database servers. At present, the performance issue of I/O-
intensive applications is mainly dealt with by using high-
performance (HP) servers with large amounts of memory,
leaving it as the user’s responsibility.
To overcome low disk I/O performance, there have been
extensive studies on memory-based cache systems [2], [3],
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 23, NO. 8, AUGUST 2012 1387
. H. Han, W. Shin, and H.Y. Yeom are with the Distributed Computing
Systems Laboratory, Department of Computer Science and Engineering,
Seoul National University, Bldg 302, 1 Gwanak-ro, Gwanak-gu, Seoul
151-744, Korea. E-mail: {hhyuck, wshin, yeom}@dcslab.snu.ac.kr.
. Y.C. Lee, H. Jung, and A.Y. Zomaya are with the Centre for Distributed
and High Performance Computing, School of Information Technologies,
University of Sydney, NSW 2006, Australia.
E-mail: {young.lee, hyungsoo.jung, zomaya}@sydney.edu.au.
Manuscript received 9 May 2011; revised 23 Oct. 2011; accepted 26 Oct.
2011; published online 30 Nov. 2011.
Recommended for acceptance by K. Li.
For information on obtaining reprints of this article, please send e-mail to:
tpds@computer.org, and reference IEEECS Log Number TPDS-2011-05-0291.
Digital Object Identifier no. 10.1109/TPDS.2011.297.
1045-9219/12/$31.00 ß 2012 IEEE Published by the IEEE Computer Society](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-1-320.jpg)
![Cashing in on the Cache in the Cloud
Hyuck Han, Young Choon Lee, Member, IEEE, Woong Shin, Hyungsoo Jung,
Heon Y. Yeom, Member, IEEE, and Albert Y. Zomaya, Fellow, IEEE
Abstract—Over the past decades, caching has become the key technology used for bridging the performance gap across memory
hierarchies via temporal or spatial localities; in particular, the effect is prominent in disk storage systems. Applications that involve
heavy I/O activities, which are common in the cloud, probably benefit the most from caching. The use of local volatile memory as cache
might be a natural alternative, but many well-known restrictions, such as capacity and the utilization of host machines, hinder its
effective use. In addition to technical challenges, providing cache services in clouds encounters a major practical issue (quality of
service or service level agreement issue) of pricing. Currently, (public) cloud users are limited to a small set of uniform and coarse-
grained service offerings, such as High-Memory and High-CPU in Amazon EC2. In this paper, we present the cache as a service
(CaaS) model as an optional service to typical infrastructure service offerings. Specifically, the cloud provider sets aside a large pool of
memory that can be dynamically partitioned and allocated to standard infrastructure services as disk cache. We first investigate the
feasibility of providing CaaS with the proof-of-concept elastic cache system (using dedicated remote memory servers) built and
validated on the actual system, and practical benefits of CaaS for both users and providers (i.e., performance and profit, respectively)
are thoroughly studied with a novel pricing scheme. Our CaaS model helps to leverage the cloud economy greatly in that 1) the extra
user cost for I/O performance gain is minimal if ever exists, and 2) the provider’s profit increases due to improvements in server
consolidation resulting from that performance gain. Through extensive experiments with eight resource allocation strategies, we
demonstrate that our CaaS model can be a promising cost-efficient solution for both users and providers.
Index Terms—Cloud computing, cache as a service, remote memory, cost efficiency.
Ç
1 INTRODUCTION
THE resource abundance (redundancy) in many large
data centers is increasingly engineered to offer the spare
capacity as a service like electricity, water, and gas. For
example, public cloud service providers like Amazon Web
Services virtualize resources, such as processors, storage,
and network devices, and offer them as services on
demand, i.e., infrastructure as a service (IaaS) which is the
main focus of this paper. A virtual machine (VM) is a
typical instance of IaaS. Although a VM acts as an isolated
computing platform which is capable of running multiple
applications, it is assumed in this study to be solely
dedicated to a single application, and thus, we use the
expressions VM and application interchangeably hereafter.
Cloud services as virtualized entities are essentially elastic
making an illusion of “unlimited” resource capacity. This
elasticity with utility computing (i.e., pay-as-you-go pri-
cing) inherently brings cost effectiveness that is the primary
driving force behind the cloud.
However, putting a higher priority on cost efficiency than
cost effectiveness might be more beneficial to both the user
and the provider. Cost efficiency can be characterized by
having the temporal aspect as priority, which can translate to
the cost to performance ratio from the user’s perspective and
improvement in resource utilization from the provider’s
perspective. This characteristic is reflected in the present
economics of the cloud to a certain degree [1]. However, the
conflicting nature of these perspectives (or objectives) and
their resolution remain an open issue for the cloud.
In this paper, we investigate how cost efficiency in the
cloud can be further improved, particularly with applica-
tions that involve heavy I/O activities; hence, I/O-intensive
applications. They account for the majority of applications
deployed on today’s cloud platforms. Clearly, their perfor-
mance is significantly impacted on by how fast their I/O
activities are processed. Here, caching plays a crucial role in
improving their performance.
Over the past decades, caching has become the key
technology in bridging the performance gap across memory
hierarchies via temporal or spatial localities; in particular,
the effect is prominent in disk storage systems. Currently, the
effective use of cache for I/O-intensive applications in the
cloud is limited for both architectural and practical reasons.
Due to essentially the shared nature of some resources like
disks (not performance isolatable), the virtualization over-
head with these resources is not negligible and it further
worsens the disk I/O performance. Thus, low disk I/O
performance is one of the major challenges encountered by
most infrastructure services as in Amazon’s relational
database service, which provisions virtual servers with
database servers. At present, the performance issue of I/O-
intensive applications is mainly dealt with by using high-
performance (HP) servers with large amounts of memory,
leaving it as the user’s responsibility.
To overcome low disk I/O performance, there have been
extensive studies on memory-based cache systems [2], [3],
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 23, NO. 8, AUGUST 2012 1387
. H. Han, W. Shin, and H.Y. Yeom are with the Distributed Computing
Systems Laboratory, Department of Computer Science and Engineering,
Seoul National University, Bldg 302, 1 Gwanak-ro, Gwanak-gu, Seoul
151-744, Korea. E-mail: {hhyuck, wshin, yeom}@dcslab.snu.ac.kr.
. Y.C. Lee, H. Jung, and A.Y. Zomaya are with the Centre for Distributed
and High Performance Computing, School of Information Technologies,
University of Sydney, NSW 2006, Australia.
E-mail: {young.lee, hyungsoo.jung, zomaya}@sydney.edu.au.
Manuscript received 9 May 2011; revised 23 Oct. 2011; accepted 26 Oct.
2011; published online 30 Nov. 2011.
Recommended for acceptance by K. Li.
For information on obtaining reprints of this article, please send e-mail to:
tpds@computer.org, and reference IEEECS Log Number TPDS-2011-05-0291.
