Download as PDF, PPTX














































































































![Log
Representation LogRecords == [
id: Nat,
epoch: Nat
]](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-145-2048.jpg)
![Log
Representation LogRecords == [
id: Nat,
epoch: Nat
]
Log == [
endOffset: Nat,
records: [Nat -> LogRecords]
]](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-146-2048.jpg)



![Replica State
Representation CONSTANT Replicas * {r1, r2, r3}
ReplicaState == [
log: Log,
hw: Nat,
leaderEpoch: Nat,
leader: Replicas,
isr: SUBSET Replicas
]](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-151-2048.jpg)
![Replica State
Representation CONSTANT Replicas * {r1, r2, r3}
ReplicaState == [
log: Log,
hw: Nat,
leaderEpoch: Nat,
leader: Replicas,
isr: SUBSET Replicas
]
AllReplicaStates ==
[Replicas -> ReplicaState]](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-152-2048.jpg)

![Quorum State
Representation QuorumState == [
leaderEpoch: Nat,
leader: Replicas,
isr: SUBSET Replicas
]](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-155-2048.jpg)




![Leader/ISR
Propagation LeaderAndIsrRequests ==
SUBSET QuorumState
leaderAndIsrRequests: {
[leader: A, epoch: 0, isr: {A, B, C}]
}
Example: after first leader election](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-160-2048.jpg)
![Leader/ISR
Propagation LeaderAndIsrRequests ==
SUBSET QuorumState
