Download as PDF, PPTX


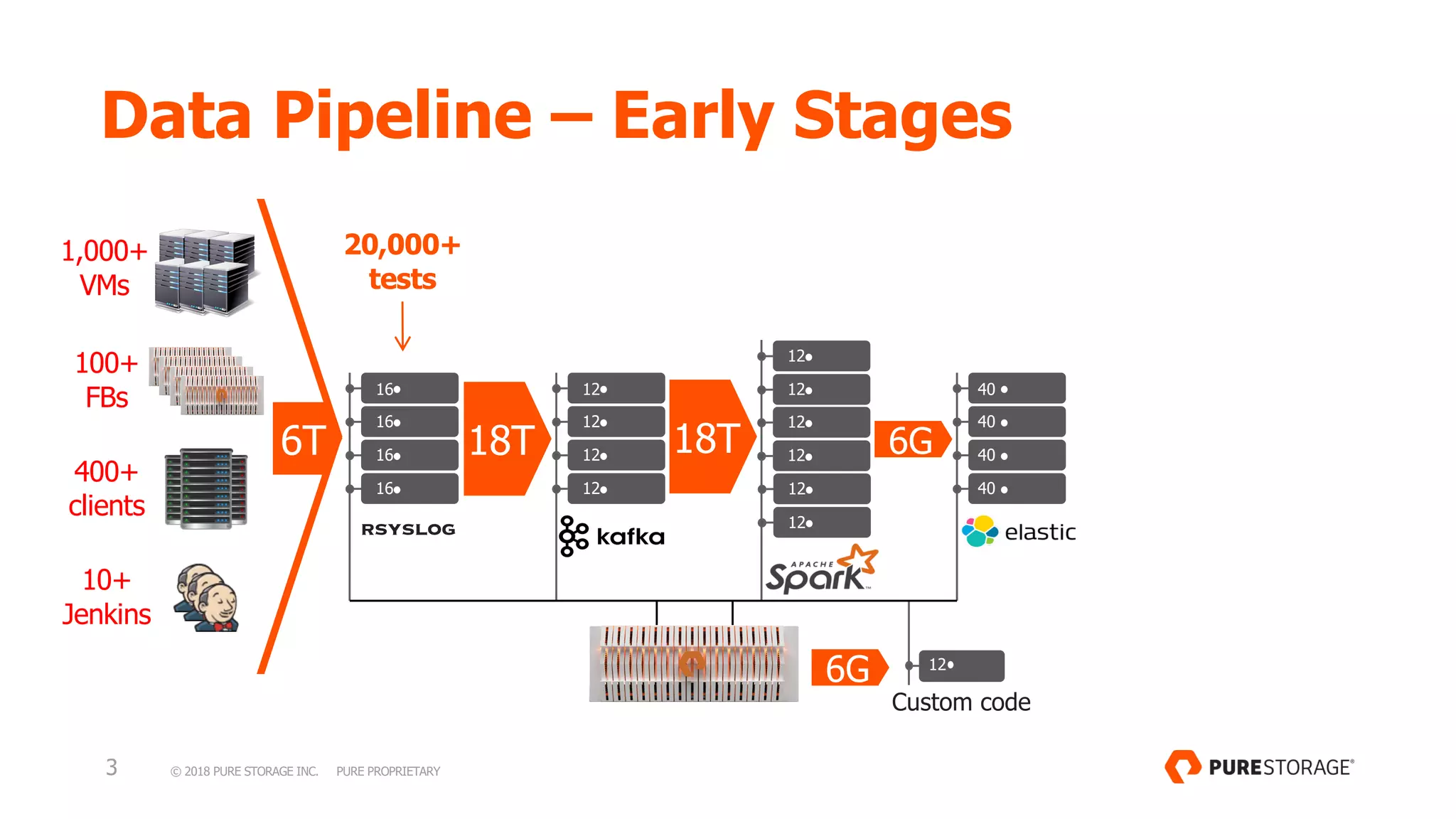
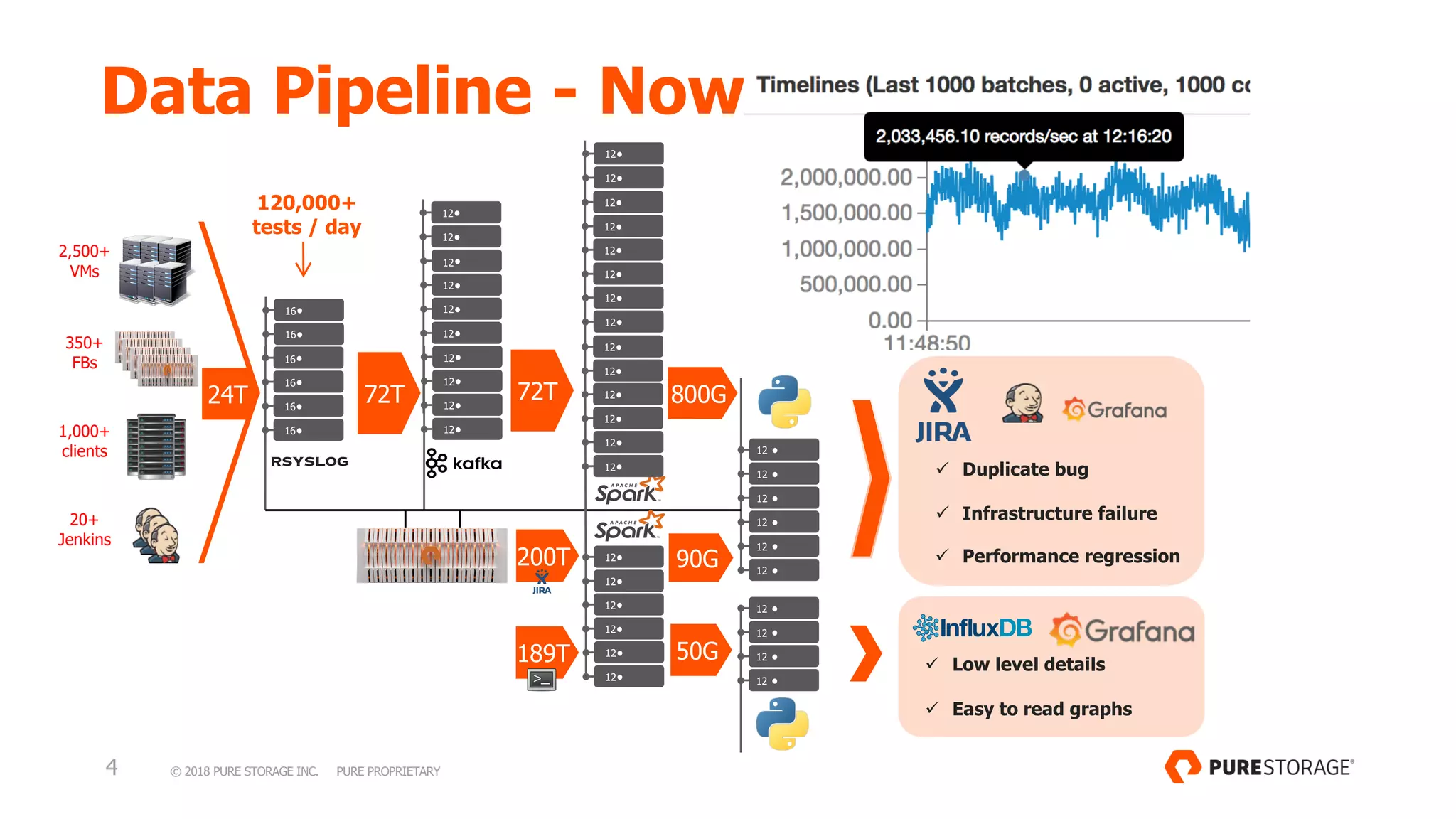








This document discusses Pure Storage's log analytics data pipeline. It began with over 1,000 VMs and 100 file brokers processing 1.5-2 million events per second and 0.5-1 petabytes of data daily. Through decoupling compute and storage, the pipeline now uses 2,500+ VMs and 350+ file brokers to process more data and 120,000+ tests daily while maintaining a 5 second SLA. Decoupling allows each stage to scale independently and improves flexibility, efficiency, reliability and scalability to handle growth.


![2019 07 Bizbok with Archimate 3 v3 [UPDATED !]](https://cdn.slidesharecdn.com/ss_thumbnails/201907bizbokwitharchimate3v3-190722110214-thumbnail.jpg?width=640&height=640&fit=bounds)





![[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessiondatalake-191027185852-thumbnail.jpg?width=640&height=640&fit=bounds)














































