Digital Object Identifier no. 10.1109/TPDS.2011.297.
1045-9219/12/$31.00 ß 2012 IEEE Published by the IEEE Computer Society](https://image.slidesharecdn.com/han2012-220323115454/75/caching2012-pdf-1-2048.jpg)
![[4], [5]. The main advantage of memory is that its access
time is several orders of magnitude faster than that of disk
storage. Clearly, disk-based information systems with a
memory-based cache can greatly outperform those without
cache. A natural design choice in building a disk-based
information system with ample cache capacity is to exploit a
single, expensive, large memory computer system. This
simple design—using local volatile memory as cache (LM
cache)—costs a great deal, and may not be practically
feasible in the existing cloud services due to various factors
including capacity and the utilization of host machines.
In this paper, we address the issue of disk I/O
performance in the context of caching in the cloud and
present a cache as a service (CaaS) model as an additional
service to IaaS. For example, a user is able to simply specify
more cache memory as an additional requirement to an IaaS
instance with the minimum computational capacity (e.g.,
micro/small instance in Amazon EC2) instead of an instance
with large amount of memory (high-memory instance in
Amazon EC2). The key contribution in this work is that our
cache service model much augments cost efficiency and
elasticity of the cloud from the perspective of both users and
providers. CaaS as an additional service (provided mostly in
separate cache servers) gives the provider an opportunity to
reduce both capital and operating costs using a fewer
number of active physical machines for IaaS; and this can
justify the cost of cache servers in our model. The user also
benefits from CaaS in terms of application performance with
minimal extra cost; besides, caching is enabled in a user
transparent manner and cache capacity is not limited to local
memory. The specific contributions of this paper are listed as
follows: first, we design and implement an elastic cache
system, as the architectural foundation of CaaS, with remote
memory (RM) servers or solid state drives (SSDs); this system
is designed to be pluggable and file system independent. By
incorporating our software component in existing operating
systems, we can configure various settings of storage
hierarchies without any modification of operating systems
and user applications. Currently, many users exploit
memory of distributed machines (e.g., memcached) by
integration of cache system and users’ applications in an
application level or a file-system level. In such cases, users or
administrators should prepare cache-enabled versions for
users’ application or file system to deliver a cache benefit.
Hence, file system transparency and application transpar-
ency are some of the key issues since there is a great diversity
of applications or file systems in the cloud computing era.
Second, we devise a service model with a pricing scheme,
as the economic foundation of CaaS, which effectively
balances conflicting objectives between the user and the
provider, i.e., performance versus profit. The rationale
behind our pricing scheme in CaaS is that the scheme
ensures that the user gains I/O performance improvement
with little or no extra cost and at the same time it enables the
provider to get profit increases by improving resource
utilization, i.e., better service (VM) consolidation. Specifi-
cally, the user cost for a particular application increases
proportionally to the performance gain and thus, the user’s
cost eventually remains similar to that without CaaS.
Besides, performance gains that the user get with CaaS has
further cost efficiency implications if the user is a business
service provider who rents IaaS instances and offers value-
added services to other users (end users).
Finally, we apply four well-known resource allocation
algorithms (first-fit (FF), next-fit (NF), best-fit (BF), and
worst-fit (WF)) and develop their variants with live VM
migration to demonstrate the efficacy of CaaS.
Our CaaS model and its components are thoroughly
validated and evaluated through extensive experiments in
both a real system and a simulated environment. Our RM-
based elastic cache system is tested in terms of its
performance and reliability to verify its technical feasibility
and practicality. The complete CaaS model is evaluated
through extensive simulations; and their parameters are
modeled based on preliminary experimental results ob-
tained using the actual system.
The remainder of this paper is organized as follows:
Section 2 reviews the related work about caching and its
impact on I/O performance in the context of cloud
computing. Section 3 overviews and conceptualizes the
CaaS model. Section 4 articulates the architectural design of
our “elastic” cache system. Section 5 describes the service
model with a pricing scheme for CaaS. In Section 6, we
present results of experimental validation for the cache
system and evaluation results for our CaaS model. We then
conclude this paper in Section 7.
2 BACKGROUND AND RELATED WORK
There have been a number of studies conducted to
investigate the issue of I/O performance in virtualized
systems. The focus of these investigations includes I/O
virtualization, cache alternatives and caching mechanisms.
In this section, we describe and discuss notable work
related to our study. What primarily distinguishes ours
from previous studies is the practicality with the virtualiza-
tion support of remote memory access and the incorpora-
tion of service model; hence, cache as a service.
2.1 I/O Virtualization
Virtualization enables resources in physical machines to be
multiplexed and isolated for hosting multiple guest OSes
(VMs). In virtualized environments, I/O between a guest
OS and a hardware device should be coordinated in a safe
and efficient manner. However, I/O virtualization is one of
the severe software obstacles that VMs encounter due to its
performance overhead. Menon et al. [6] tackled virtualized
I/O by performing full functional breakdown with their
profiling tools.
Several studies [7], [8], [9] contribute to the efforts
narrowing the gap between virtual and native performance.
Cherkasova and Gardner [7] and Menon et al. [6] studied I/O
performance in the Xen hypervisor [10] and showed a
significant I/O overhead in Xen’s zero copy with the page-
flipping technique. They proposed that page flipping be
simply replaced by the memcpy function to avoid side effects.
Menon et al. [9] optimized I/O performance by introducing
virtual machine monitor (VMM) superpage and global page
mappings. Liu et al. [8] proposed a new device virtualization
called VMM-bypass that eliminates data transfer between
1388 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 23, NO. 8, AUGUST 2012](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-2-320.jpg)
![the guest OS and the hypervisor by giving the guest device
driver direct access to the device.
With an increasing emphasis on virtualization, many
hardware vendors have started to support hardware-level
features for virtualization. Hardware-level features have
been actively evaluated to seek for near native I/O
performance [11], [12], [13]. Zhang and Dong [11] used Intel
Virtualization Technology architecture to gain better I/O
performance. Santos et al. [14] used devices that support
multiple contexts. Data transfer is offloaded from the
hypervisor to the guest OS by using mapped contexts. Dong
et al. [13] achieved 98 percent of the native performance by
incorporating several hardware features such as device
semantic preservation with input/output memory manage-
ment unit (IOMMU), effective interrupt sharing with
message signaled interrupts, and reusing direct memory
access (DMA) mappings. All these studies focused on
network I/O, where as this work looks at disk I/O.
2.2 Cache Device
Cooperative cache [2] is a kind of RM cache that improves
the performance of networked file systems. In particular, it
is adopted in the Serverless Network File System [3]. It uses
participating clients’ memory regions as a cache. A remote
cache is placed between the memory-based cache of a
requesting client and a server disk. Each participating client
exchanges meta information for the cache with others
periodically. Such a caching scheme is effective where a RM
is faster than a local disk of the requesting client. Jiang et al.