leaderAndIsrRequests: {
[leader: A, epoch: 0, isr: {A, B, C}],
[leader: B, epoch: 1, isr: {B, C}]
}
Example: after leader failure and reelection](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-161-2048.jpg)











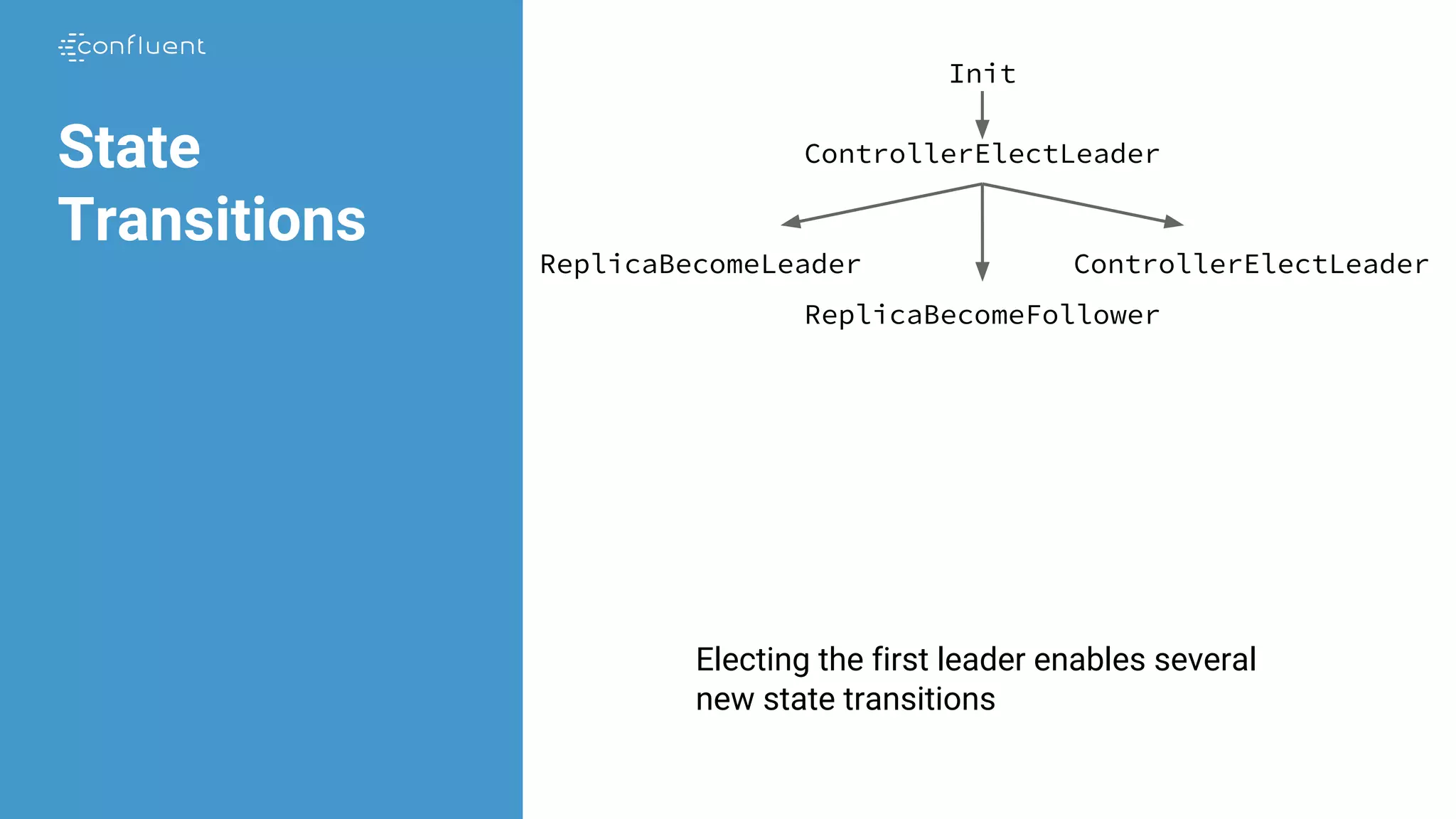

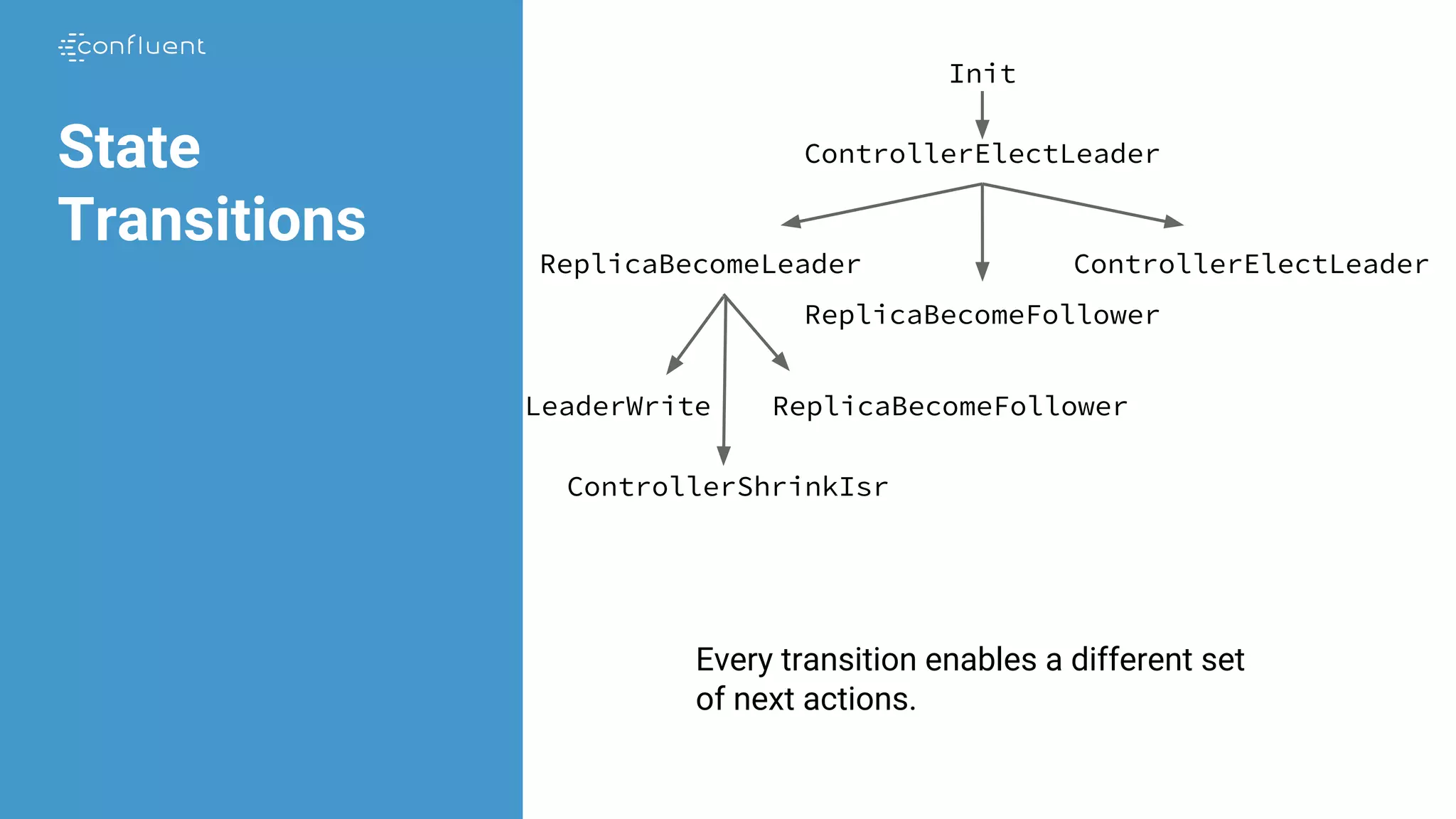
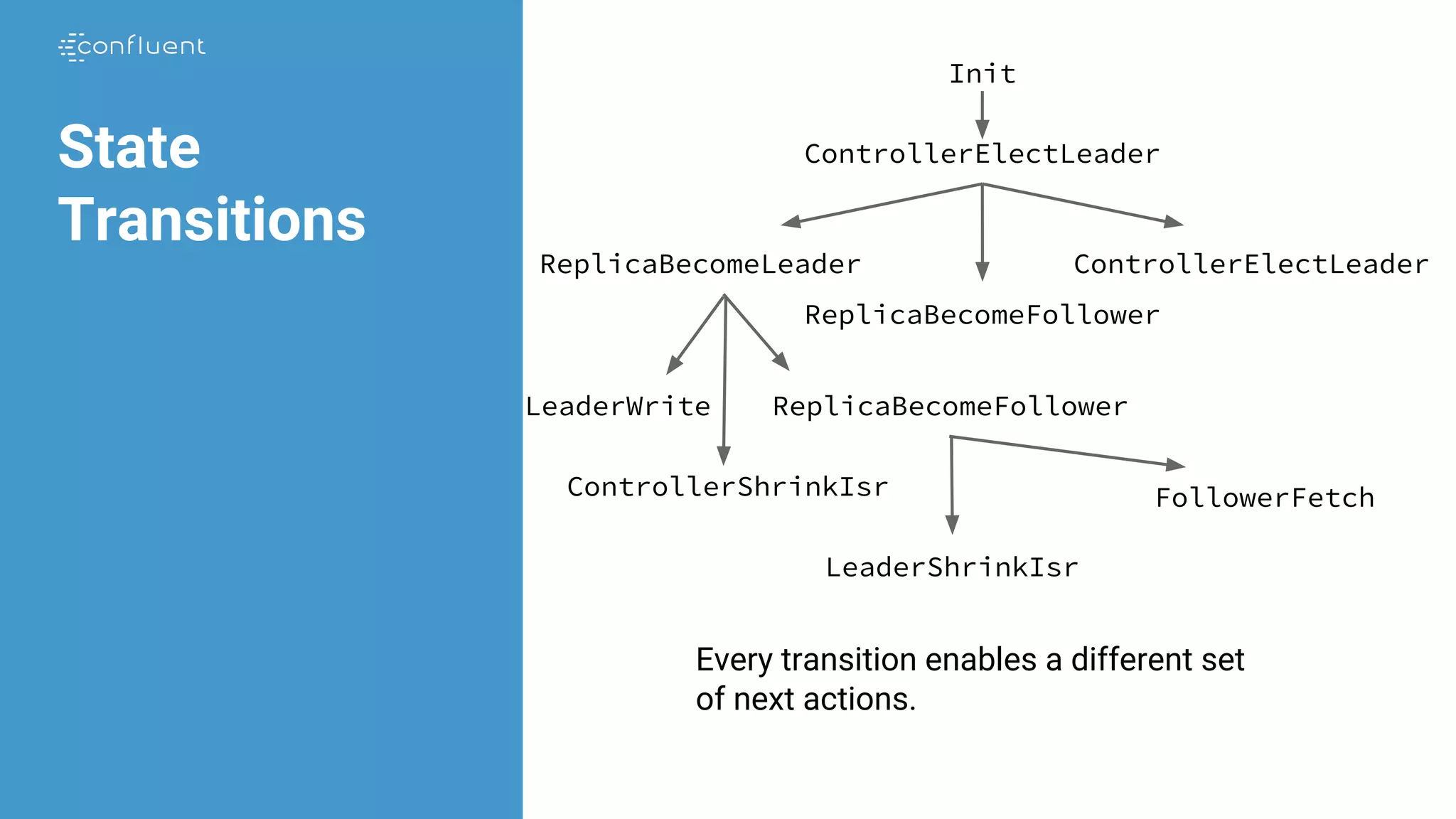



![Replication
Invariant StrongIsr == A r1 in Replicas:
/ ~ ReplicaPresumesLeadership(r1)
/ LET hw == replicaState[r1].hw
IN A r2 in quorumState.isr:
HasMatchingLogsUpTo(r1, r2, hw)](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-180-2048.jpg)
![Replication
Invariant StrongIsr == A r1 in Replicas:
/ ~ ReplicaPresumesLeadership(r1)
/ LET hw == replicaState[r1].hw