[4] propose advanced buffer management techniques for
cooperative cache. These techniques are based on the
degree of locality. Data that have high (low) locality scores
are placed on a high-level (low-level) cache. Kim et al. [5]
propose a cooperative caching system that is implemented
at the virtualization layer, and the system reduces disk I/O
operations for shared working sets of virtual machines.
Lim et al. [15] proposed two architectures for RM
systems: 1) block-access RM supported in the coherence
hardware (FGRA), and 2) page-swapped RM at the
virtualization layer (PS). In FGRA, a few hardware changes
of memory producers are necessary. On the other hand, PS
implements a RM sharing module in a VMM.
Marazakis et al. [16] utilize remote direct access memory
(RDMA) technology to improve I/O performance in a
storage area network environment. It abstracts disk devices
of remote machines into local block devices. RDMA-
enabled memory regions in remote machines are used as
buffers for write operations. Remote buffers are placed
between virtually addressed pages of requesting clients and
disk devices of remote machines in a storage hierarchy.
These proposals are different from our work in that our
system focuses on improving the I/O performance of a local
disk instead of a remote disk by using RM as a cache.
Recently, SSDs have been used as a file system cache or a
disk device cache in many studies. A hybrid drive [17] is a
NAND flash memory attached disk. Its internal flash
memory is used as the I/O buffer for frequently used data.
It was developed in 2007, but the performance improve-
ment was not significant due to the inadequate size of the
cache [18]. The Drupal data management system [19]
utilizes both SSD and HDD implicitly according to data
usage patterns. It is implemented at the software level. It
uses SSD as a file-system level cache for frequently used
data. Like a hybrid disk, the performance gain of Drupal is
not significant. Lee and Moon [20] showed that SSDs can
benefit transaction processing performance. Makatos et al.
[21] use SSD as a disk cache, and further performance
improvement is gained by employing online compression.
To alleviate performance problems of NAND flash mem-
ory, SSD-based cache systems can adopt striping [22],
parallel I/O [23], NVRAM-based buffer [24], and log-based
I/O [20], and these techniques could significantly help
amortizing the inherent latency of a raw SSD. Nevertheless,
the latency of an SSD is still higher than that of RM.
Ousterhout et al. [25] recently presented a new approach
to data processing, and proposed an architecture, called
RAMCloud that stores data entirely in DRAM of distributed
systems. RAMCloud has performance benefits owing to the
extremely low latency. Thus, it can be a good solution to
overcome the I/O problem of cloud computing. However,
RAMCloud incurs high (operational) cost and high energy
usage. In this study, we use remote memory as a cache
device, which stores only data having high locality, to meet
the balanced point of I/O performance and its cost.
3 CACHE AS A SERVICE: OVERVIEW
The CaaS model consists of two main components: an elastic
cache system as the architectural foundation and a service
model with a pricing scheme as the economic foundation.
The basic system architecture for the elastic cache aims
to use RM, which is exported from dedicated memory
servers (or possibly SSDs). It is not a new caching
algorithm. The elastic cache system can use any of the
existing cache replacement algorithms. Near uniform access
time to RM-based cache is guaranteed by a modern high-
speed network interface that supports RDMA as primitive
operations. Each VM in the cloud accesses the RM servers
via the access interface that is implemented and recognized
as a normal block device driver. Based on this access layer,
VMs utilize RM to provision a necessary amount of cache
memory on demand.
As shown in Fig. 1, a group of dedicated memory servers
exports their local memory to VMs, and exported memory
space can be viewed as an available memory pool. This
memory pool is used as an elastic cache for VMs in the
cloud. For billing purposes, cloud service providers could
employ a lease mechanism to manage the RM pool.
To employ the elastic cache system for the cloud, service
components are essential. The CaaS model consists of two
cache service types (CaaS types) based on whether LM or
RM is allocated with. Since these types are different in their
performance and costs a pricing scheme that incorporates
these characteristics is devised as part of CaaS.
Together, we consider the following scenario. The service
provider sets up a dedicated cache system with a large pool
of memory and provides cache services as an additional
service to IaaS. Now, users have an option to choose a cache
service specifying their cache requirement (cache size) and
that cache service is charged per unit cache size per time.
Specifically, the user first selects an IaaS type (e.g., Standard
small in Amazon EC2) as a base service. The user then
HAN ET AL.: CASHING IN ON THE CACHE IN THE CLOUD 1389](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-3-320.jpg)
![estimates the performance benefit of additional cache to her
application taking into account the extra cost, and deter-
mines an appropriate cache size based on that estimation. We
assume that the user is at least aware whether her application
is I/O intensive, and aware roughly how much data it deals
with. The additional cache in our study can be provided
either from the local memory of the physical machine on
which the base service resides or from the remote memory of
dedicated cache servers. The former LM case can be handled
simply by configuring the memory of the base service to be
the default memory size plus the additional cache size. On
the other hand, the latter RM case requires an atomic
memory allocation method to dedicate a specific region of
remote memory to a single user. Specific technical details of
RM cache handling are presented in Section 4.2.
The cost benefit of our CaaS model is twofold: profit
maximization and performance improvement. Clearly, the
former is the main objective of service provider. The latter
also contributes to achieving such an objective by reducing
the number of active physical machines. From the user’s
perspective, the performance improvement of application
(I/O-intensive applications in particular) can be obtained
with CaaS in a much more cost efficient manner since
caching capacity is more important than processing power
for those applications.
4 ELASTIC CACHE SYSTEM
In this section, we describe an elastic cache architecture,
which is the key component in realizing CaaS. We first
discuss the design rationale for a RM-based cache, and its
technical details.
4.1 Design Rationale
Among many important factors in designing an elastic
cache system, we particularly focus on the type of cache
medium, the implementation level of our cache system, the
communication medium between a cache server and a VM,
and reliability.
Cache media. We have three alternatives to implement
cache devices. Clearly, LM would be the best option due to
the speed gap between LM and other devices (RM and
SSD). Because LM has a higher cost per capacity, which
causes the capacity limitation, dedicating a large amount of
LM as cache could cause a side effect of memory pressure in
operating systems; this capacity issue primarily motivates
us to consider using RM and SSD as alternative cache
media. RM and SSD enable VMs to flexibly provision cache
practically without such a strict capacity limit.
SSDs have recently emerged as a new storage medium
that offers faster and more uniform access time than HDDs.
However, SSDs have few drawbacks due to the character-
istics of NAND flash memory; in-place updates are not
possible, and this causes extra overhead (latency)1
in page
update operations. Although many strategies [22], [23], [20]
are proposed to alleviate such problems, the latency of an
SSD is still higher than that of RM. In addition to this, RM
has no such limitations so that it can be a good candidate for
cache memory.