IN A r2 in quorumState.isr:
HasMatchingLogsUpTo(r1, r2, hw)
“If any replica is eligible to return data, then that data
must be replicated to all members of the current ISR”](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-181-2048.jpg)































![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-221-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Define the model’s state](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-222-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Specify how the state is
initialized](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-223-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Specify how the state is
initialized](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-224-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Specify the valid state
transitions](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-225-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Specify the valid state
transitions](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-226-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Specify the valid state
transitions](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-227-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Specify the set of valid
state transitions](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-228-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Specify the set of valid
state transitions](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-229-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
The specification is the
conjunction of the initial state
and all the states reachable
by repeatedly applying the
`Next` state transition](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-230-2048.jpg)
![VARIABLES var1, var2, …
Init ==
/ var1 = 1
/ …
Action1 ==
/ var1 leq 10
/ var1’ = var + 1
…
Next ==
/ Action1
/ Action2
/ …
Spec == Init / []Next
Invariant ==
/ var1 geq 1
/ …
TLA+
Overview
Define the model invariants
that should hold after every
state transition](https://image.slidesharecdn.com/jasongustafson-181022223237/75/Hardening-Kafka-Replication-231-2048.jpg)


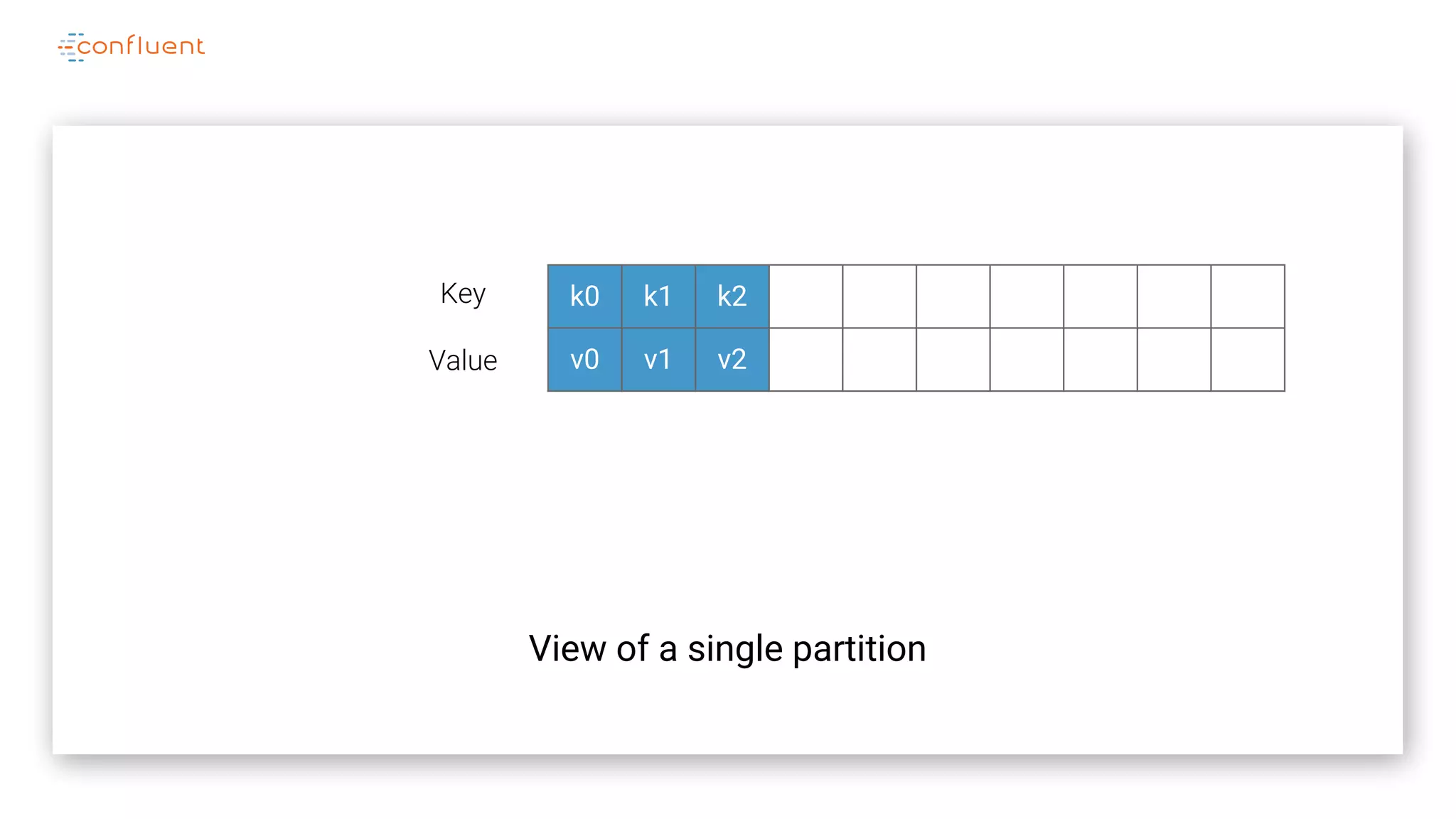
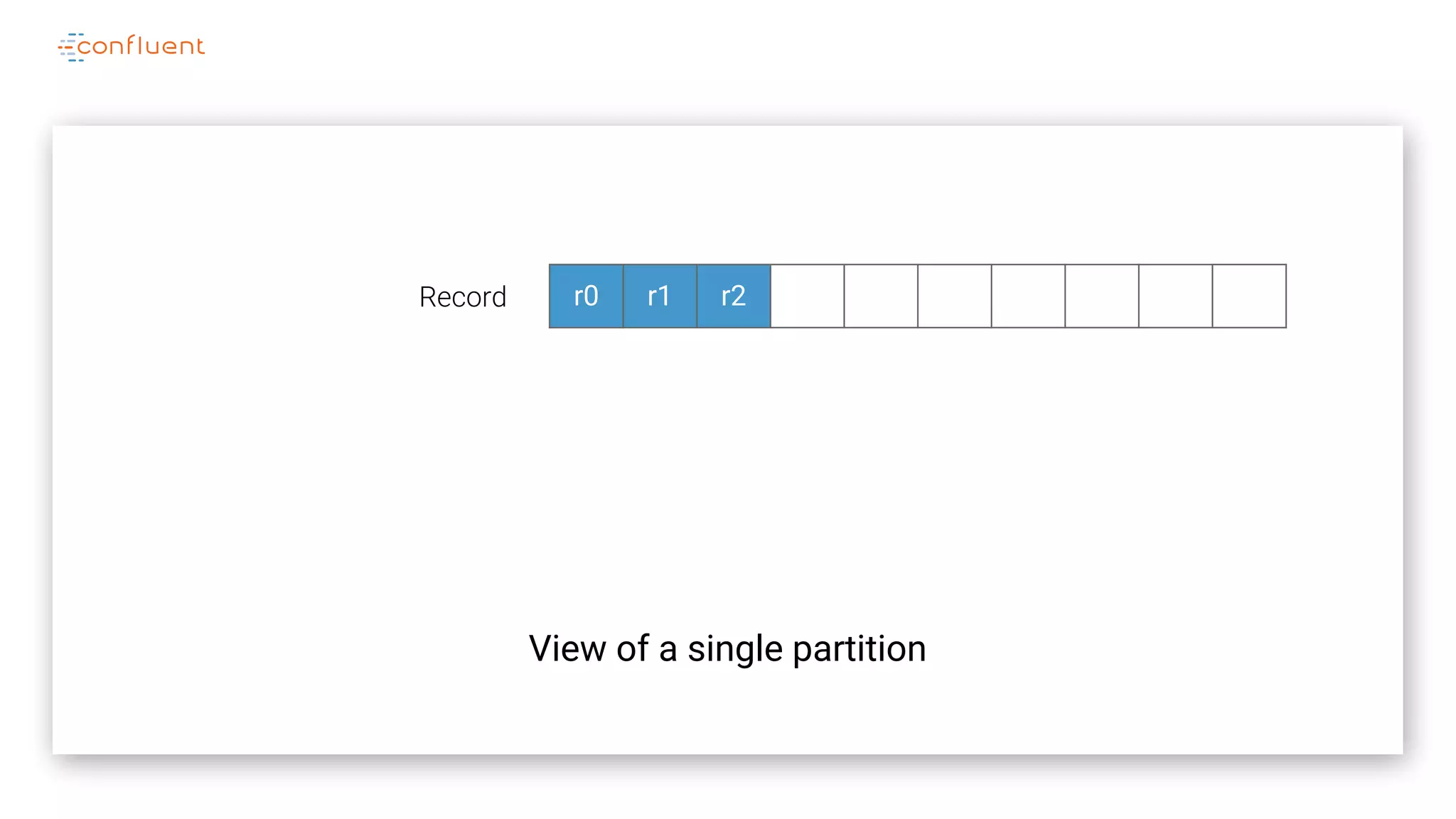
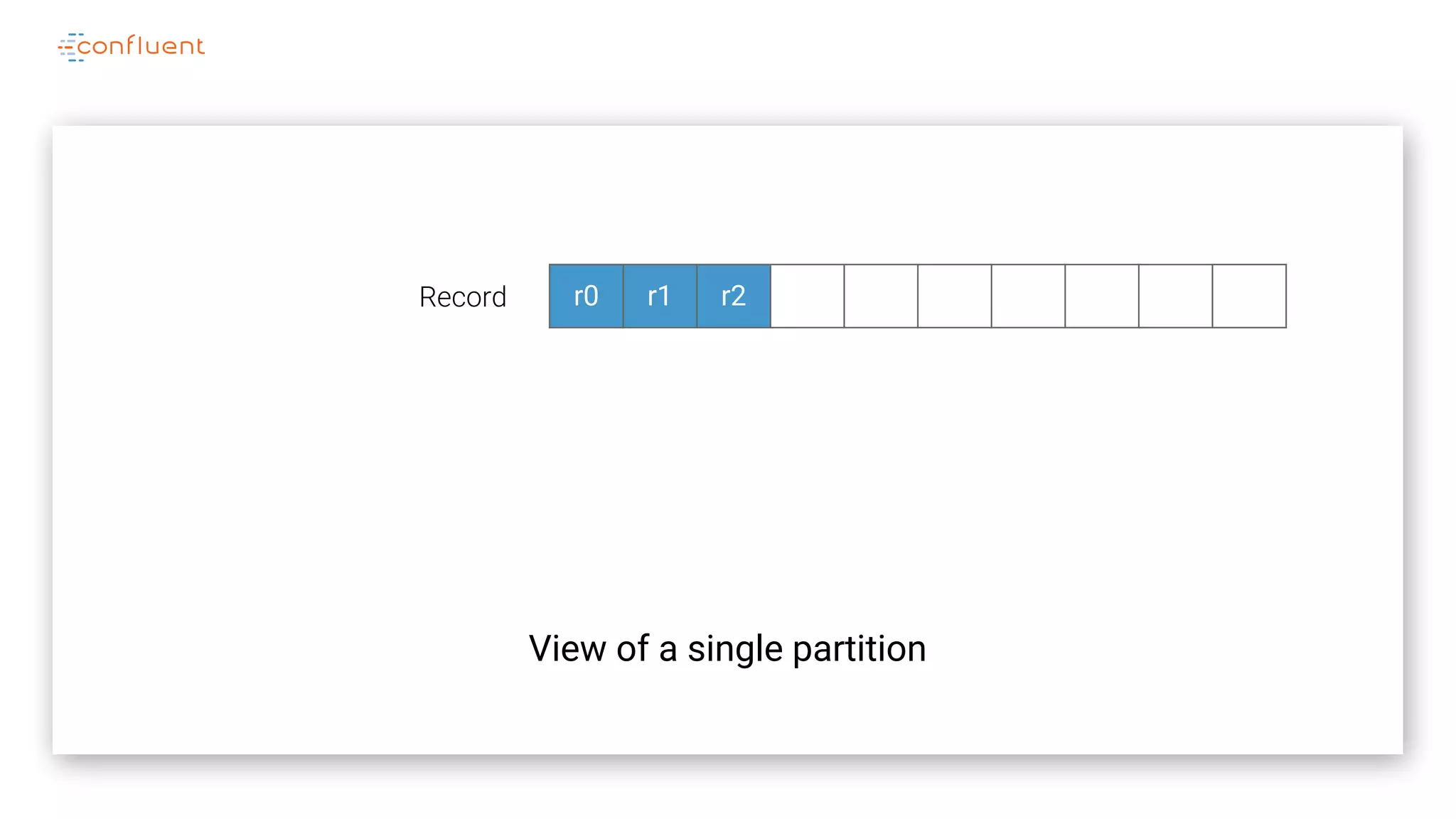
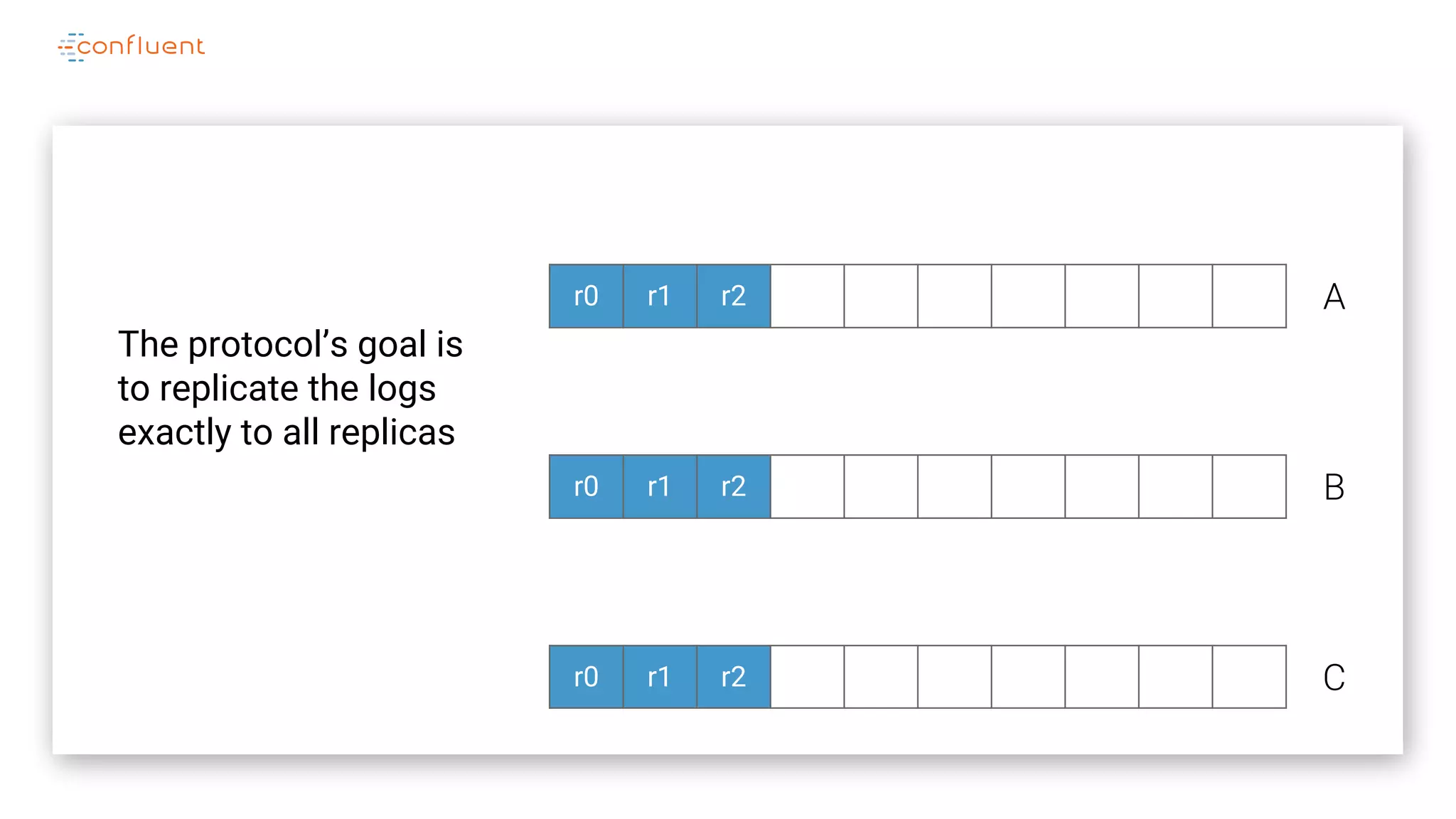
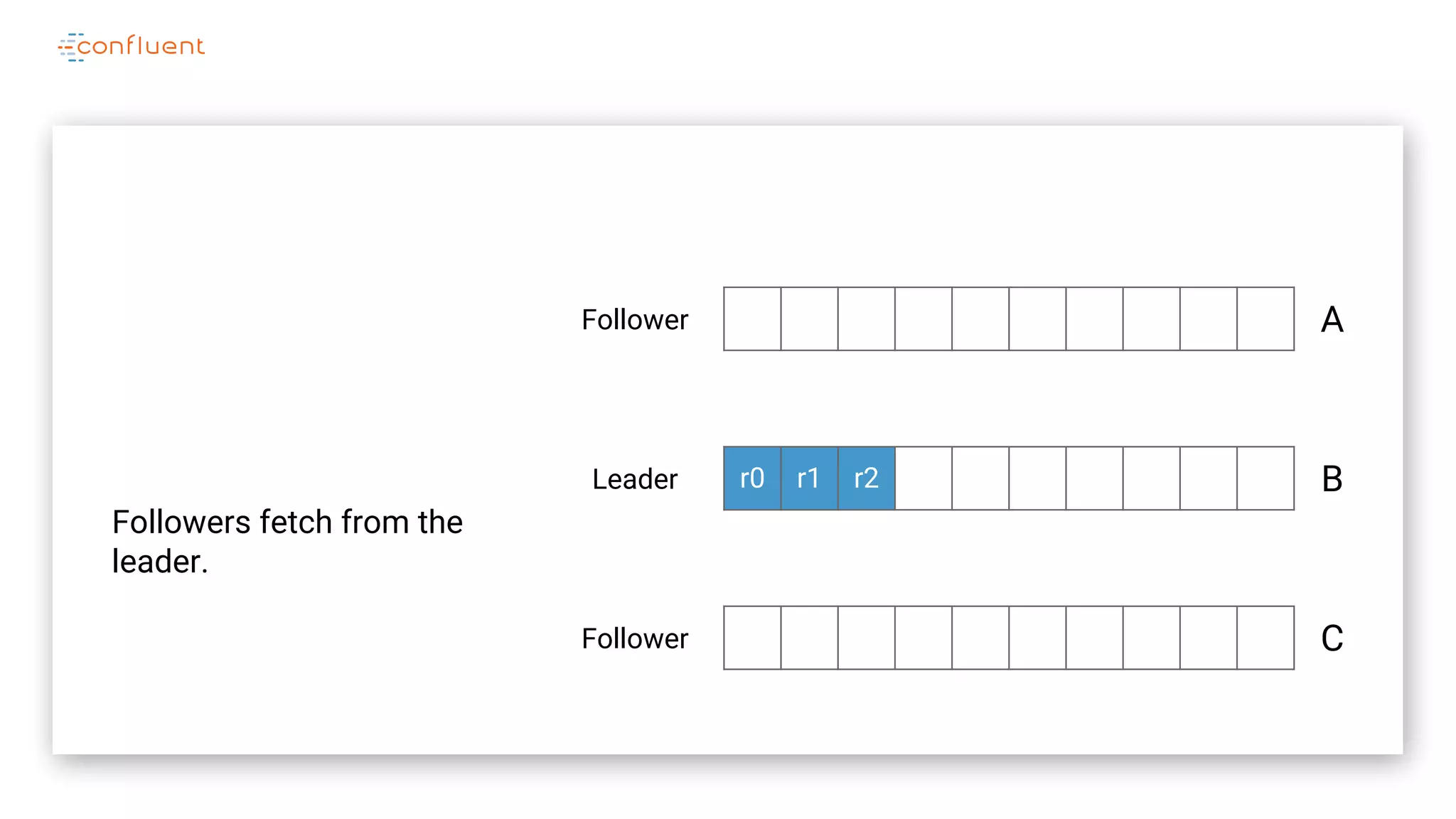
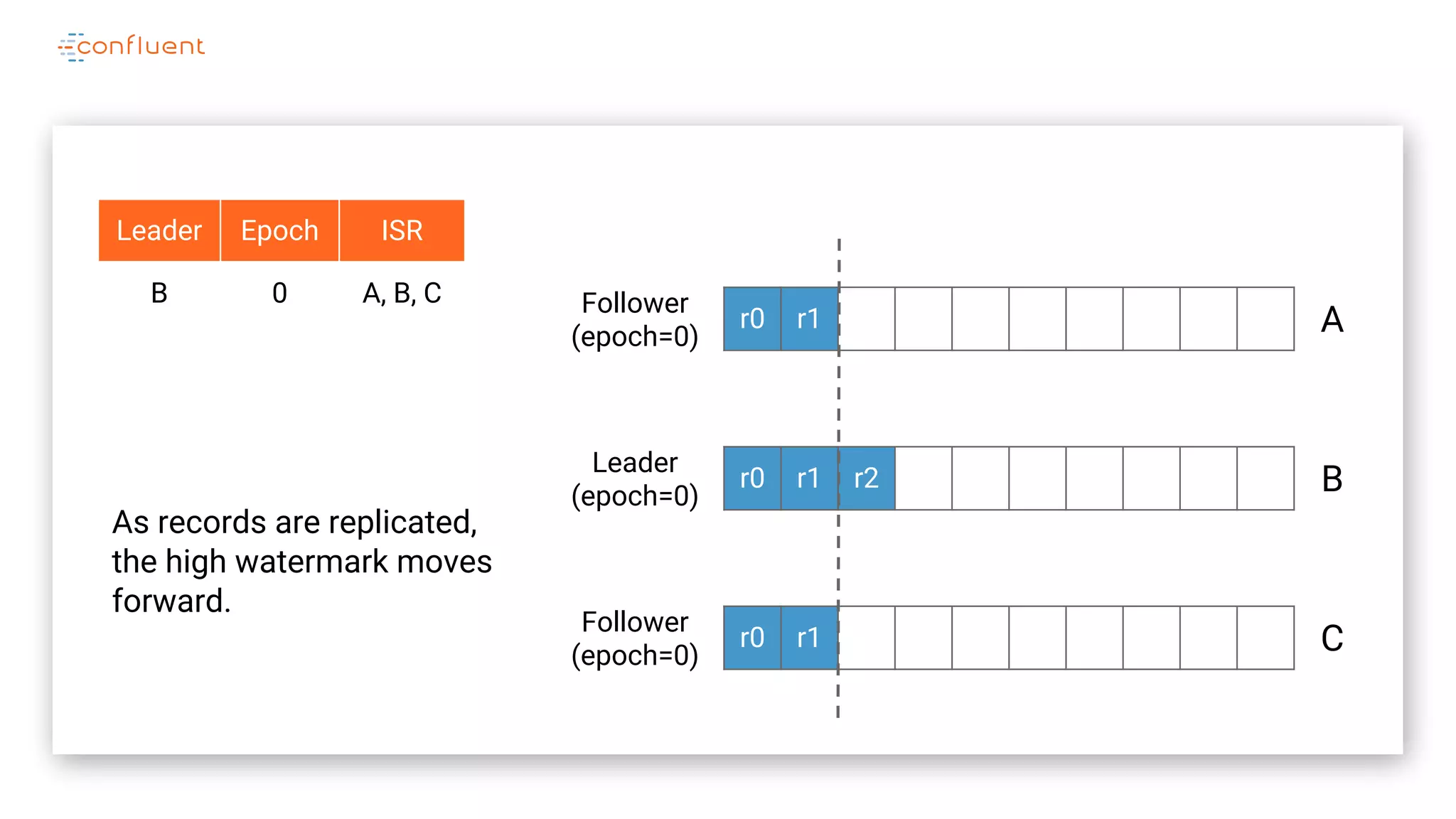
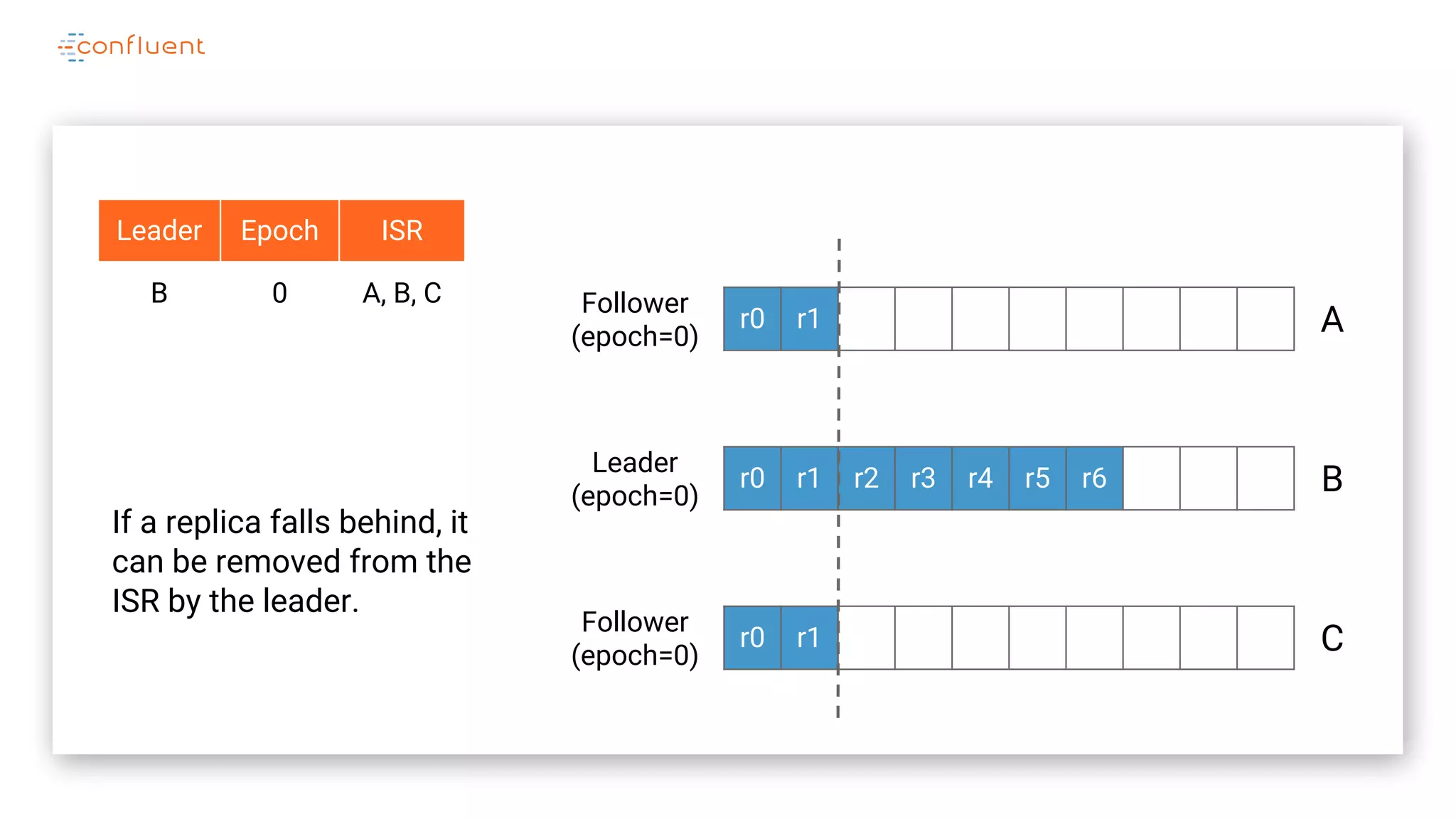
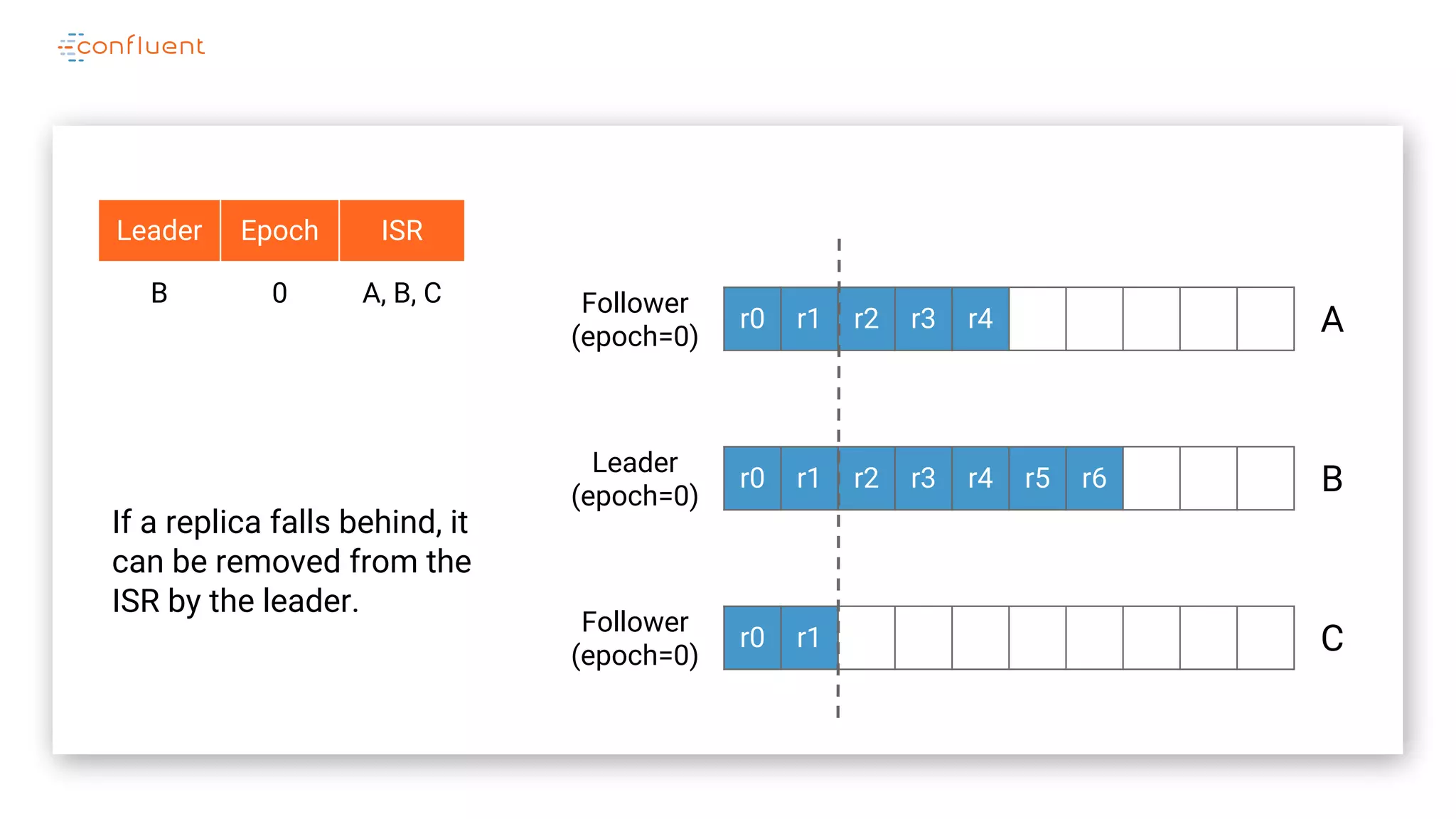
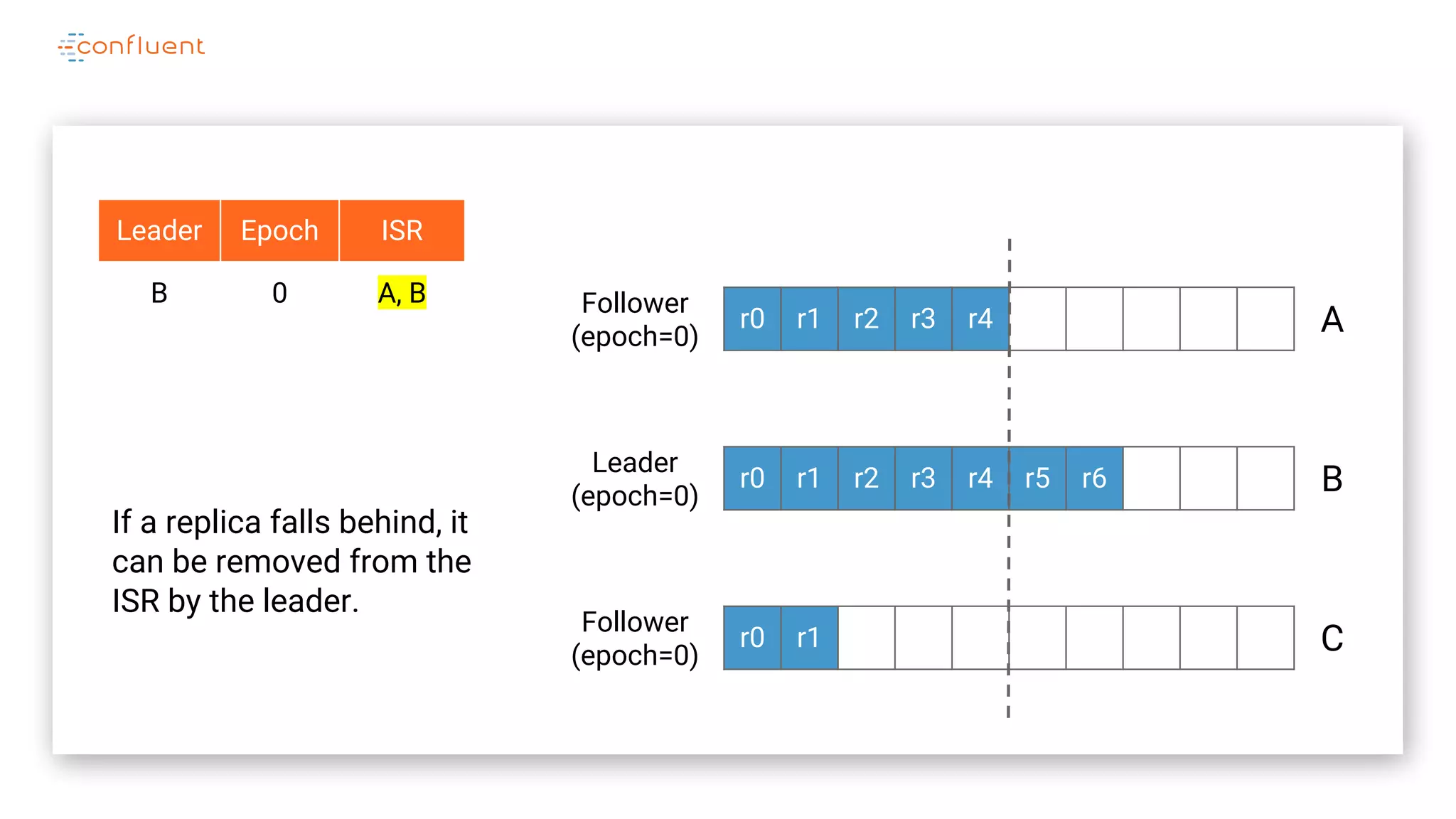
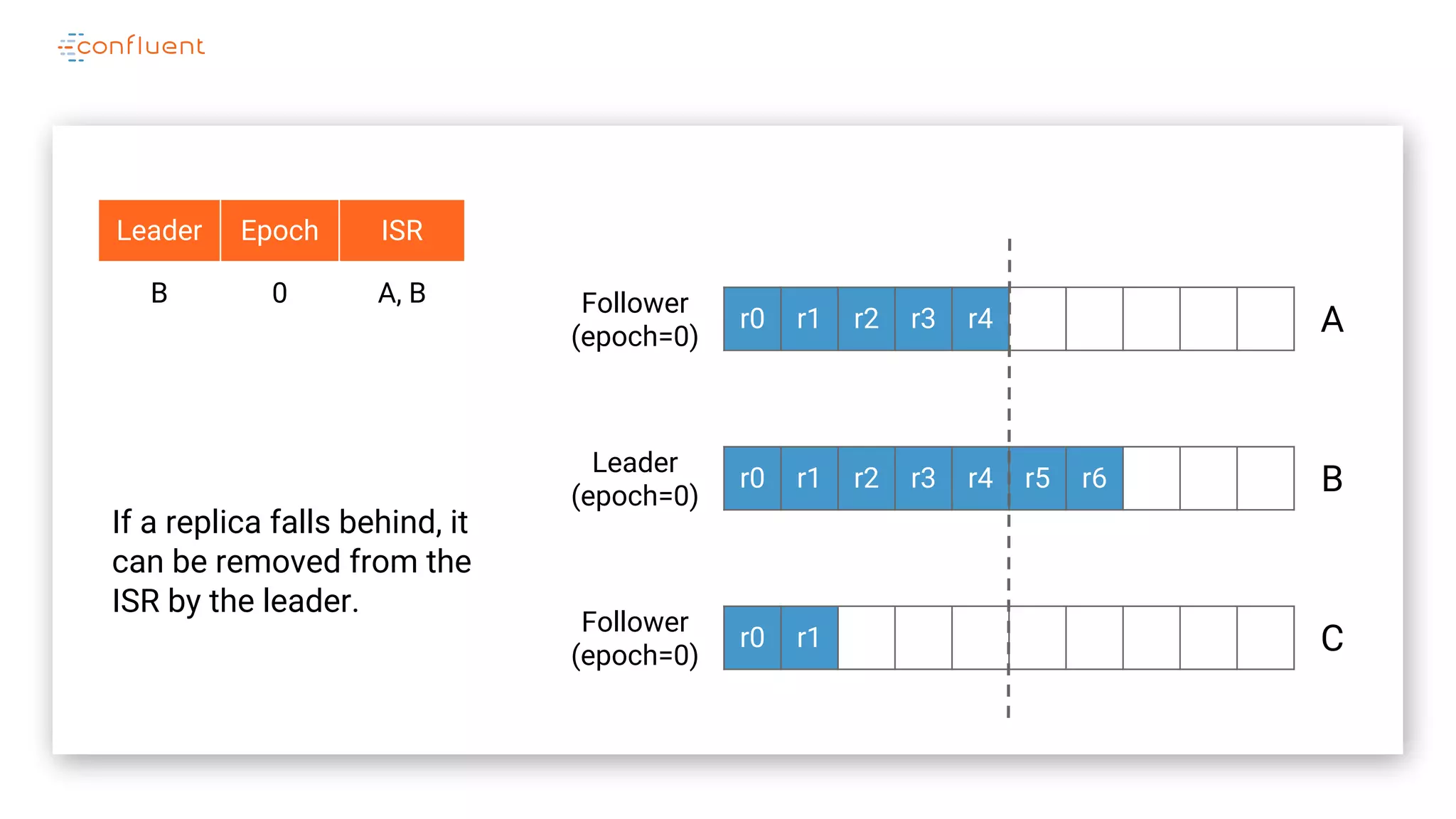
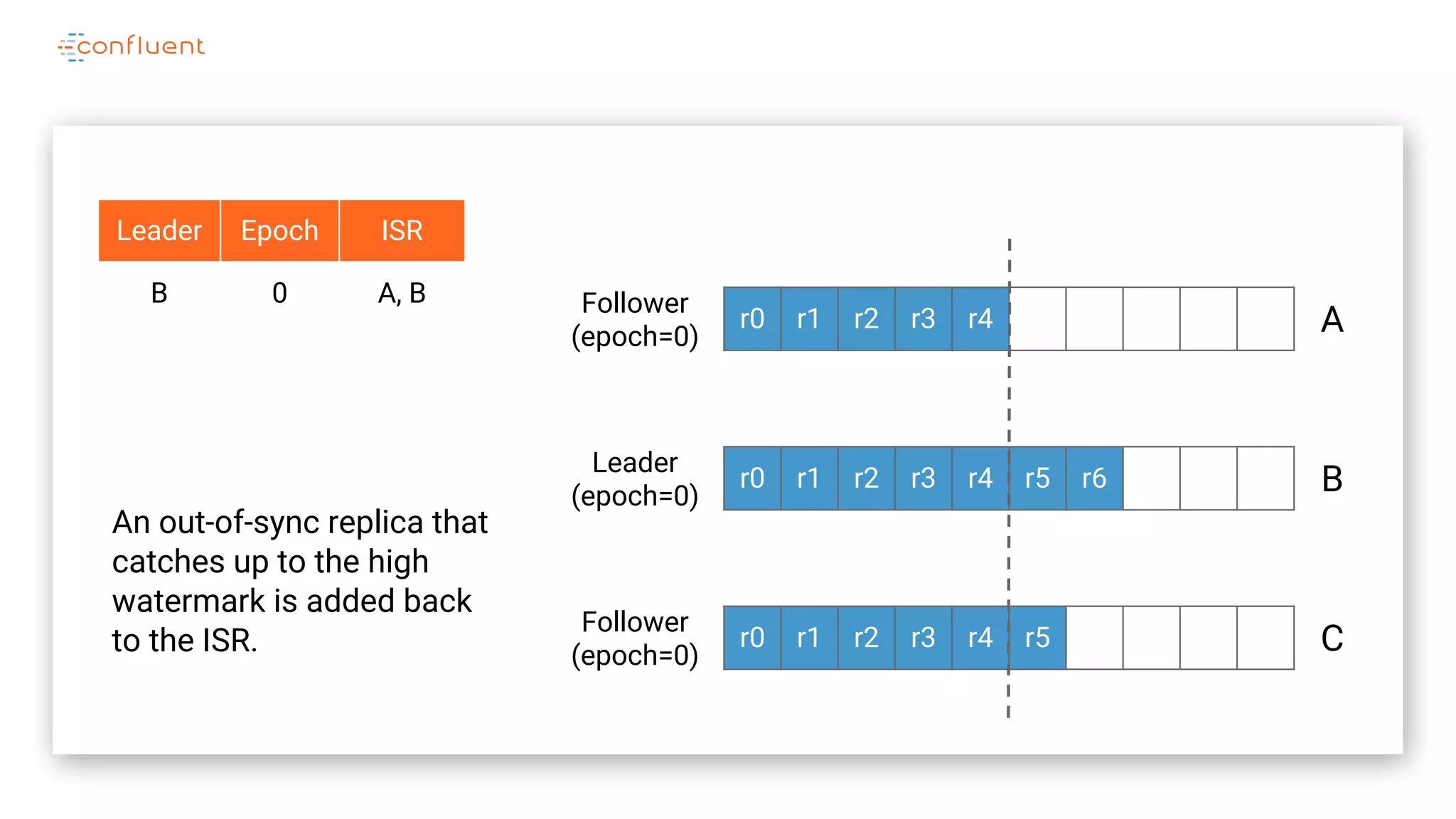
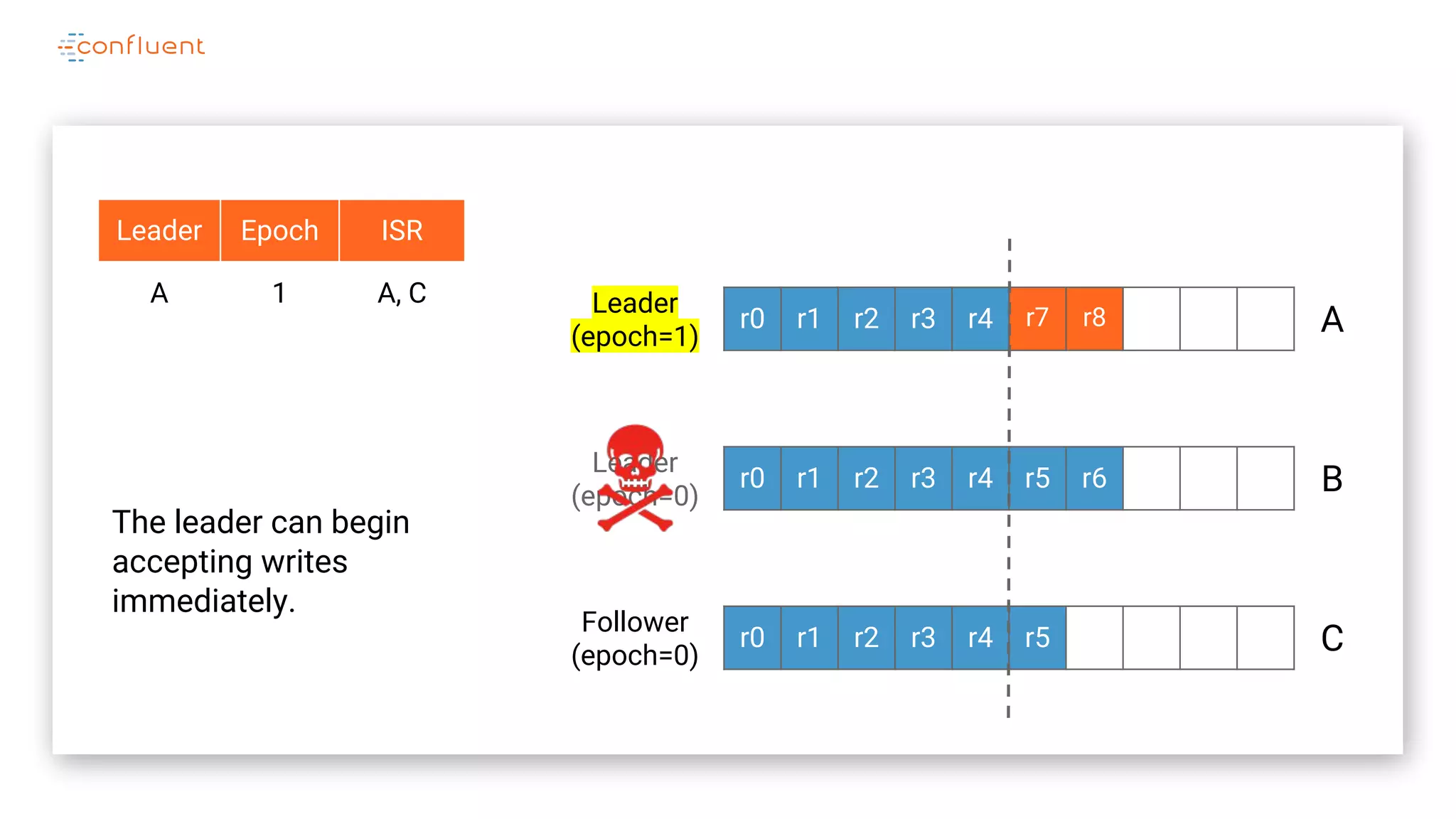
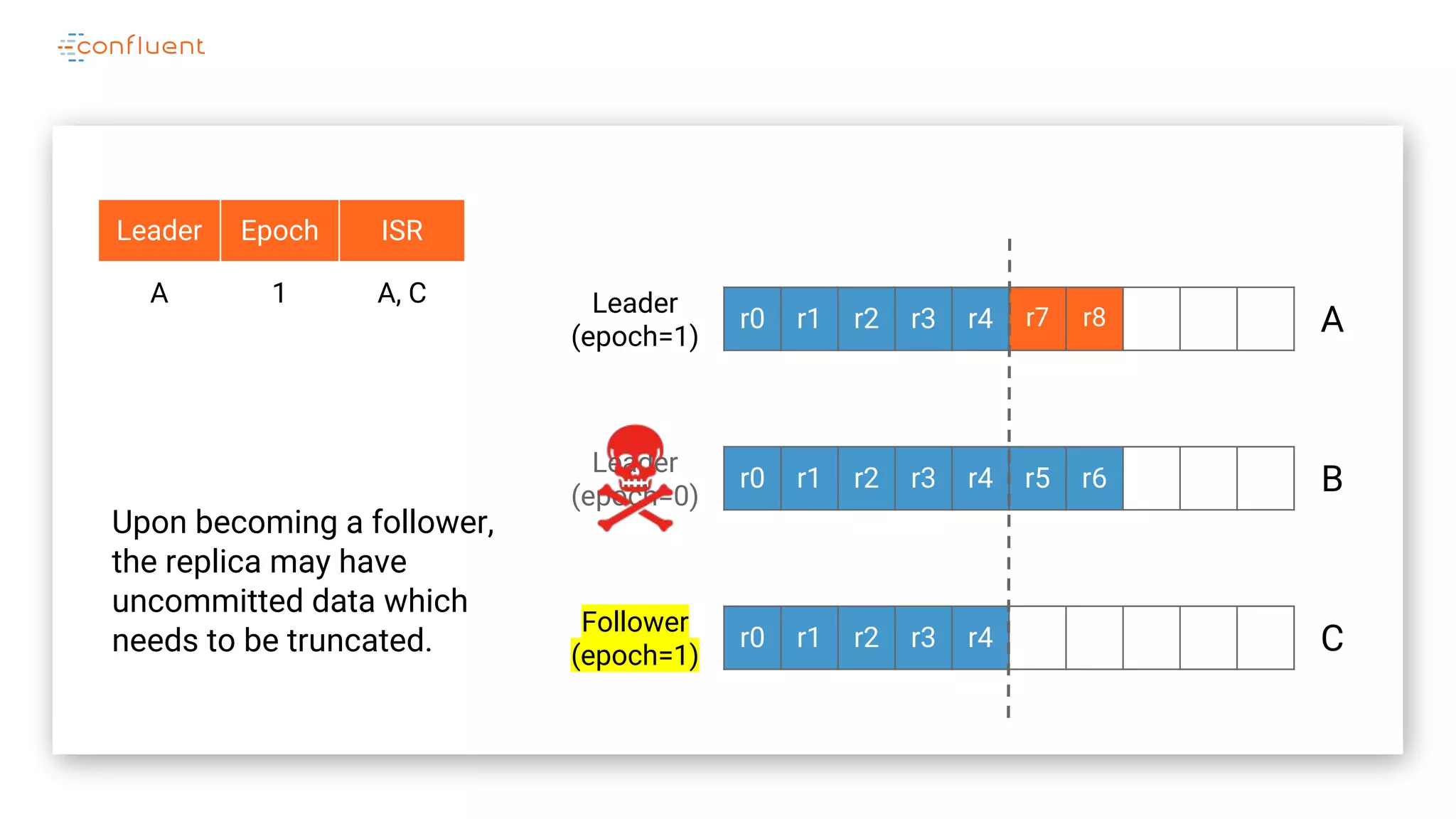
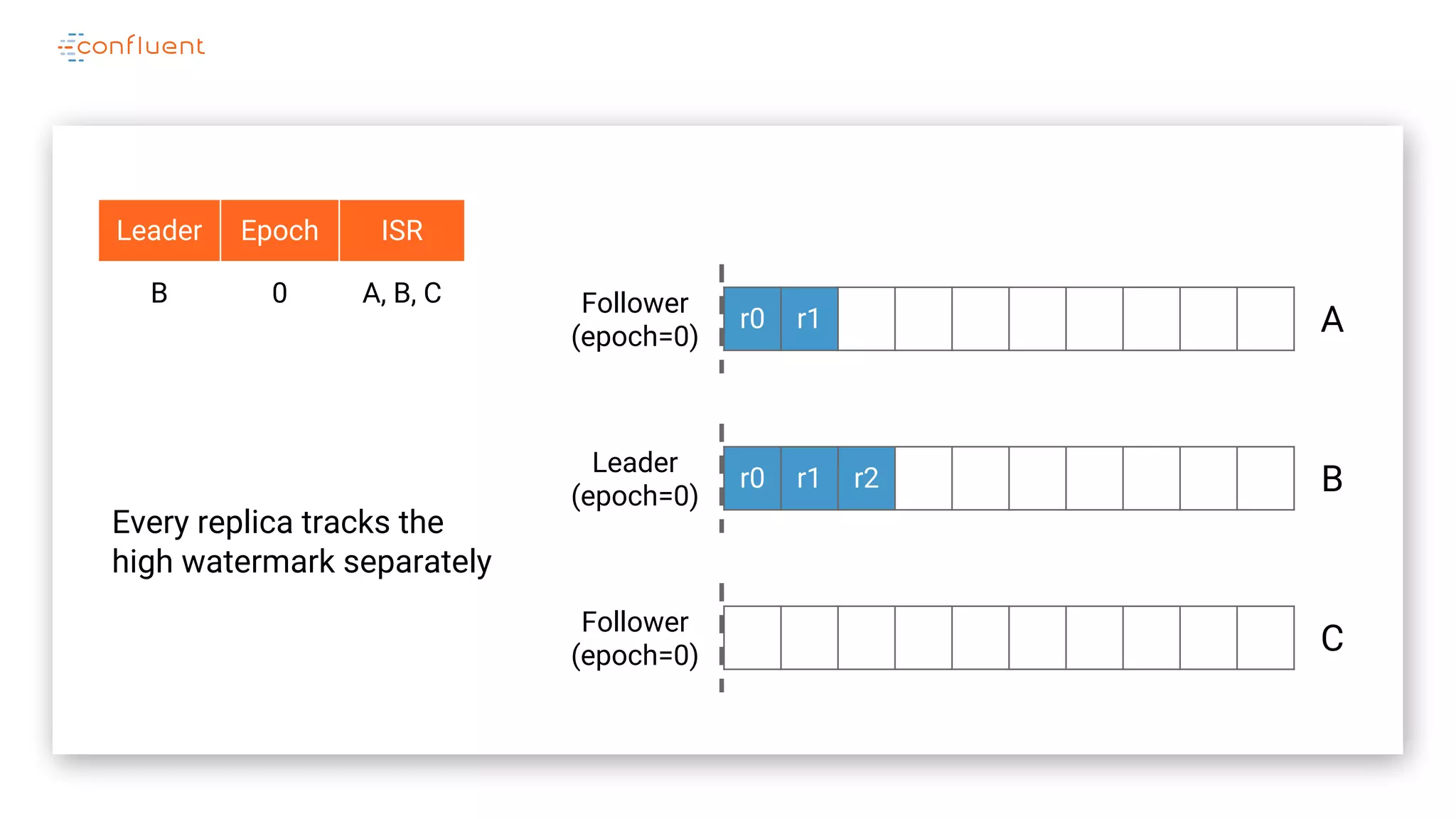
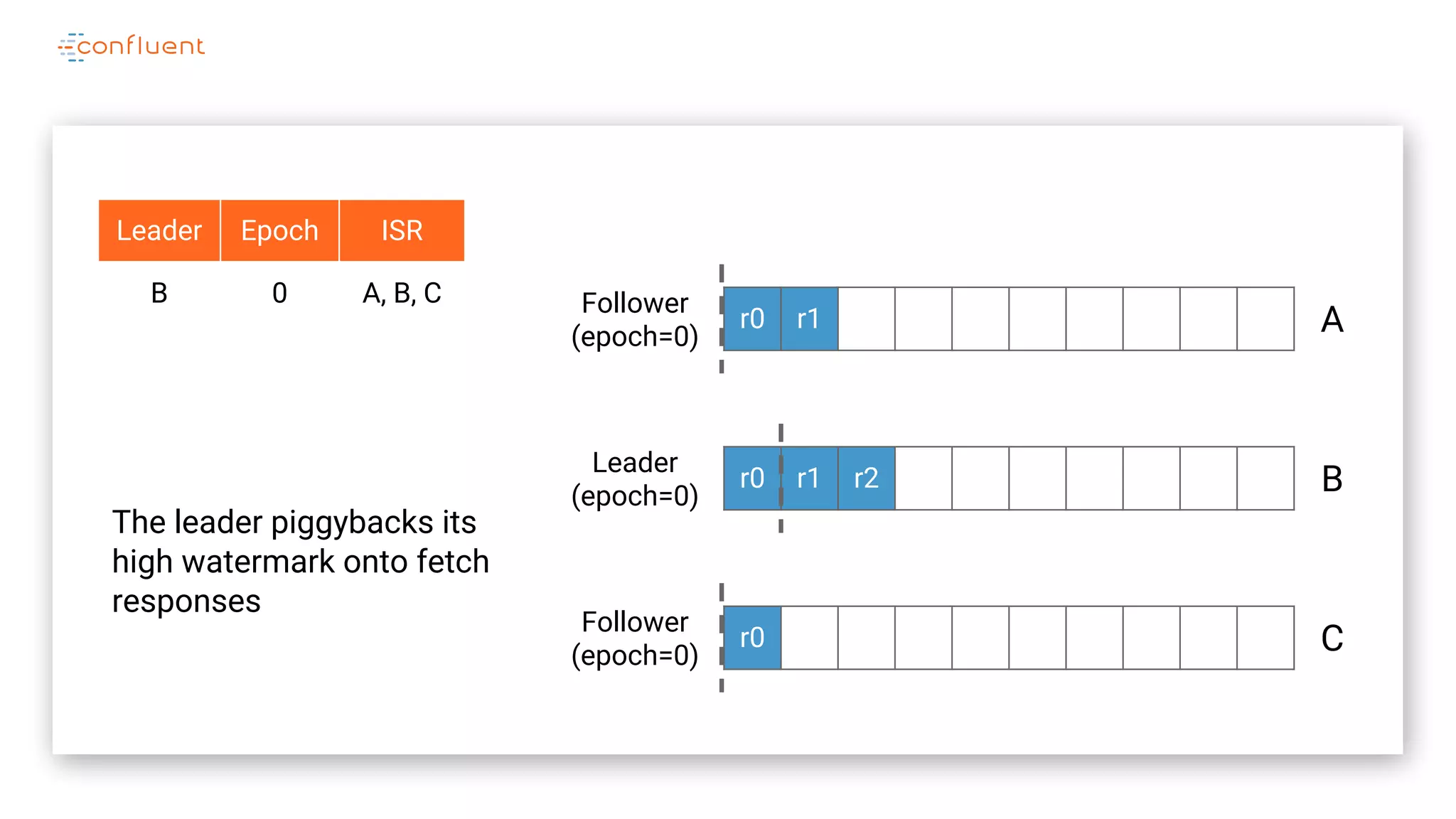
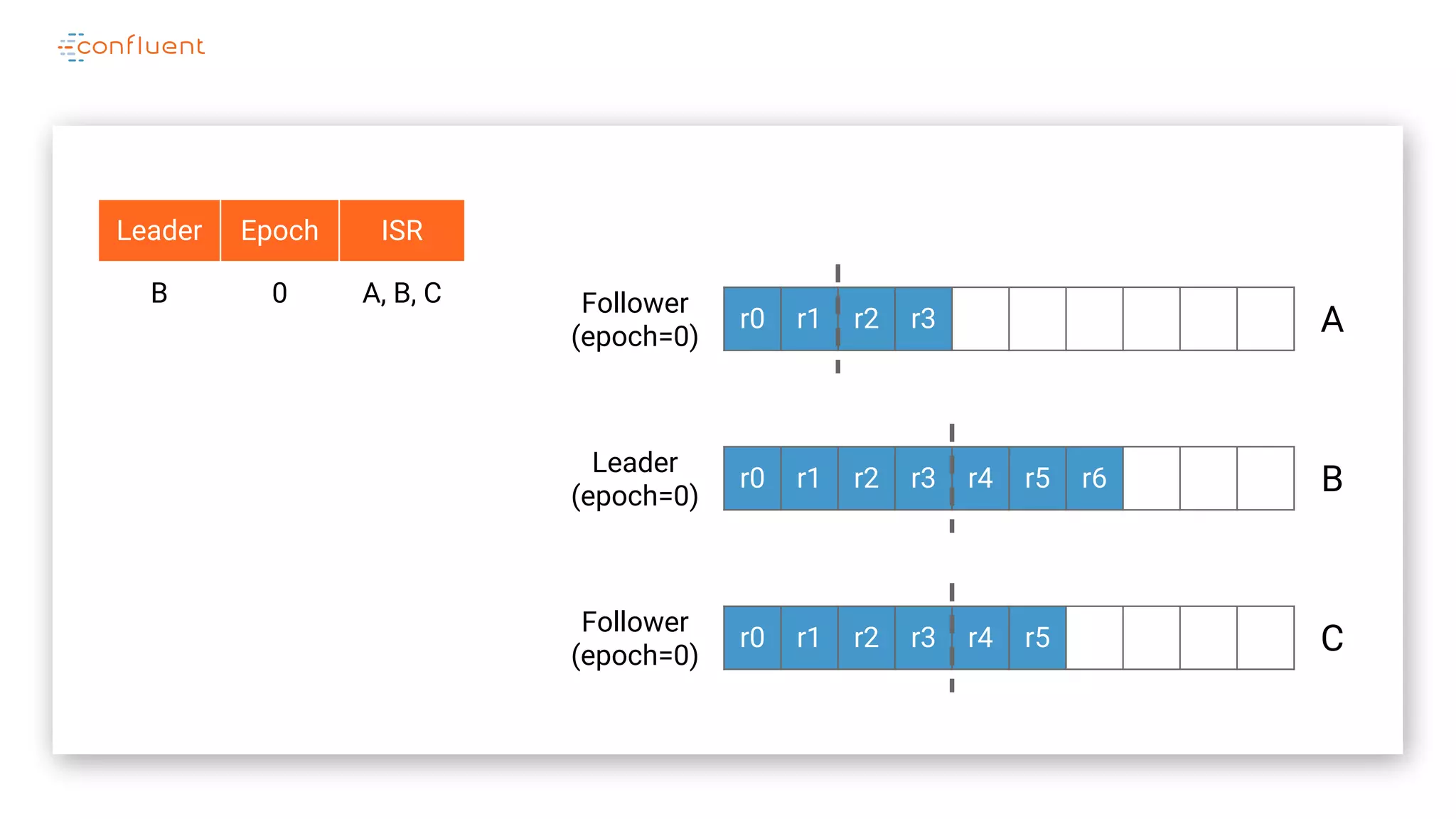
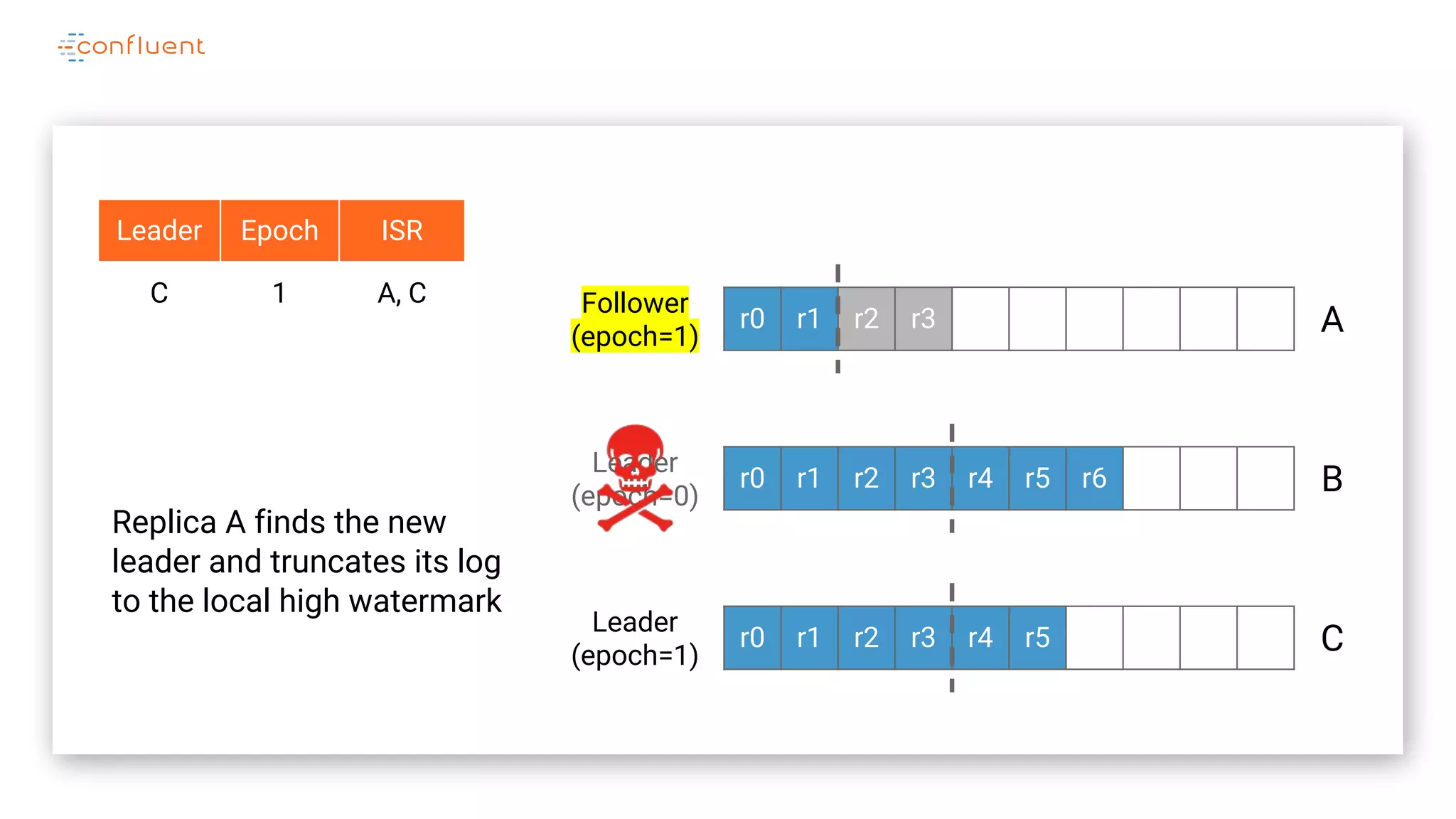