Implementation level. Elastic cache can be deployed at
either application or OS level (block device or file system
level). In this paper, it is the fundamental principle that the
cache need not affect application code or file systems owing
to the diversity of applications or file system configurations
on cloud computing. Application level elastic cache such as
memcached2
could have better performance than OS level
cache, since application level cache can exploit application
semantics. However, modification of application code is
always necessary for application level cache. A file system
level implementation can also provide many chances for
performance improvements, such as buffering and pre-
fetching. However, it forces users to use a specific file
system with the RM-based cache. In contrast, although a
block-device level implementation has fewer chances of
performance improvements than the application or file
system level counterpart, it does not depend on applica-
tions or file systems to take benefits from the underlying
block-level cache implementation.
RDMA versus TCP/IP. Despite the popularity of TCP/
IP, its use in high performance clusters has some restrictions
due to its higher protocol processing overhead and less
throughput than other cutting edge interconnects, such as
Myrinet and Infiniband. Since disk cache in our system
requires a low latency communication channel, we choose a
RDMA-enabled interface to guarantee fast and uniform
access time to RM space.
Dedicated-server-based cache versus cooperative cache.
Remote memory from dedicated servers might demand
1390 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 23, NO. 8, AUGUST 2012
Fig. 1. Overview of CaaS.
1. As Ousterhout et al. [25] pointed out, the low latency of a storage
device is very pivotal in designing storage systems.
2. Available at http://www. memcached.org.](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-4-320.jpg)
![more servers and related resources, such as rack and power,
during the operation. However, the total number of
machines for data processing applications is not greater
than that of machines without RM-based cache systems. As
an alternative way, we could implement remote memory
based on a cooperative cache, which uses participants’ local
memory as remote memory. This might help saving the
number of machines used and the energy consumed, but the
efficient management of cooperative cache is a daunting task
in large data centers. We are now back to the principle that
local memory should be used for a guest OS or an application
on virtual machines, rather than for remote memory. We
consider that this design rationale is practically less proble-
matic and better choice for implementing real systems.
Reliability. One of most important requirements for the
elastic cache is failure resilience. Since we implement the
elastic cache at the block device level, the cache system is
designed to support a RAID-style fault-tolerant mechanism.
Based on a RAID-like policy, the elastic cache can detect any
failure of cache servers and recovers automatically from the
failure (a single cache server failure).
In summary, we suggest that the CaaS model can be
better realized with an RM-based elastic cache system at the
block device level.
4.2 System Architecture
In this section, we discuss the important components of the
elastic cache. The elastic cache system is conceptually
composed of two components: a VM and a cache server.
A VM demands RM for use as a disk cache. We build an
RM-based cache as a block device and implement a new
block device driver (RM-Cache device). In the RM-Cache
device, RM regions are viewed as byte-addressable space.
The block address of each block I/O request is translated
into an offset of each region, and all read/write requests are
also transformed into RDMA read/write operations. We
use the device-mapper module of the Linux operating
system (i.e., DM-Cache3
) to integrate both the RM-Cache
device and a general block device (HDD) into a single block
device. This forms a new virtual block device, which makes
our cache pluggable and file-system independent.
In order to deal with resource allocation for remote
memory requested from each VM, a memory server offers a
memory pool as a cache pool. When a VM needs cache from
the memory pool, the memory pool provides available
memory. To this end, a memory server in the pool exports a
portion of its physical memory4
to VMs, and a server can
have several chunks. A normal server process creates 512 MB
memory space (chunk) via the malloc function, and it exports a
newly created chunk to all VMs, along with Chunk_Lock and
Owner regions to guarantee exclusive access to the chunk.
After a memory server process exchanges RDMA specific
information (e.g., rkey and memory address for corresponding
chunks) with a VM that demands RM, the exported memory
of each machine in the pool can be viewed as actual cache.
When a VM wants to use RM, a VM should first mark its
ownership on assigned chunks, then it can make use of the
chunk as cache. An example of layered architecture of a VM
and a memory pool, both of which are connected via the
RDMA interface, is concretely described in Fig. 2.
When multiple VMs try to mark their ownership on the
same chunk simultaneously, the access conflict can be
resolved by a safe and atomic chunk allocation method,
which is based on the CompareAndSwap operation supported
by Infiniband. The CompareAndSwap operation of InfiniBand
atomically compares the 64-bit value stored at the remote
memory to a given value and replaces the value at the remote
memory to a new value only if they are the same. By the
CompareAndSwap operation, only one node can acquire the
Chunk_Lock lock and it can safely mark its ownership to
the chunk by setting the Owner variable to consumer’s id.
Double paging in RDMA. The double paging problem
was first addressed in [26], and techniques such as ballooning
[27] are proposed to avoid the problem. Since the problem is a
bit technical but very critical in realizing CaaS in the cloud
platform, we describe what implementation difficulty it
causes and how we overcome the obstacle. Goldberg and
Hassinger [26] define levels of memory as follows:
. Level 0 memory: memory of real machine
. Level 1 memory: memory of VM
. Level 2 memory: virtual memory of VM.
In VM environments, the level 2 (level 1) memory is
mapped into the level 1 (level 0) memory, and this is called
double paging. For RDMA communication, a memory
region (level 0 memory) should be registered to the RDMA
device (i.e., InfiniBand device). Generally, kernel-level
functions mapping virtual to physical addresses (i.e.,
virt_to_phys) are used for memory registration to the
RDMA device. In VMs, the return addresses of functions in
a guest OS are in level 1 memory. Since the RDMA device
cannot understand the context of level 1 memory addresses,
direct registration of level 1 memory space to RDMA leads
to malfunction of RDMA communication.
To avoid this type of double paging anomaly in RDMA
communication, we exploit hardware IOMMUs to get
DMA-able memory (level 0 memory). IOMMUs are hard-
ware devices that manage device DMA addresses. To
virtualize IOMMUs, VMMs like Xen provide software
IOMMUs. Many hardware vendors also redesign IOMMUs
so that they are isolated between multiple operating
systems with direct device access. Thus, we use kernel
functions related with IOMMUs to get level 0 memory
addresses. The RM-Cache device allocates level 2 memory
space through kernel level memory allocation functions in
the VM. Then, it remaps the allocated memory to DMA-able
memory space through IOMMU. The mapped address of
HAN ET AL.: CASHING IN ON THE CACHE IN THE CLOUD 1391
Fig. 2. Elastic cache structure and double paging problem.
3. Available at http://visa.cis.fiu.edu/ming/dmcache/index.html.
4. A basic unit is called chunk (512 MB).](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-5-320.jpg)
![the DMA-able memory becomes level 0 memory that can
now be registered correctly by RDMA devices. Fig. 2
describes all these mechanisms in detail.
5 SERVICE MODEL
In this section, we first describe performance characteristics
of different cache alternatives and design two CaaS types.
Then, we present a pricing model that effectively captures
the tradeoff between performance and cost (profit).
5.1 Modeling Cache Services
I/O-intensive applications can be characterized primarily
by data volume, access pattern, and access type; i.e., file
size, random/sequential and read/write, respectively. The
identification of these characteristics is critical in choosing
the most appropriate cache medium and proper size since
the performance of different storage media (e.g., DRAMs,
SSDs, and HDDs) varies depending on one or more of those
characteristics. For example, the performance bottleneck
sourced from frequent disk accesses may be significantly
improved using SSDs as cache. However, if those accesses
are mostly sequential write operations the performance
with SSDs might only be marginally improved or even
made worse. Although the use of LM as cache delivers
incomparably better I/O performance than other cache
alternatives (e.g., RM),5
such a use is limited by several
issues including capacity and the utilization of host
machines. With the consideration of these facts, we have
designed two CaaS types as the following:
. High performance—makes use of LM as cache, and
thus, its service capacity is bounded by the max-
imum amount of LM.
. Best value (BV)—exploits RM as cache practically
without a limit.
In our CaaS model, it is assumed that a user, who
sends a request with a CaaS option (HP or BV), also
accompanies an application profile including data volume,
data access pattern, and data access type. It can be argued
that these pieces of application specific information might
not be readily available particularly for average users, and
some applications behave unpredictably. In this paper, we
primarily target the scenario in which users repeatedly
and/or regularly run their applications in clouds, and they
are aware of their application characteristics either by
analyzing business logic of their applications or by
obtaining such information using system tools (e.g.,
sysstat6
) and/or application profiling [28], [29]. When a
user is unable to identify/determine he/she simply rents
default IaaS instances without any cache service option
since CaaS is an optional service to IaaS. The service
granularity (cache size) in our CaaS model is set to a
certain size (512 MB/0.5 GB). In this study, we adopt three
default IaaS types: small, medium, and large with flat
rates of fs, fm, and fl, respectively.
5.2 Pricing
A pricing model that explicitly takes into account various
elastic cache options is essential for effectively capturing the
tradeoff between (I/O) performance and (operational) cost.
With HP, it is rather common to have many “awkward”
memory fragmentations (more generally, resource fragmen-
tations) in the sense that physical machines may not be used
for incoming service requests due to lack of memory. For
example, for a physical machine with four processor cores
and the maximum LM of 16 GB a request with 13 GB of HP
cache requirement on top of a small IaaS instance (which
uses 1 core) occupies the majority of LM leaving only 3 GB
available. Due to such fragmentations, an extra cost is
imposed on the HP cache option as a fragmentation penalty
(or performance penalty).
The average number of services (VMs) per physical
machine with the HP cache option (or simply HP services)
is defined as
HPservices ¼
LMmax
mHP
aHP ; ð1Þ
where LMmax
is the maximum local memory available, mHP
is the average amount of local memory for HP services. The
amount of LM cache requested for HP is assumed to be in a
uniform distribution.
And, the average number of services per physical
machine without HP is defined as
nonHPservices ¼
X
st
j¼0
LMmax
mj
aj
; ð2Þ
where st is the number of IaaS types (i.e., three in this
study), mj is the memory capacity of a service type j (sj),
and aj is the rate of services with type j.
Then, the average number of services (service count or
sc) per physical machine with/without HP requests are
defined as
scHP ¼ HPservices þ nonHPservices ð3Þ
scnoHP ¼
nonHPservices
1 aHP
; ð4Þ
where aHP is the rate of HP services. Note that the sum of all aj
is 1 aHP . We assume that the service provider has a means
to determine request rates of service types including the rate
of I/O-intensive applications (aIO) and further the rates of
those with HP and BV (aHP and aBV ) respectively. Since
services with BV use a separate RM server, they are treated
the same as default IaaS types (small, medium, and large).
In the CaaS model, the difference between scnoHP and
scHP can be seen as consolidation improvement (CI). For a
given IaaS type si, the rates (unit price) for HP and BV are
then defined as
cHP;i ¼ fi piHP;i þ ðf CIÞ=scHP ð5Þ
cBV ;i ¼ fi piBV ;i; ð6Þ
where piHP;i and piBV ;i are the average performance
improvement per unit increase of LM and RM cache
1392 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 23, NO. 8, AUGUST 2012
5. Surprisingly, the performance of LM cache is only marginally better
than RM in most of our experiments. The main cause of this unexpected
result is believed to be the behavior of the “pdflush” daemon in Linux, i.e.,
frequently writing back dirty data to disk.
6. Available at http://sebastien.godard.pagesperso-orange.fr.](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-6-320.jpg)
![increase (e.g., 0.5 GB), respectively, and f is the average
service rate; these values might be calculated based on
application profiles (empirical data).
With BV, the rate is solely dependent on piBV , and thus,
the total price the user pays for a given service request is
expected to be equivalent to that without cache on average
as shown in Fig. 3. We acknowledge that the use of average
performance improvement resulting in the uniformity in
service rates (cHP;i and cBV ;i) might not be accurate;
however, this is only indicative. In the actual experiments,
charges for services with cache option have been accurately
calculated in the way that for the price for a particular
service (application) remains the same regardless of use of
cache option and type of cache option. The cost efficiency
characteristic of BV can justify the use of average of varying
piBV values, the different values being due to application
characteristics (e.g., data access pattern and type) and cache
size. Alternatively, different average performance improve-
ment values (i.e., piHP and piBV ) can be used depending on
application characteristics (e.g., data access pattern and
type) profiled and specified by the user/provider. Further,
rates (pricing) may be mediated between the user and the
provider through service level agreement negotiation.
It might be desirable that the performance gain that users
experience with BV is proportional to that with HP. In other
words, their performance gap may be comparable to the
extra rate imposed on HP. The performance of a BV service
might not be easily guaranteed or accurately predicted since
that performance is heavily dependent on 1) the type and
amount of additional memory, 2) data access pattern and
type, and 3) the interplay of 1 and 2.
6 EVALUATION
In this section, we evaluate CaaS from the viewpoints of
both users and providers. To this end, we first measure the
performance benefit of our elastic cache system—in terms
of performance (e.g., transactions per minute), cache hit
ratio and reliability. The actual system level modification
for our system is not possible with the existing cloud
providers like Amazon and Microsoft. We can neither
dedicate physical servers of the cloud providers to RM
servers nor assign SSDs and RDMA devices to physical
servers. Owing to these issues, we could not test our
systems on real cloud services but we built an RDMA- and
SSD-enabled cloud infrastructure (Fig. 4) to evaluate our
systems. We then simulate a large-scale cloud environment
with more realistic settings for resources and user requests.
This simulation study enables us to examine the cost
efficiency of CaaS. While experimental results in Section 6.1
demonstrate the feasibility of our elastic cache system, those
in Section 6.2 confirm the practicality of CaaS (or applic-
ability of CaaS to the cloud).
6.1 Experimental Validation: Elastic Cache System
We validate the proof-of-concept elastic cache system with
two well-known benchmark suites: a database benchmark
program (TPC-C) and a file system benchmark program
(Postmark). TPC-C, which simulates OLTP activities, is
composed of read only and update transactions. The TPC-
C benchmark is update intensive with a 1.9:1 I/O read to
write ratio, and it has random I/O access patterns [30].
Postmark, which is designed to evaluate the performance of
e-mail servers, is performed in three phases: file creation,
transaction execution, and file deletion. Operations and files
in the transaction execution phase are randomly chosen. We
choose them because these two benchmarks have all
important characteristics of modern data processing applica-
tions. Intensive experiments with these applications show
that the prototype elastic cache architecture is a suitable
model as an efficient caching system for existing IaaS models.
Because of the attractive performance characteristics of
SSDs, the usefulness of our system might be questionable
compared with an SSD-based cache system. To answer
this, we compared our elastic cache system with an SSD-
based system.
6.1.1 Experimental Environments
Throughout this paper, we use experimental environments
as shown in Fig. 4. For performance evaluation, we used a
7-node cluster, each node of which is equipped with an
Intel(R) Core(TM)2 Quad CPU 2.83 GHz and 8 GB RAM.
All nodes are connected via both a switched 1 Gbps
Ethernet and 10 Gbps Infiniband. We used Infinihost IIILx
HCA cards from Mellanox for Infiniband connection. A
memory server runs Ubuntu 8.0.4 with Linux 2.6.24 kernel,
and exports 1 GB memory. One of the clusters instantiates a
VM using Xen 3.4.0. The VM with Linux 2.6.32 has 2 GB
memory and 1 vCPU, and it runs benchmark programs. The
cache replacement policy is Least Recently Used (LRU).
HAN ET AL.: CASHING IN ON THE CACHE IN THE CLOUD 1393
Fig. 3. Cost efficiency of CaaS. nc CHP and nc CBV are extra costs
charged for HP and BV CaaS types, respectively, where nc is the
number of cache units (e.g., 0.5 GB per cache unit. tHP , tBV , and tno-CaaS
are performance delivered with the two CaaS types and without CaaS,
respectively. Then, for a given IaaS type si, we have the following:
ðfi þ CHP;i ncÞ tHP;i ðfi þ CBV ;i ncÞ tBV ;i ¼ fi tno-CaaS;i.
Fig. 4. Experimental environment.](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-7-320.jpg)


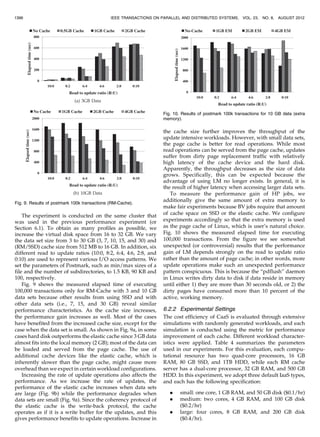
![A distinctive design rationale for CaaS is that the service
provider should be assured of profitability improvement
under various operational conditions; that is, the impact of
the resource scheduling policy that a provider adopts on its
profit should be minimal. To meet such a requirement, we
access the performance characteristics under four well-
known resource allocation algorithms—First-Fit, Next-Fit,
Best-Fit, and Worst-Fit—and a variant for each of these four;
hence, eight in total. The four variants adopt live resource
(VM) migration. FF places a user’s resource request in the first
resource that can accommodate the request. NF is a variant of
FF and it searches for an available resource from the resource
that is selected at the previous scheduling. BF (/WF) selects
the smallest (/largest) resource among those that can meet
the user’s resource request. Besides, we consider live VM
migration which has been widely studied primarily for better
resource management [31], [32]. In our service, a resource is
only migrated to other physical machine if the application
running on that resource is not I/O intensive. The decision on
resource migration is made in a best fit fashion. Thus, we
evaluate our CaaS model using the following eight algo-
rithms: FF, NF, BF, WF, and their migration counterparts,
FFM, NFM, BFM and WFM.
In our simulations, we set the number of physical
resources to be virtually unlimited.
6.2.3 Performance Metrics
We assume users who select BV are conservative in terms of
their spending, and their applications are I/O intensive and
not mission critical. Therefore, the performance gain from
services with more cache in BV is very beneficial. The
reciprocal benefit of that performance gain is realized on the
service provider’s side due to more efficient resource
utilization by effective service consolidation. These benefits
are measured using two performance metrics based pri-
marily on monetary relativity to those benefits. Specifically,
the benefit for users is measured by prices paid for their I/O-
intensive applications, whereas that for providers is quanti-
fied by profit (more specifically, unit profit) obtained from
running those applications. The former performance metric
is quite direct and the average price paid for I/O-intensive
applications is adopted. However, the performance metric
for providers is a little more complicated since the cost
related to serving those applications (including the number
of physical resources used) needs to be taken into account,
and thus, neither the total profit nor the average profit may
be an accurate measurement. As a result, the average unit
profit up is devised as the primary performance metric for
providers and it is defined as the total profit ptotal
obtained
over the “relative” number of physical nodes using rpn.
More formally,
ptotal
¼
X
r
i¼1
pi ð7Þ
rpn ¼
X
r
i¼1
acti
=actmax
; ð8Þ
and
up ¼ ptotal
=rpn; ð9Þ
where r is the total number of service requests (VMs), acti
and actmax
are the active duration of a physical node mi
(and it may vary between different nodes) and the
maximum duration among all physical nodes, respectively.
The active duration of a physical node is defined as the
amount of time from the time the node is instantiated to the
end time of a given operation period (or the finish time of a
particular experiment in our study).
6.2.4 Results
The number of experiments conducted with eight different
resource allocation algorithms is 320. Eight repeated trials
are executed for each experiment, and we obtained the
average value of eight results as average profit under
the corresponding parameter. These average unit profits are
normalized based on average unit profit of the WF
algorithm. Fig. 11 shows overall benefit of CaaS. From the
figure, we identify that IaaS requests with CaaS can give
more benefit (36 percent on average) to service providers
than those without CaaS regardless of the resource
allocation algorithms and VM migration policies. The
benefit of using VM migration is 32 percent on average
more than that without VM migration. The Best-Fit
algorithm gives more profit than other algorithms since it
minimizes resource fragmentation, which results in higher
resource consumption.
Fig. 12 shows average unit profits when the rate of I/O-
intensive jobs is varied. From results without VM migra-
tion, we can see that I/O-intensive jobs lead to more benefit
due to the efficiency of the elastic cache. The normalized
unit profit with VM migration increases when the number
of non-I/O-intensive jobs increases. This is because VM
HAN ET AL.: CASHING IN ON THE CACHE IN THE CLOUD 1397
TABLE 4
Experimental Parameters
Fig. 11. Overall results.](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-11-320.jpg)
![migration only applies to non-I/O-intensive jobs, and this
leads to more migration chances and higher resource
utilization.
Fig. 13 shows normalized unit profits with various ratios
of HP jobs to BV jobs. The provider profit is noticeably higher
with CaaS than No-CaaS when the rate of HP jobs is low.
However, a small loss to providers is incurred when the HP to
BV ratio is high (i.e., 2:1 and 1:0); this results from the
unexpected LM results (shown in Fig. 11). With the inherent
cost efficiency of BV, profits obtained from these jobs are
promising, particularly when the rate of BV jobs is high. If a
more efficientLM-based cacheis devised,profits with respect
to increases in HP jobs are most likely to lead to high profits.
7 CONCLUSION
With the increasing popularity of infrastructure services
such as Amazon EC2 and Amazon RDS, low disk I/O
performance is one of the most significant problems. In this
paper, we have presented a CaaS model as a cost efficient
cache solution to mitigate the disk I/O problem in IaaS. To
this end, we have built a prototype elastic cache system using
a remote-memory-based cache, which is pluggable and file-
system independent to support various configurations. This
elastic cache system together with the pricing model devised
in this study has validated the feasibility and practicality of
our CaaS model. Through extensive experiments, we have
confirmed that CaaS helps IaaS improve disk I/O perfor-
mance greatly. The performance improvement gained using
cache services clearly leads to reducing the number of
(active) physical machines the provider uses, increases
throughput, and in turn results in profit increase. This
profitability improvement enables the provider to adjust its
pricing to attract more users.
ACKNOWLEDGMENTS
Professor Albert Zomaya would like to acknowledge the
Australian Research Council Grant DP A7572. Hyungsoo
Jung is the corresponding author for this paper.
REFERENCES
[1] L. Wang, J. Zhan, and W. Shi, “In Cloud, Can Scientific
Communities Benefit from the Economies of Scale?,” IEEE Trans.
Parallel and Distributed Systems, vol. 23, no. 2, pp. 296-303, Feb.
2012.
[2] M.D. Dahlin, R.Y. Wang, T.E. Anderson, and D.A. Patterson,
“Cooperative Caching: Using Remote Client Memory to Improve
File System Performance,” Proc. First USENIX Conf. Operating
Systems Design and Implementation (OSDI ’94), 1994.
[3] T.E. Anderson, M.D. Dahlin, J.M. Neefe, D.A. Patterson, D.S.
Roselli, and R.Y. Wang, “Serverless Network File Systems,” ACM
Trans. Computer Systems, vol. 14, pp. 41-79, Feb. 1996.
[4] S. Jiang, K. Davis, and X. Zhang, “Coordinated Multilevel
Buffer Cache Management with Consistent Access Locality
Quantification,” IEEE Trans. Computers, vol. 56, no. 1, pp. 95-
108, Jan. 2007.
[5] H. Kim, H. Jo, and J. Lee, “XHive: Efficient Cooperative Caching
for Virtual Machines,” IEEE Trans. Computers, vol. 60, no. 1,
pp. 106-119, Jan. 2011.
[6] A. Menon, J.R. Santos, Y. Turner, G.J. Janakiraman, and W.
Zwaenepoel, “Diagnosing Performance Overheads in the Xen
Virtual Machine Environment,” Proc. First ACM/USENIX Int’l
Conf. Virtual Execution Environments (VEE ’05), 2005.
[7] L. Cherkasova and R. Gardner, “Measuring CPU Overhead for I/O
Processing in the Xen Virtual Machine Monitor,” Proc. Ann. Conf.
USENIX Ann. Technical Conf. (ATC ’05), 2005.
[8] J. Liu, W. Huang, B. Abali, and D.K. Panda, “High Performance
VMM-Bypass I/O in Virtual Machines,” Proc. Ann. Conf. USENIX
Ann. Technical Conf. (ATC ’06), 2006.
[9] A. Menon, A.L. Cox, and W. Zwaenepoel, “Optimizing Network
Virtualization in Xen,” Proc. Ann. Conf. USENIX Ann. Technical
Conf. (ATC ’06), 2006.
[10] P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho, R.
Neugebauer, I. Pratt, and A. Warfield, “Xen and the Art of
Virtualization,” Proc. 19th ACM Symp. Operating Systems Principles
(SOSP ’03), 2003.
[11] X. Zhang and Y. Dong, “Optimizing Xen VMM Based on Intel
Virtualization Technology,” Proc. IEEE Int’l Conf. Internet Comput-
ing in Science and Eng. (ICICSE ’08), 2008.
[12] P. Willmann, J. Shafer, D. Carr, A. Menon, S. Rixner, A.L. Cox, and
W. Zwaenepoel, “Concurrent Direct Network Access for Virtual
Machine Monitors,” Proc. IEEE 13th Int’l Symp. High Performance
Computer Architecture (HPCA ’07), 2007.
[13] Y. Dong, J. Dai, Z. Huang, H. Guan, K. Tian, and Y. Jiang,
“Towards High-Quality I/O Virtualization,” SYSTOR ’09: Proc.
Israeli Experimental Systems Conf., 2009.
[14] J.R. Santos, Y. Turner, G. Janakiraman, and I. Pratt, “Bridging the
Gap Between Software and Hardware Techniques for I/O
Virtualization,” Proc. Ann. Conf. USENIX Ann. Technical Conf.
(ATC ’08), 2008.
[15] K. Lim, J. Chang, T. Mudge, P. Ranganathan, S.K. Reinhardt, and
T.F. Wenisch, “Disaggregated Memory for Expansion and Sharing
in Blade Servers,” Proc. 36th Ann. Int’l Symp. Computer Architecture
(ISCA ’09), 2009.
[16] M. Marazakis, K. Xinidis, V. Papaefstathiou, and A. Bilas,
“Efficient Remote Block-Level I/O over an RDMA-Capable
NIC,” Proc. 20th Ann. Int’l Conf. Supercomputing (ICS ’06), 2006.
[17] J. Creasey, “Hybrid Hard Drives with Non-Volatile Flash and
Longhorn,” Proc. Windows Hardware Eng. Conf. (WinHEC), 2005.
[18] R. Harris, “Hybrid Drives: Not So Fast,” ZDNet, CBS Interactive,
2007.
[19] E.R. Reid, “Drupal Performance Improvement via SSD Technol-
ogy,” technical report, Sun Microsystems, Inc., 2009.
1398 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 23, NO. 8, AUGUST 2012
Fig. 12. Results with varying rates of I/O-intensive jobs.
Fig. 13. Results with varying ratios of HP jobs and BV jobs.](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-12-320.jpg)
![[20] S.-W. Lee and B. Moon, “Design of Flash-Based DBMS: An In-
Page Logging Approach,” Proc. ACM SIGMOD Int’l Conf. Manage-
ment of Data (SIGMOD ’07), 2007.
[21] T. Makatos, Y. Klonatos, M. Marazakis, M.D. Flouris, and A. Bilas,
“Using Transparent Compression to Improve SSD-Based I/O
Caches,” Proc. Fifth European Conf. Computer Systems (EuroSys ’10),
2010.
[22] J.-U. Kang, J.-S. Kim, C. Park, H. Park, and J. Lee, “A Multi-
Channel Architecture for High-Performance NAND Flash-Based
Storage System,” J. Systems Architecture, vol. 53, pp. 644-658, Sept.
2007.
[23] C. Park, P. Talawar, D. Won, M. Jung, J. Im, S. Kim, and Y. Choi,
“A High Performance Controller for NAND Flash-Based Solid
State Disk (NSSD),” Proc. IEEE Non-Volatile Semiconductor Memory
Workshop (NVSMW ’06), 2006.
[24] S. Kang, S. Park, H. Jung, H. Shim, and J. Cha, “Performance
Trade-Offs in Using NVRAM Write Buffer for Flash Memory-
Based Storage Devices,” IEEE Trans. Computers, vol. 58, no. 6,
pp. 744-758, June 2009.
[25] J. Ousterhout, P. Agrawal, D. Erickson, C. Kozyrakis, J. Leverich,
D. Mazières, S. Mitra, A. Narayanan, G. Parulkar, M. Rosenblum,
S.M. Rumble, E. Stratmann, and R. Stutsman, “The Case for
RAMClouds: Scalable High-Performance Storage Entirely in
DRAM,” ACM SIGOPS Operating Systems Rev., vol. 43, pp. 92-
105, Jan. 2010.
[26] R.P. Goldberg and R. Hassinger, “The Double Paging Anomaly,”
Proc. Int’l Computer Conf. and Exposition (AFIPS ’74), 1974.
[27] C.A. Waldspurger, “Memory Resource Management in VMware
ESX Server,” Proc. Fifth USENIX Conf. Operating Systems Design
and Implementation (OSDI ’02), 2002.
[28] B. Urgaonkar, P.J. Shenoy, and T. Roscoe, “Resource Overbooking
and Application Profiling in Shared Hosting Platforms,” Proc.
Fifth USENIX Conf. Operating Systems Design and Implementation
(OSDI ’02), 2002.
[29] A.V. Do, J. Chen, C. Wang, Y.C. Lee, A.Y. Zomaya, and B.B. Zhou,
“Profiling Applications for Virtual Machine Placement in
Clouds,” Proc. IEEE Int’l Conf. Cloud Computing, 2011.
[30] S. Chen, A. Ailamaki, M. Athanassoulis, P.B. Gibbons, R. Johnson,
I. Pandis, and R. Stoica, “TPC-E vs. TPC-C: Characterizing the
New TPC-E Benchmark via an I/O Comparison Study,” ACM
SIGMOD Record, vol. 39, pp. 5-10, Feb. 2011.
[31] H. Liu, H. Jin, X. Liao, C. Yu, and C.-Z. Xu, “Live Virtual Machine
Migration via Asynchronous Replication and State Synchroniza-
tion,” IEEE Trans. Parallel and Distributed Systems, vol. 22, no. 12,
pp. 1986-1999, Dec. 2011.
[32] G. Jung, M. Hiltunen, K. Joshi, R. Schlichting, and C. Pu, “Mistral:
Dynamically Managing Power, Performance, and Adaptation
Cost in Cloud Infrastructures,” Proc. IEEE 30th Int’l Conf.
Distributed Computing Systems (ICDCS ’10), pp. 62-73, 2010.
Hyuck Han received the BS, MS, and PhD
degrees in computer science and engineering
from Seoul National University, Korea, in 2003,
2006, and 2011, respectively. Currently, he is a
postdoctoral researcher at Seoul National Uni-
versity. His research interests are distributed
computing systems and algorithms.
Young Choon Lee received the BSc (hons)
degree in 2003 and the PhD degree from the
School of Information Technologies at the
University of Sydney in 2008. He is currently a
postdoctoral research fellow in the Centre for
Distributed and High Performance Computing,
School of Information Technologies. His current
research interests include scheduling and re-
source allocation for distributed computing sys-
tems, nature-inspired techniques, and parallel
and distributed algorithms. He is a member of the IEEE and the IEEE
Computer Society.
Woong Shin received the BS degree in
computer science from Korea University, Seoul,
in 2003. He is currently working toward the MS
degree from Seoul National University. He
worked for Samsung Networks from 2003 to
2006 and TmaxSoft from 2006 to 2009 as a
software engineer. His research interests are in
system performance study, virtualization, sto-
rage systems, and cloud computing.
Hyungsoo Jung received the BS degree in
mechanical engineering from Korea University,
Seoul, in 2002, and the MS and PhD degrees in
computer science from Seoul National Univer-
sity, Korea in 2004 and 2009, respectively. He is
currently a postdoctoral research associate at
the University of Sydney, Sydney, Australia. His
research interests are in the areas of distributed
systems, database systems, and transaction
processing.
Heon Y. Yeom received the BS degree in
computer science from Seoul National Univer-
sity in 1984 and the MS and PhD degrees in
computer science from Texas AM University in
1986 and 1992, respectively. He is a professor
with the School of Computer Science and
Engineering, Seoul National University. From
1986 to 1990, he worked with Texas Transpor-
tation Institute as a Systems Analyst, and from
1992 to 1993, he was with Samsung Data
Systems as a research scientist. He joined the Department of Computer
Science, Seoul National University in 1993, where he currently teaches
and researches on distributed systems, multimedia systems and
transaction processing. He is a member of the IEEE.
Albert Y. Zomaya is currently the chair professor
of High Performance Computing Networking
and Australian Research Council Professorial
fellow in the School of Information Technologies,
The University of Sydney. He is also the director
of the Centre for Distributed and High Perfor-
mance Computing which was established in late
2009. He is the author/co-author of seven books,
more than 400 papers, and the editor of nine
books and 11 conference proceedings. He is the
editor-in-chief of the IEEE Transactions on Computers and serves as an
associate editor for 19 leading journals, such as, the IEEE Transactions
on Parallel and Distributed Systems and Journal of Parallel and
Distributed Computing. He is the recipient of the Meritorious Service
Award (in 2000) and the Golden Core Recognition (in 2006), both from
the IEEE Computer Society. Also, he received the IEEE Technical
Committee on Parallel Processing Outstanding Service Award and the
IEEE Technical Committee on Scalable Computing Medal for Excellence
in Scalable Computing, both in 2011. He is a chartered engineer, a fellow
of the AAAS, the IEEE, the IET (United Kingdom), and a distinguished
engineer of the ACM.
. For more information on this or any other computing topic,
please visit our Digital Library at www.computer.org/publications/dlib.
HAN ET AL.: CASHING IN ON THE CACHE IN THE CLOUD 1399](https://image.slidesharecdn.com/han2012-220323115454/85/caching2012-pdf-13-320.jpg)















![[B5]memcached scalability-bag lru-deview-100](https://cdn.slidesharecdn.com/ss_thumbnails/b5memcached-scalability-baglru-deview-100-120919013502-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