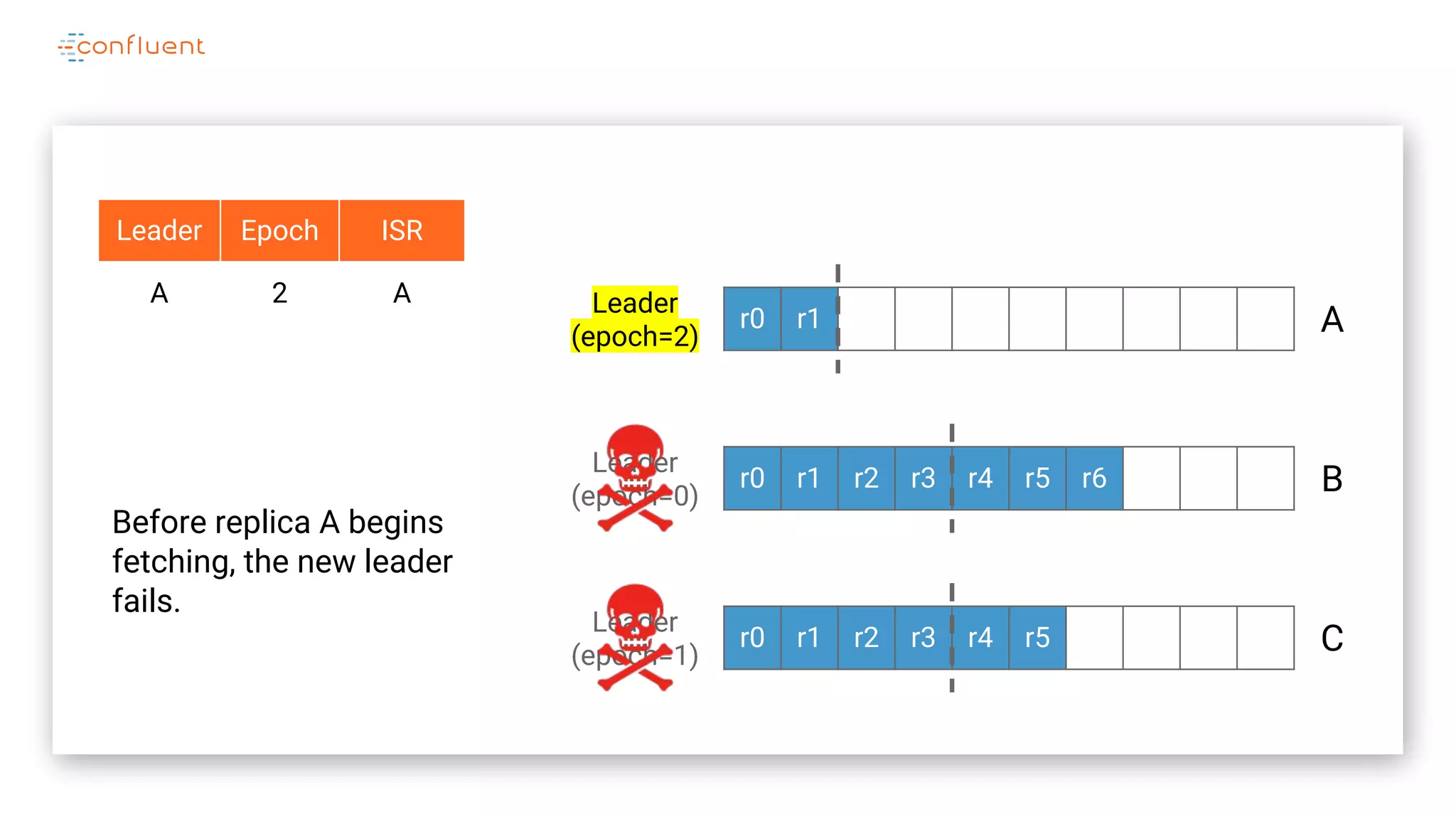
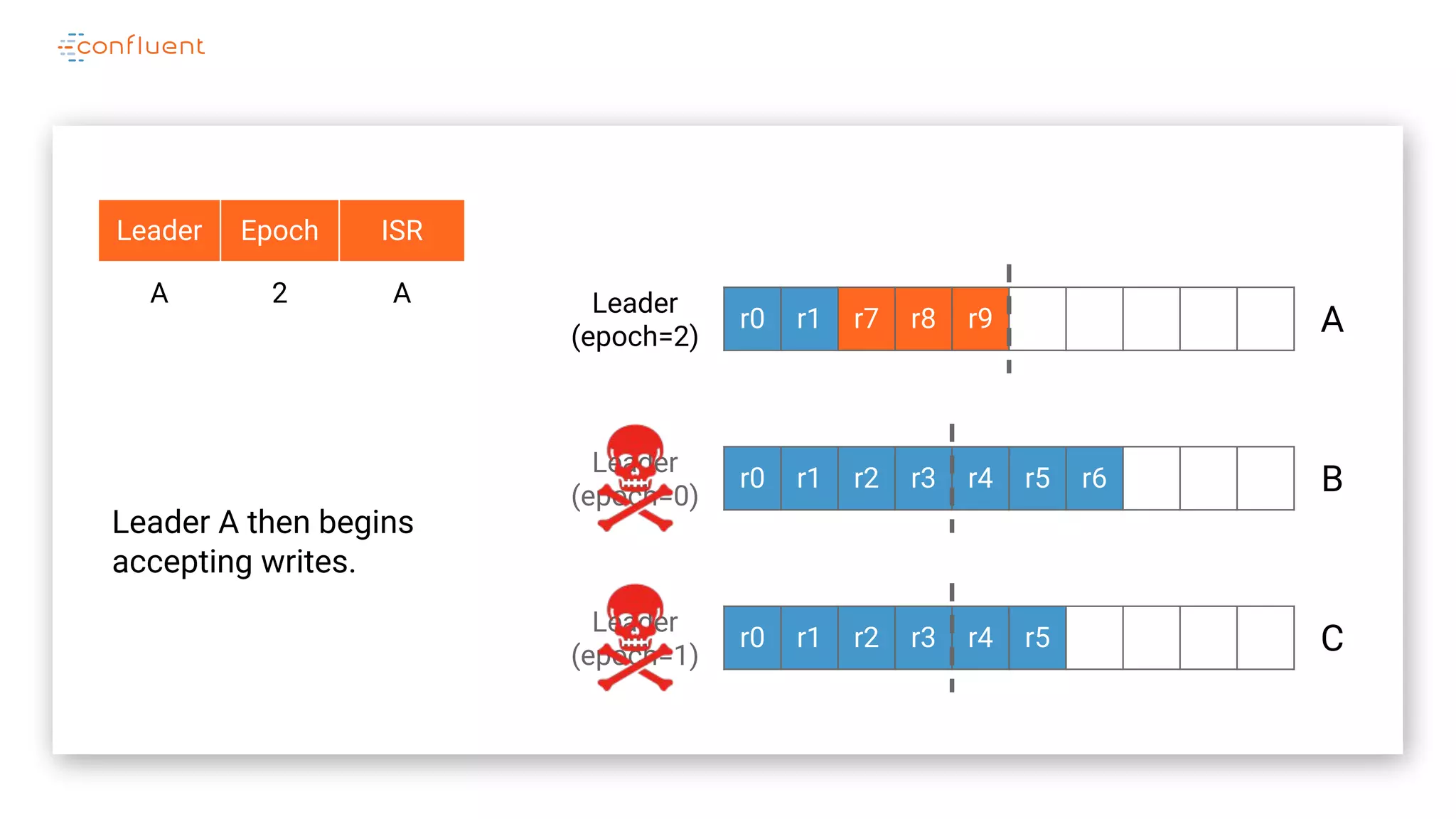
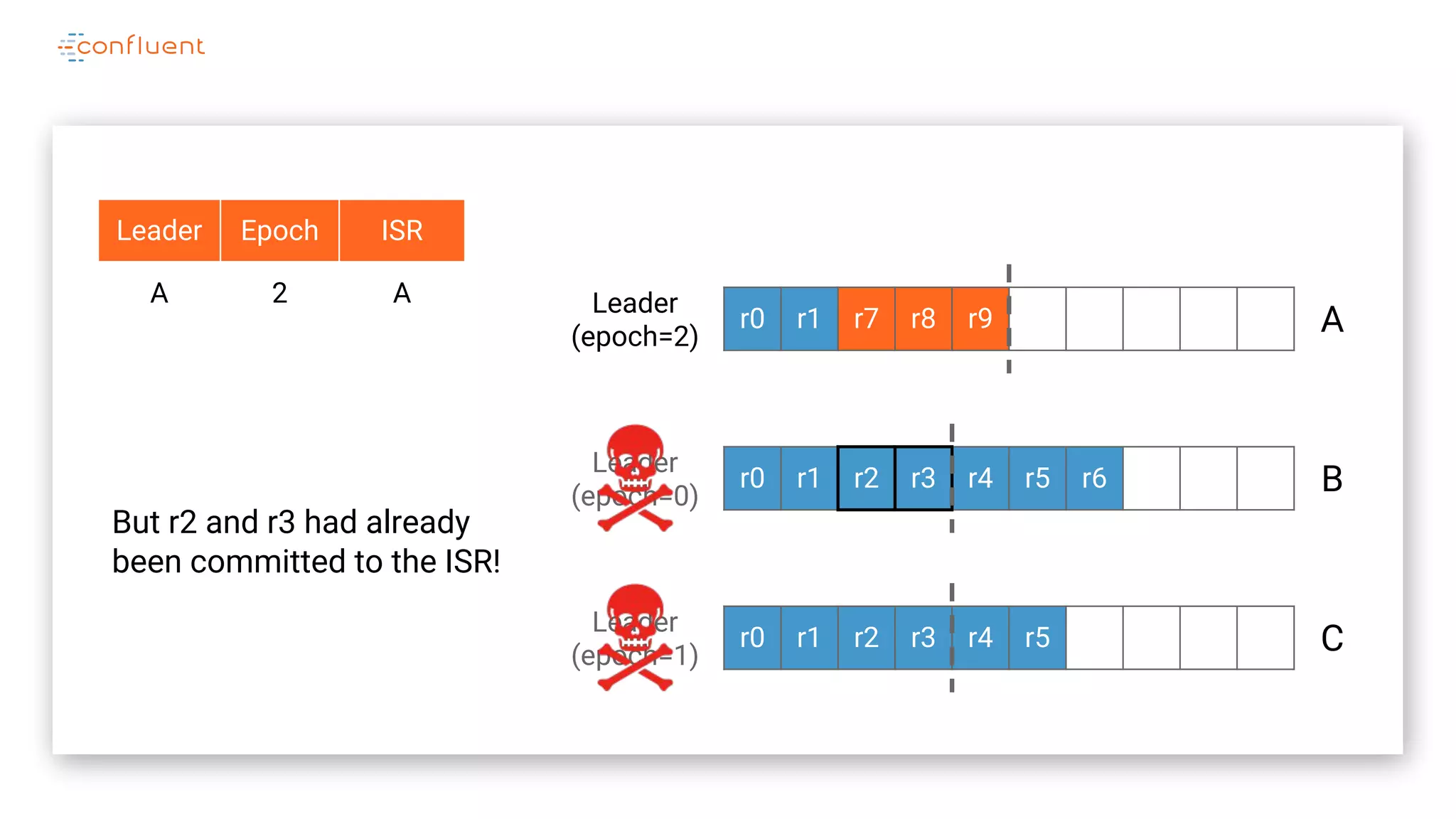
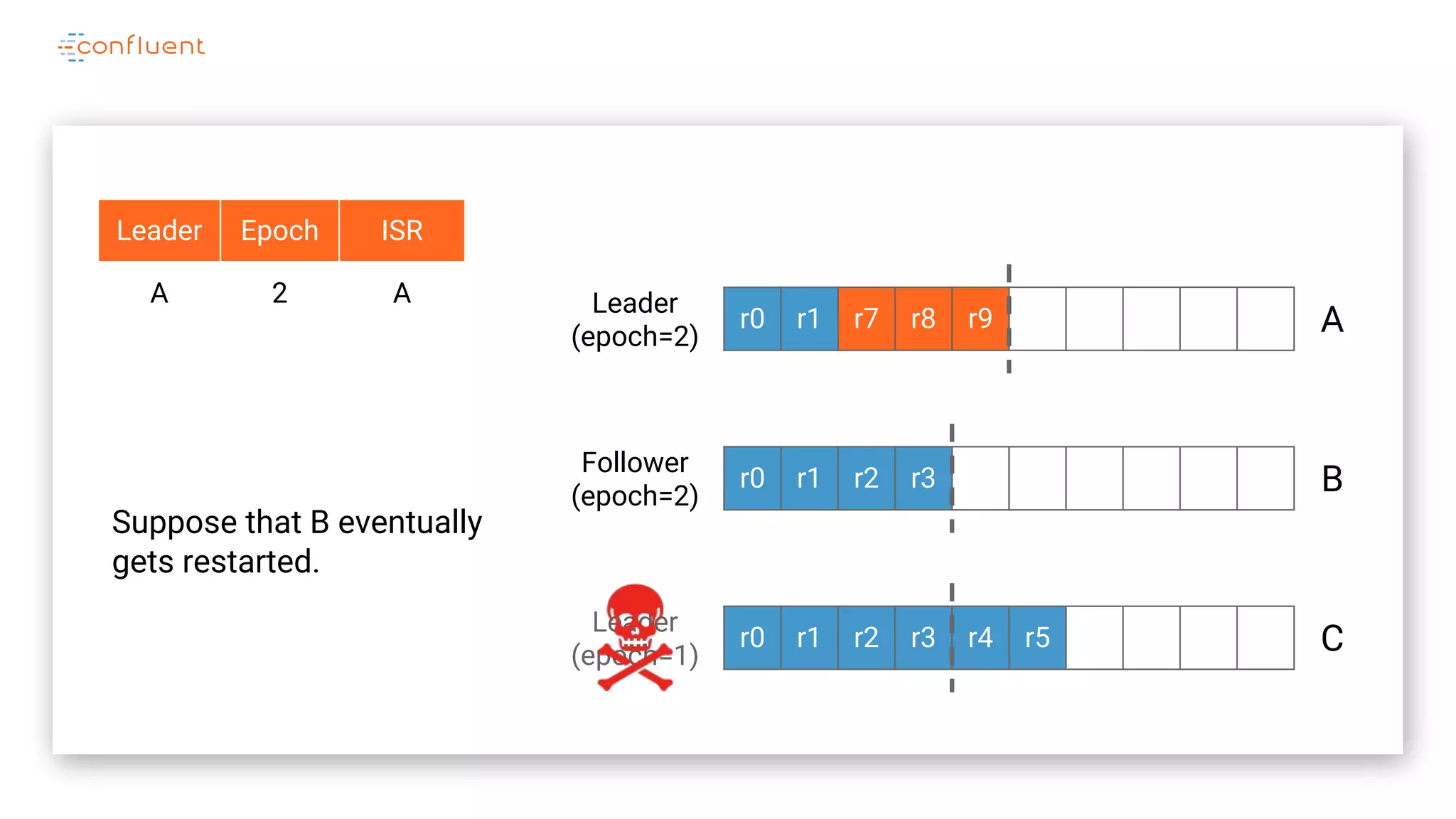
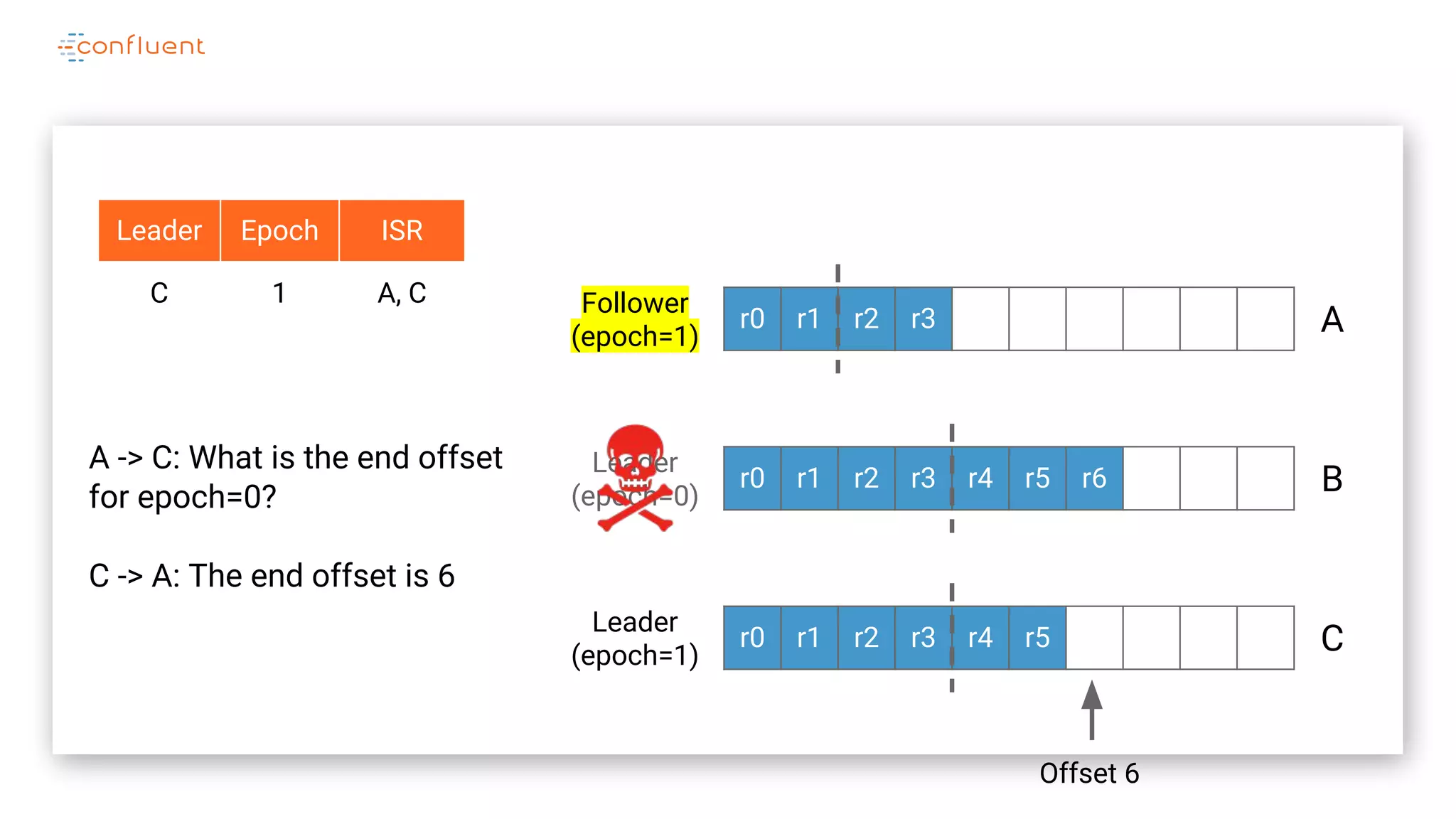
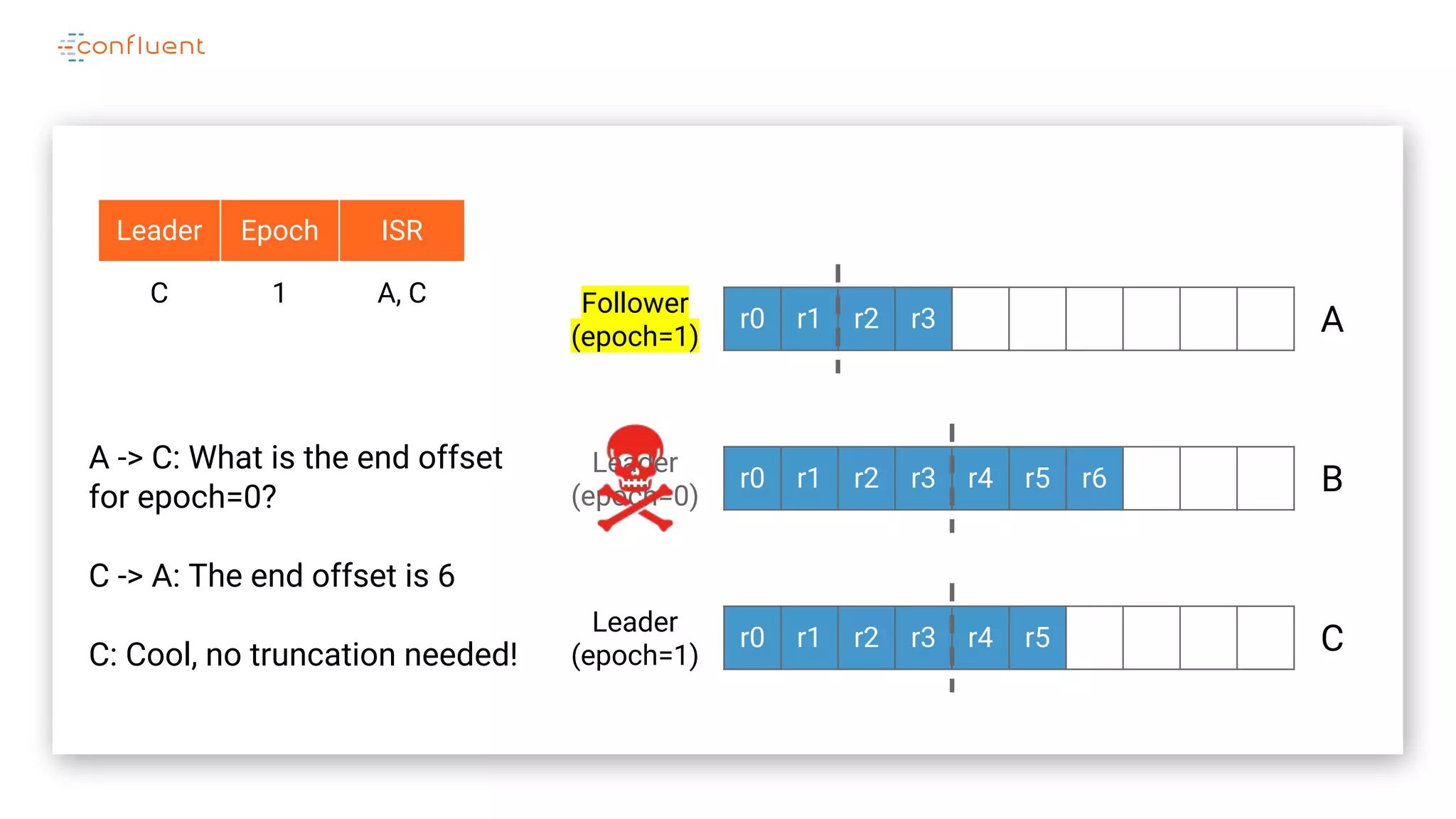
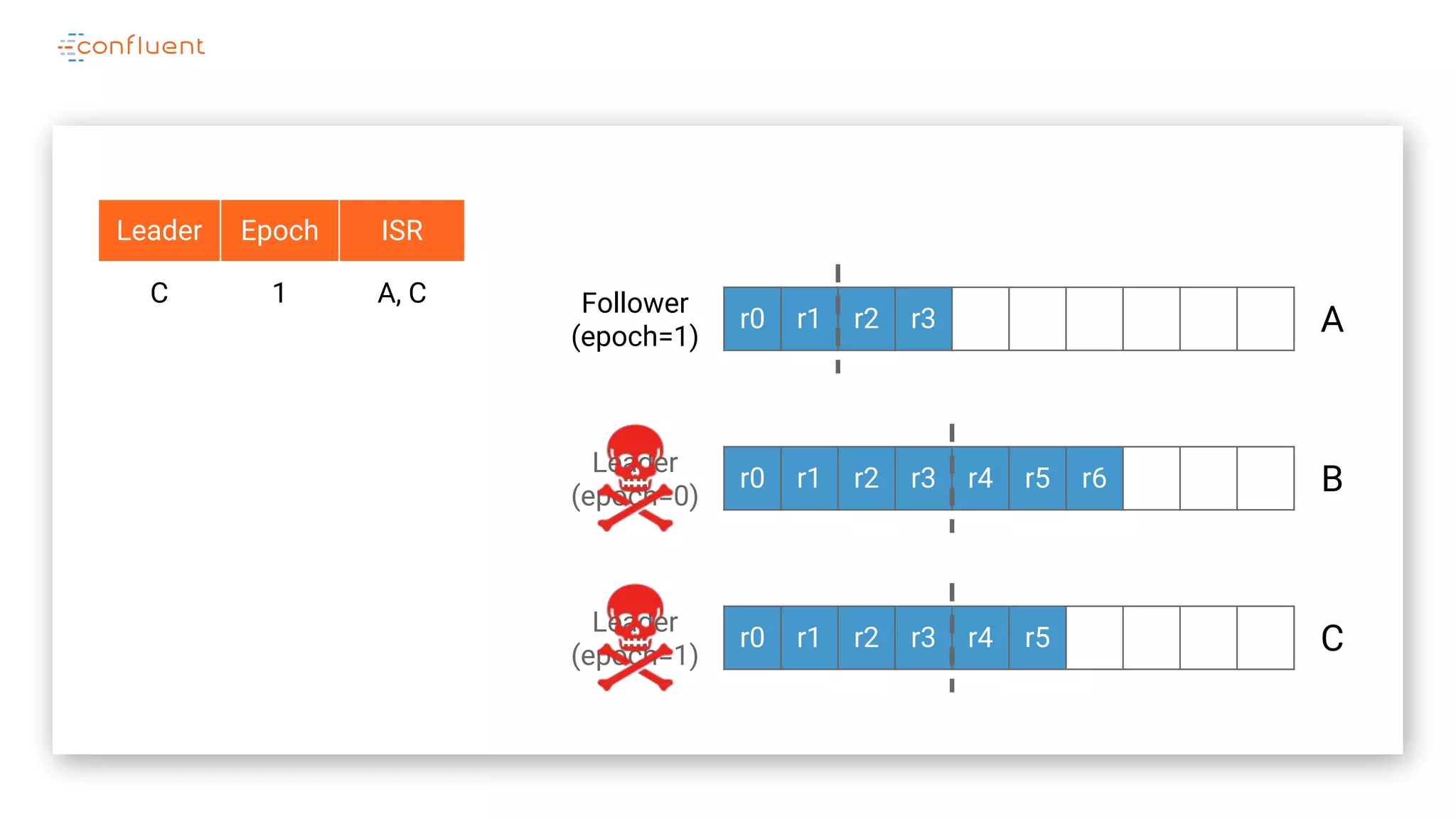
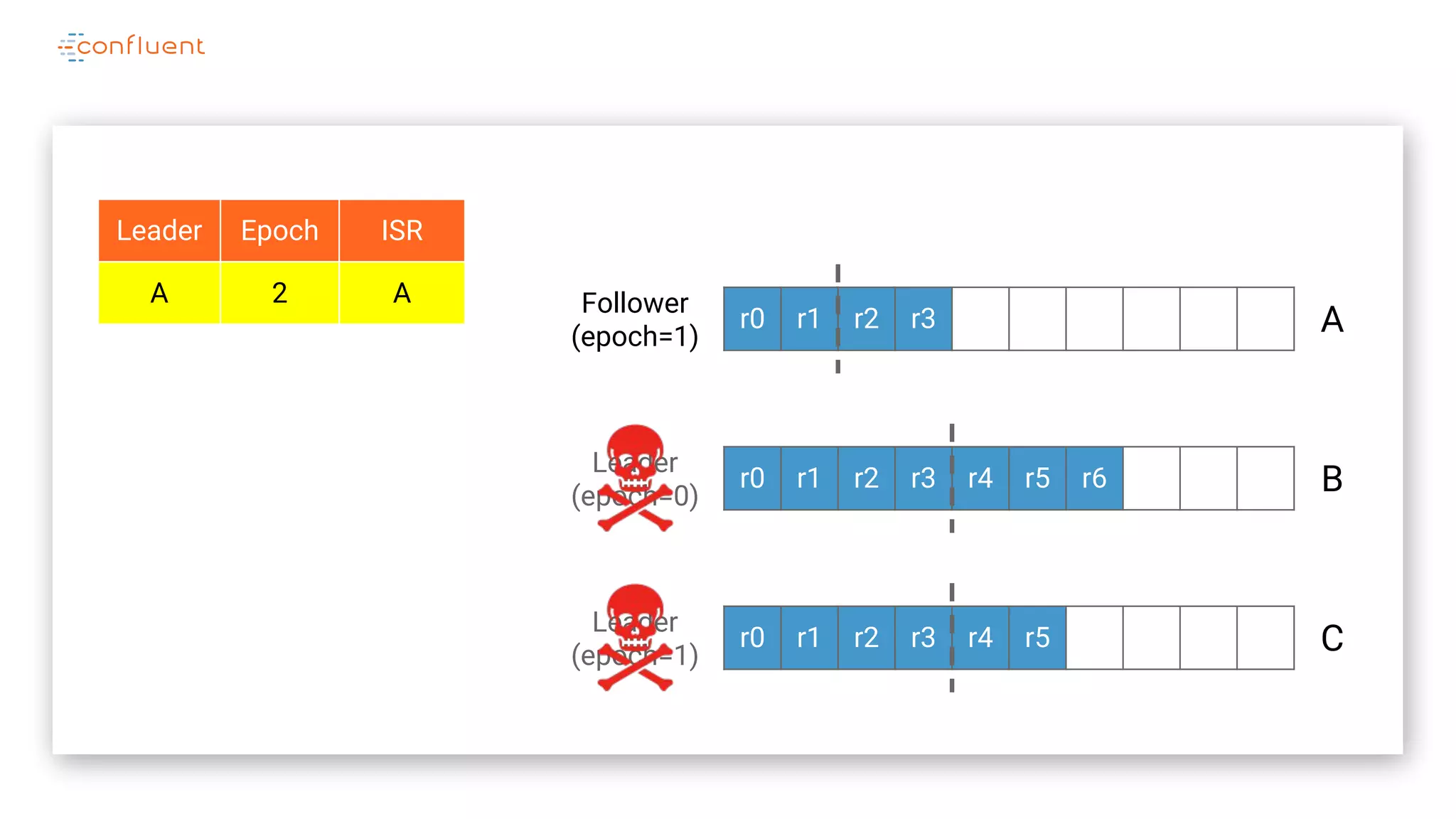
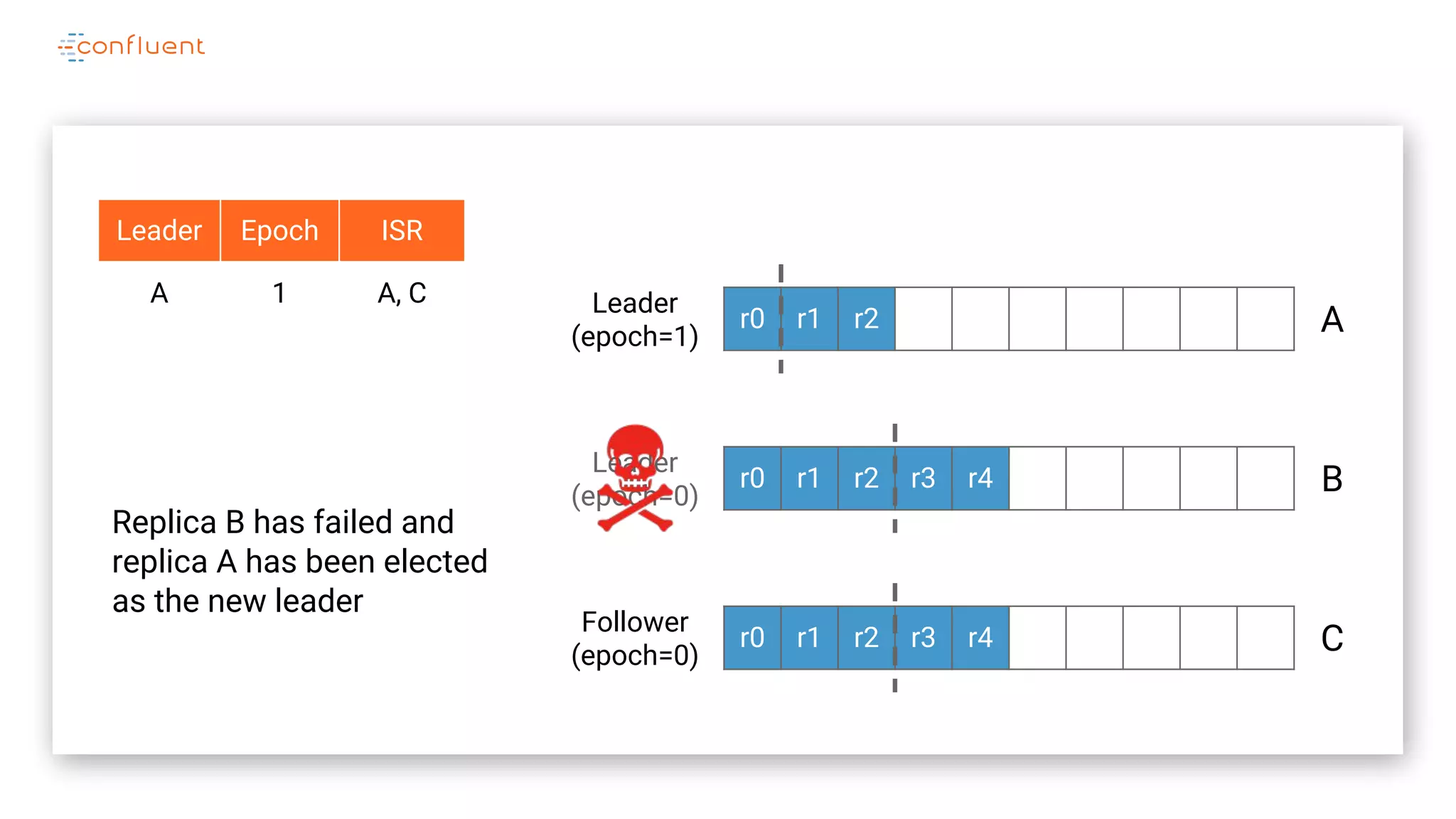
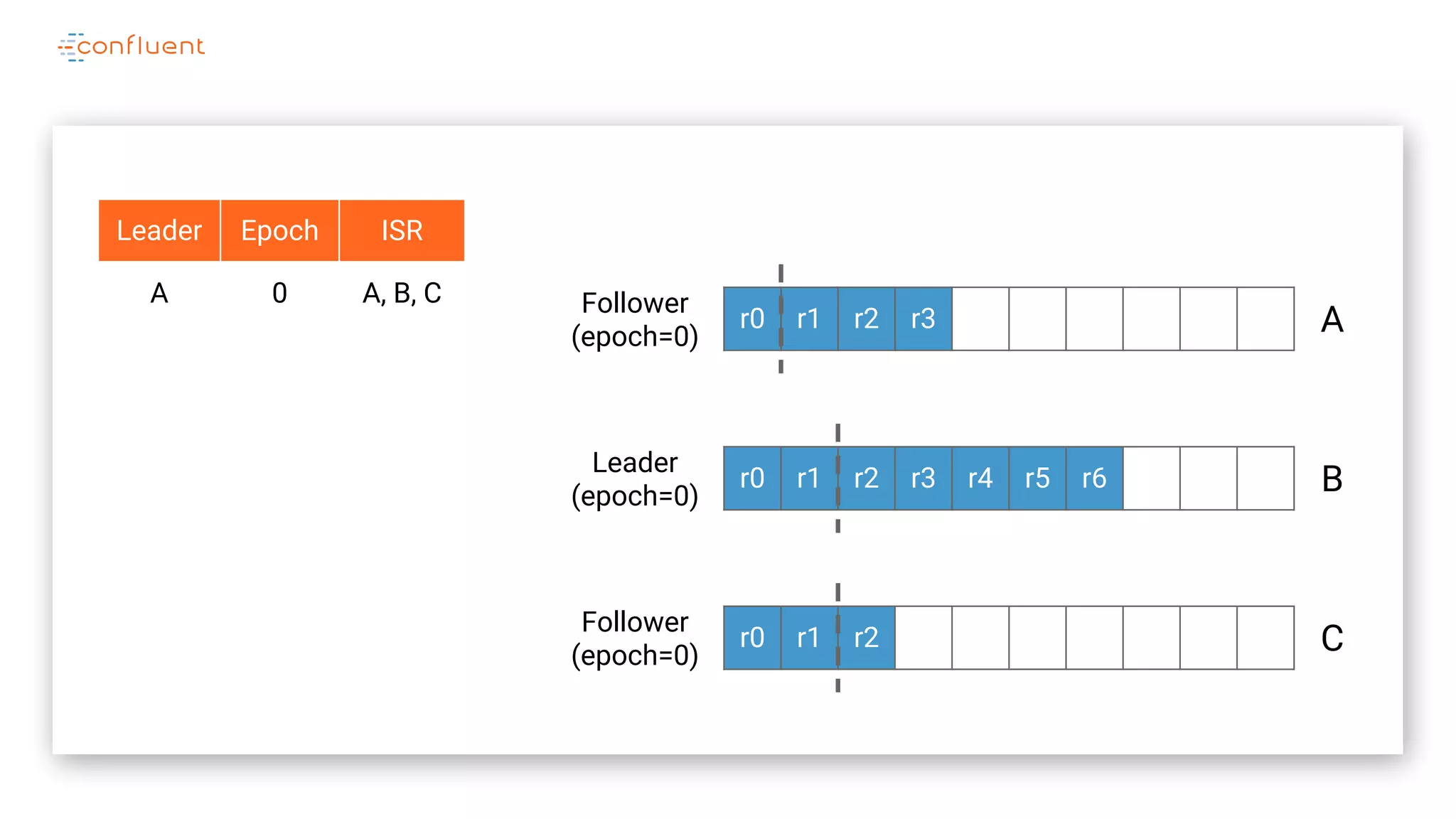
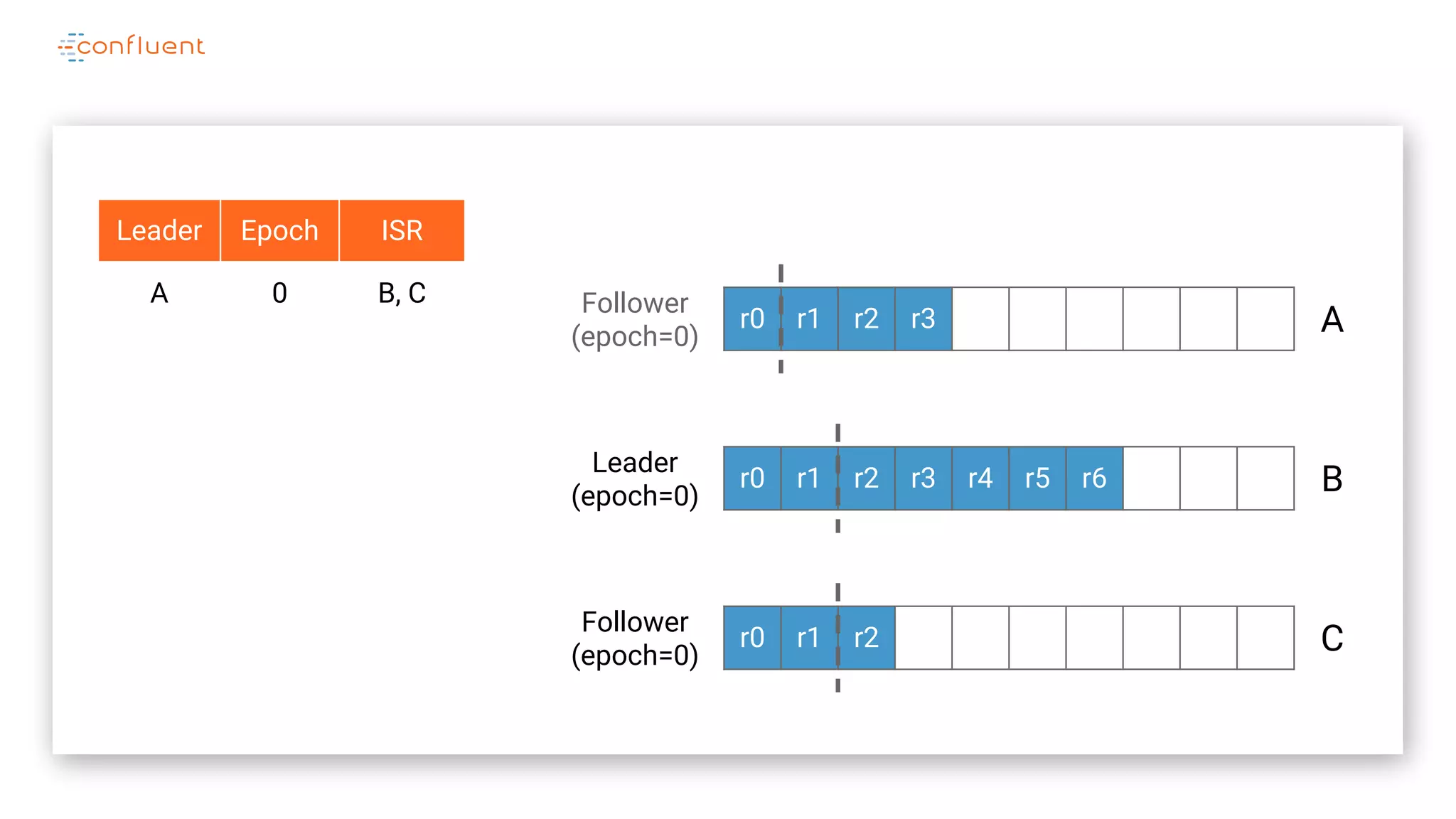
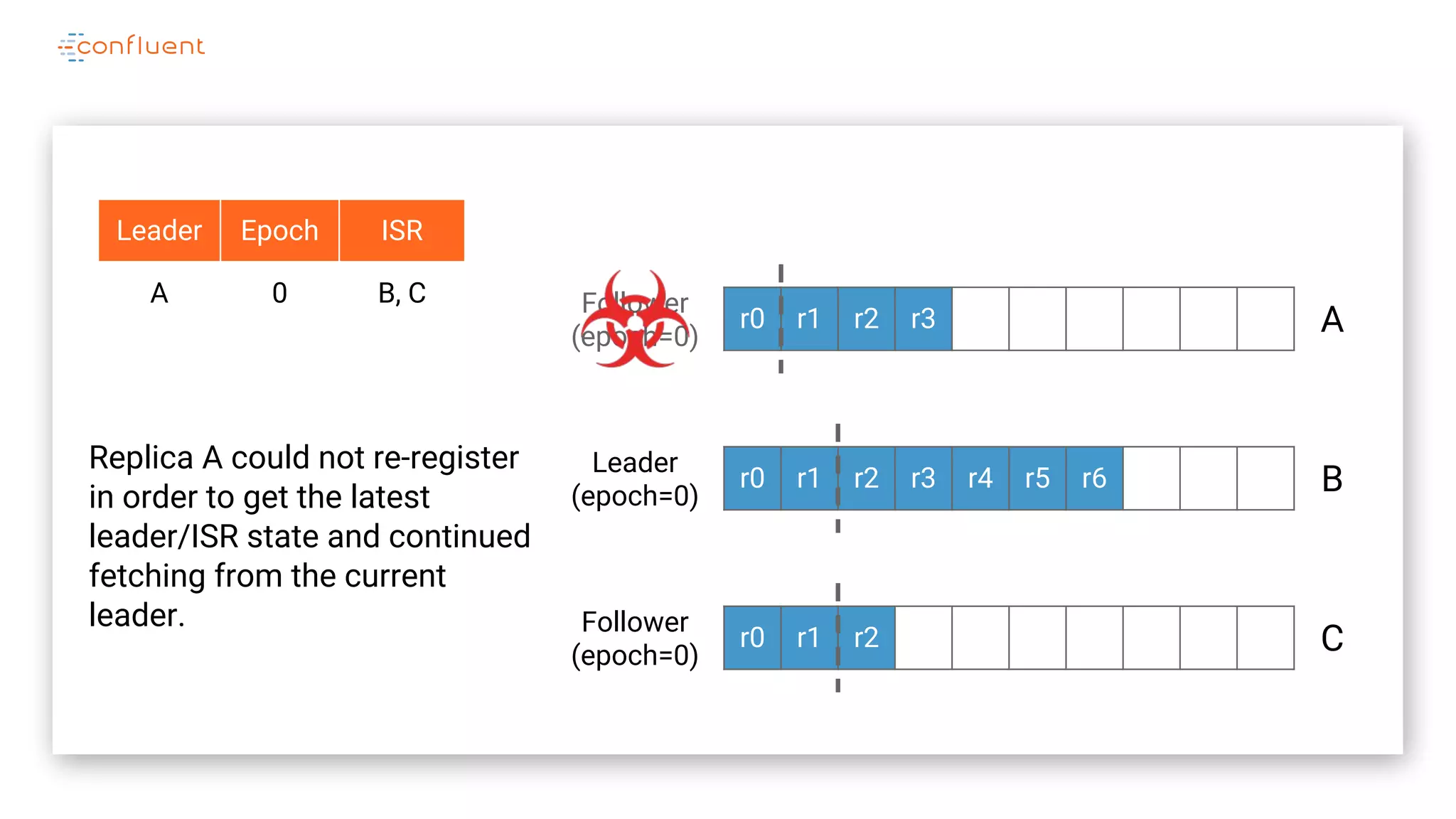
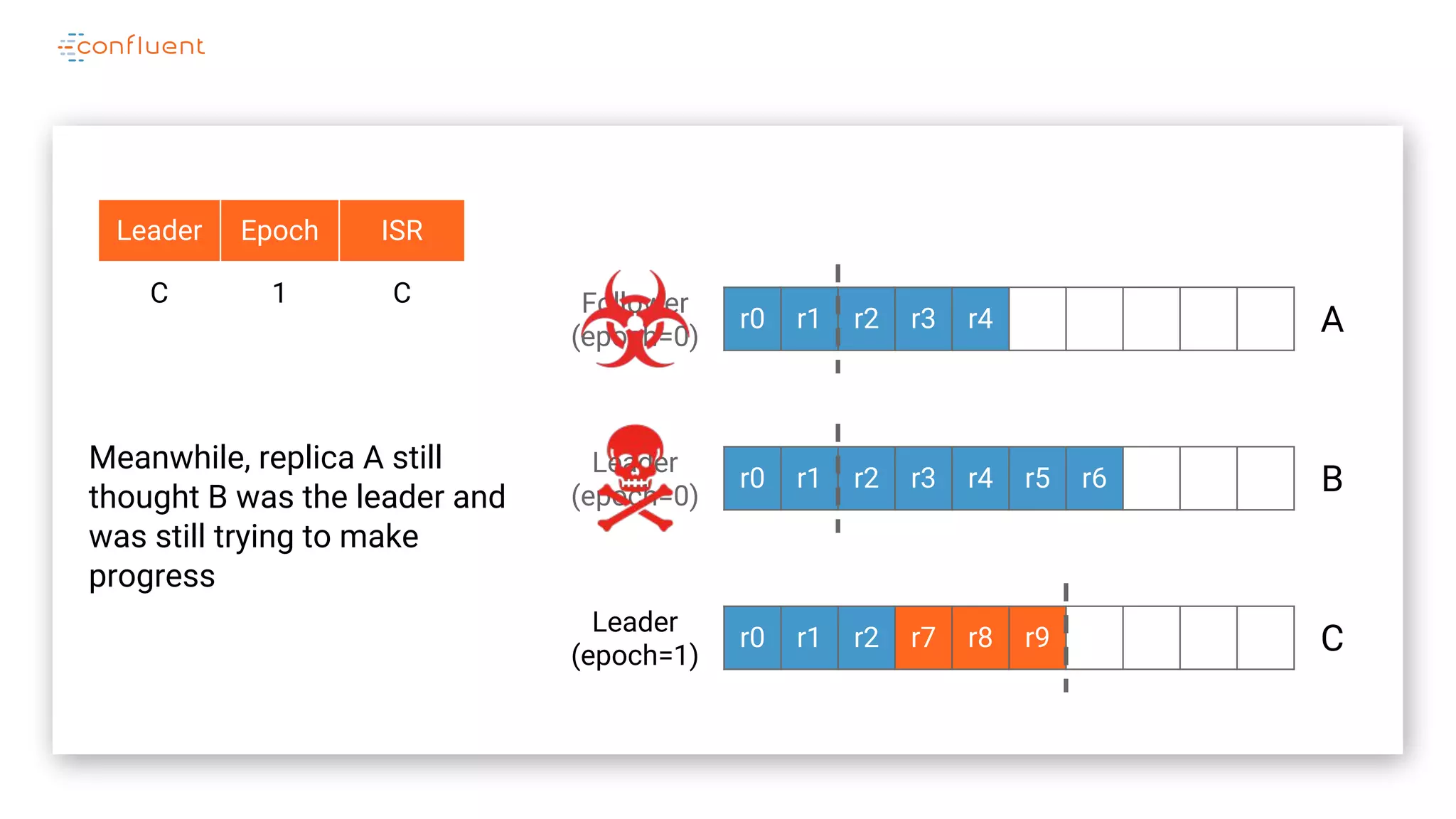
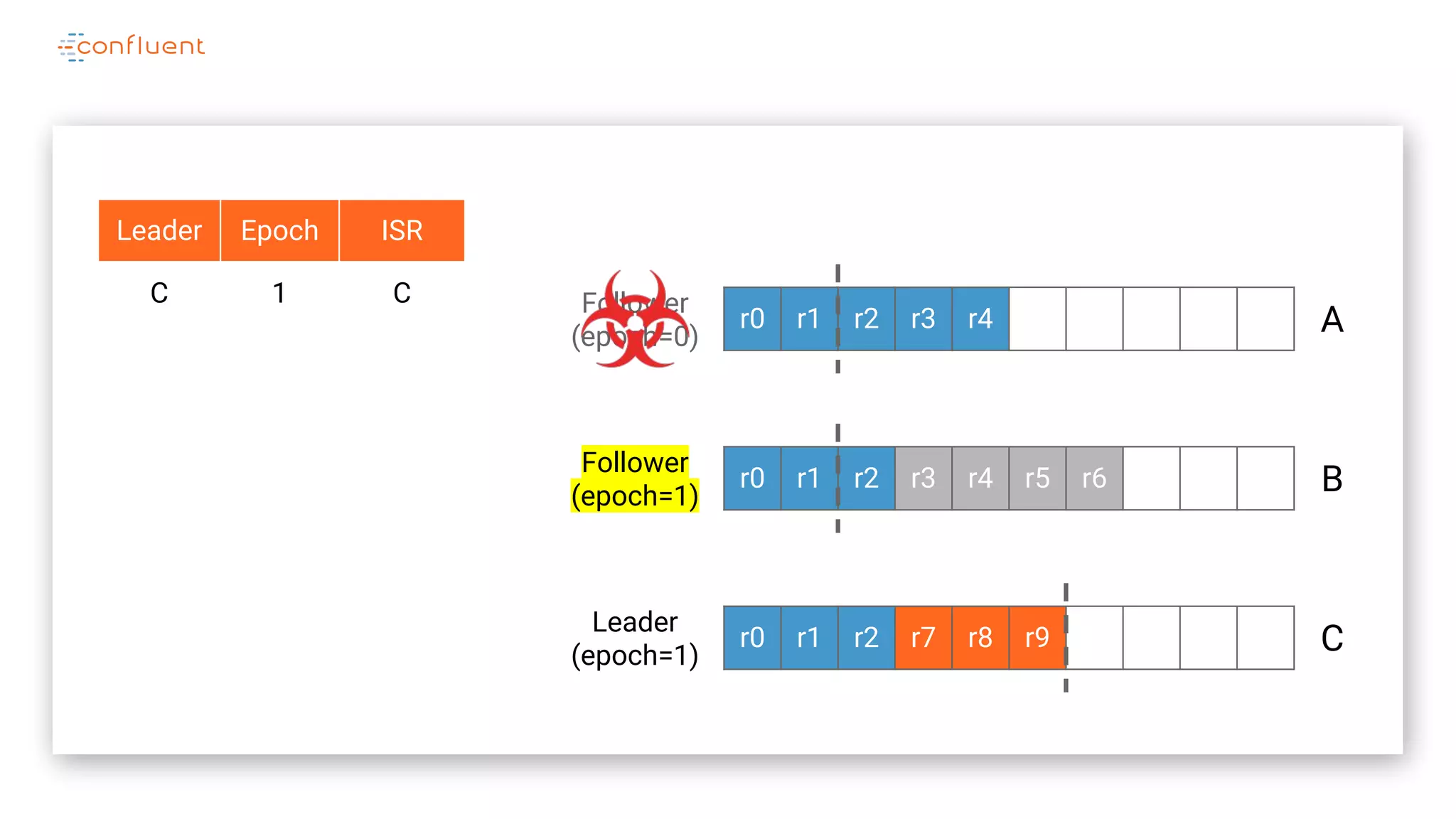
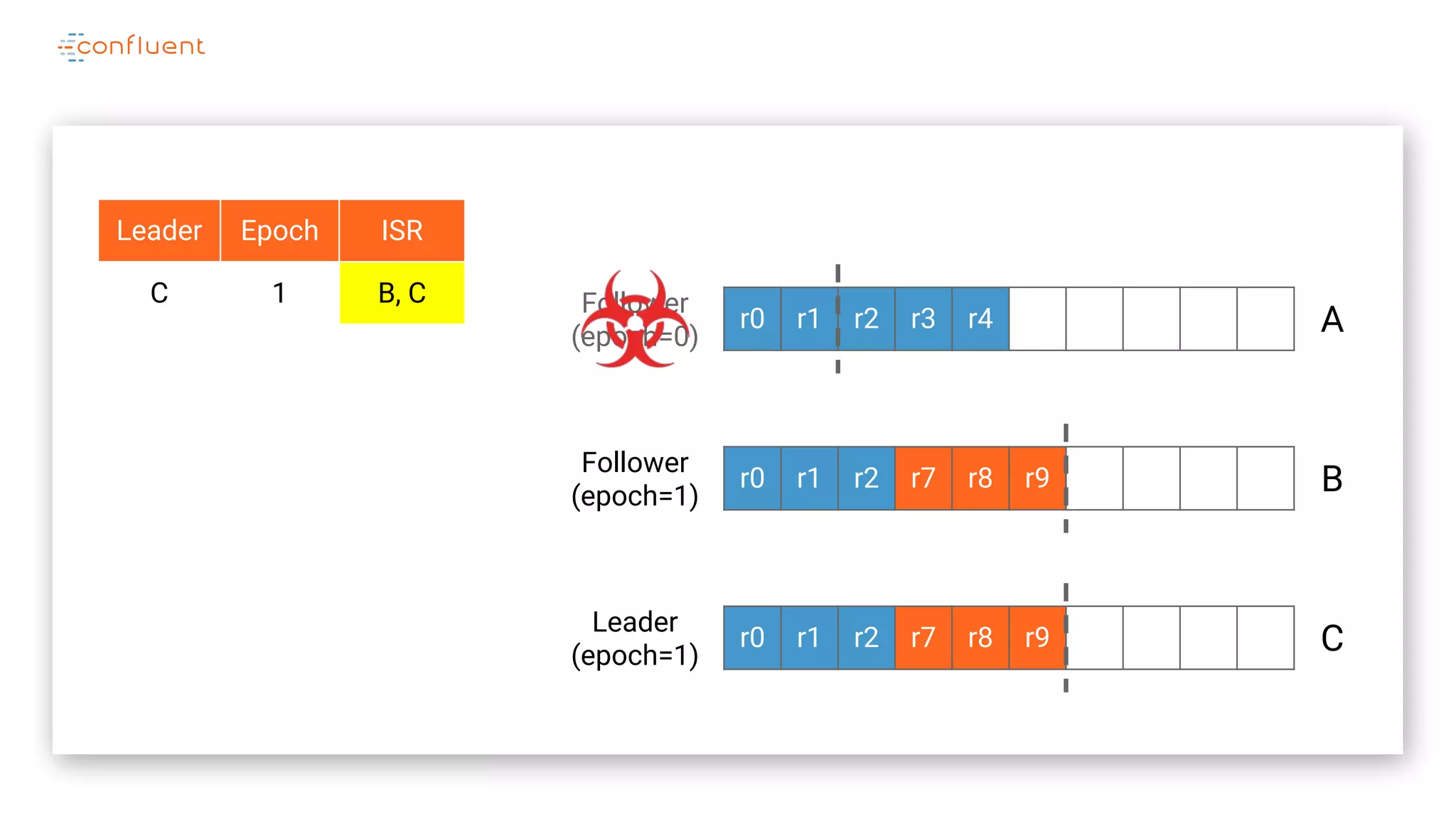
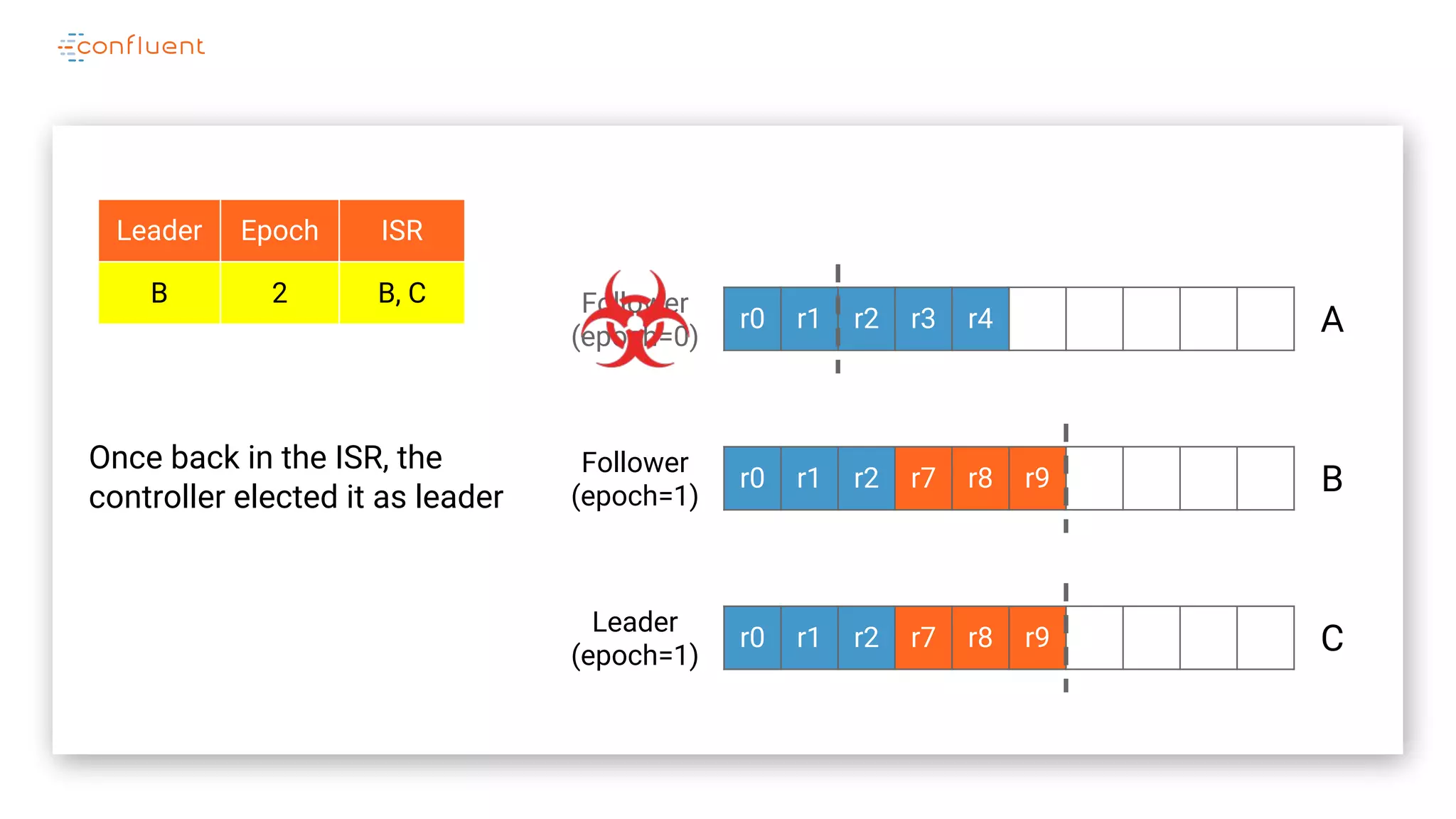
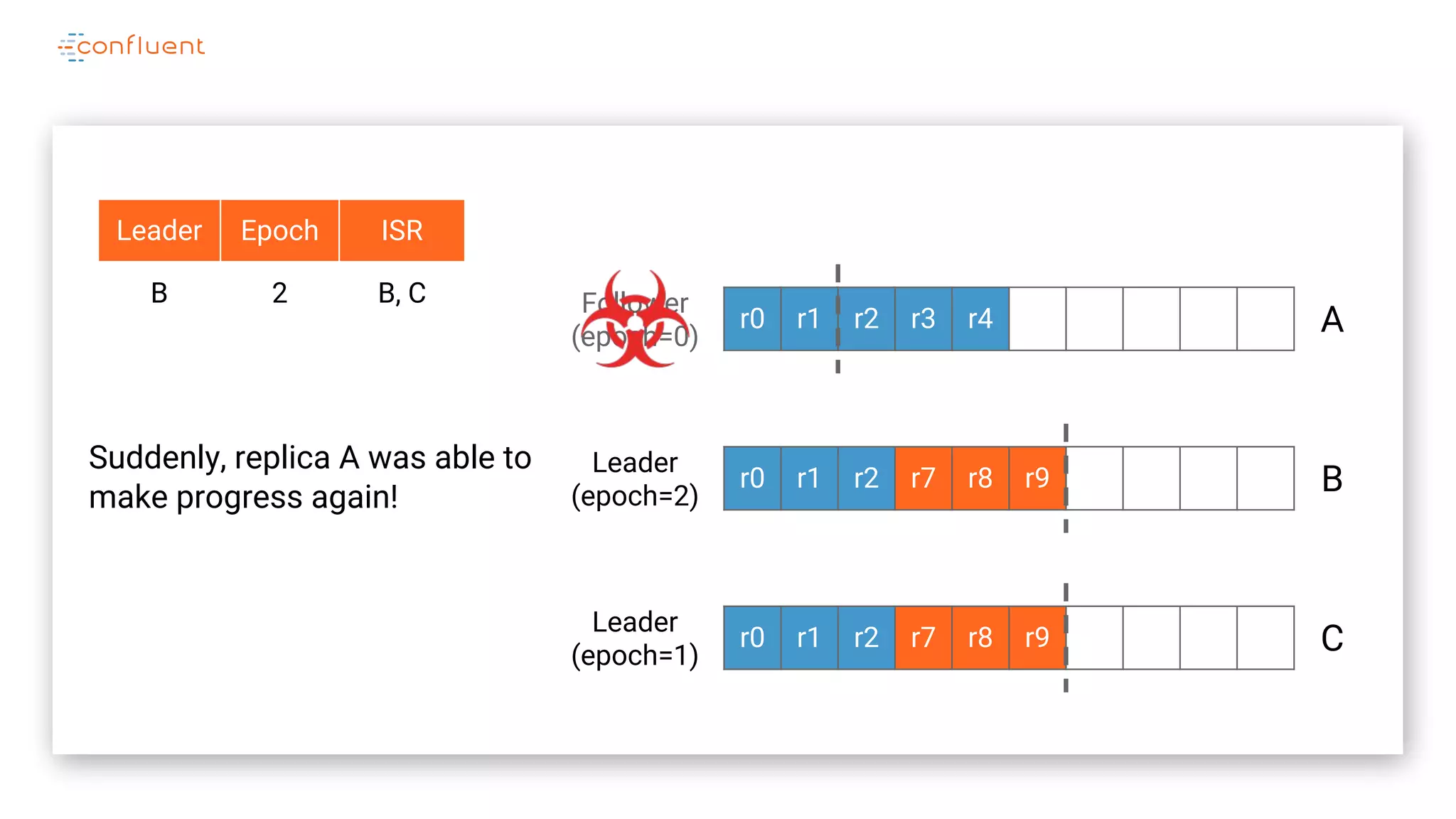
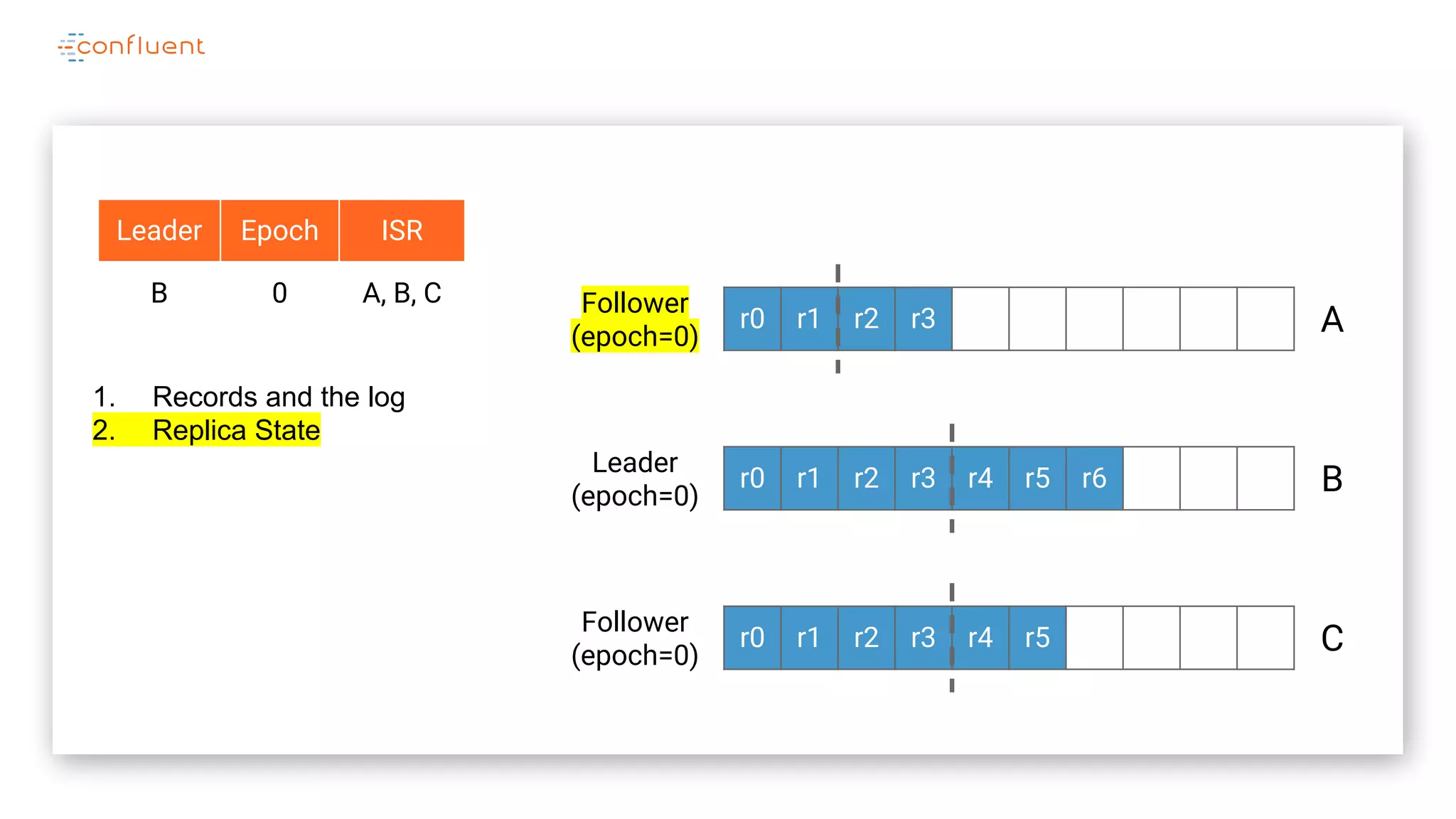
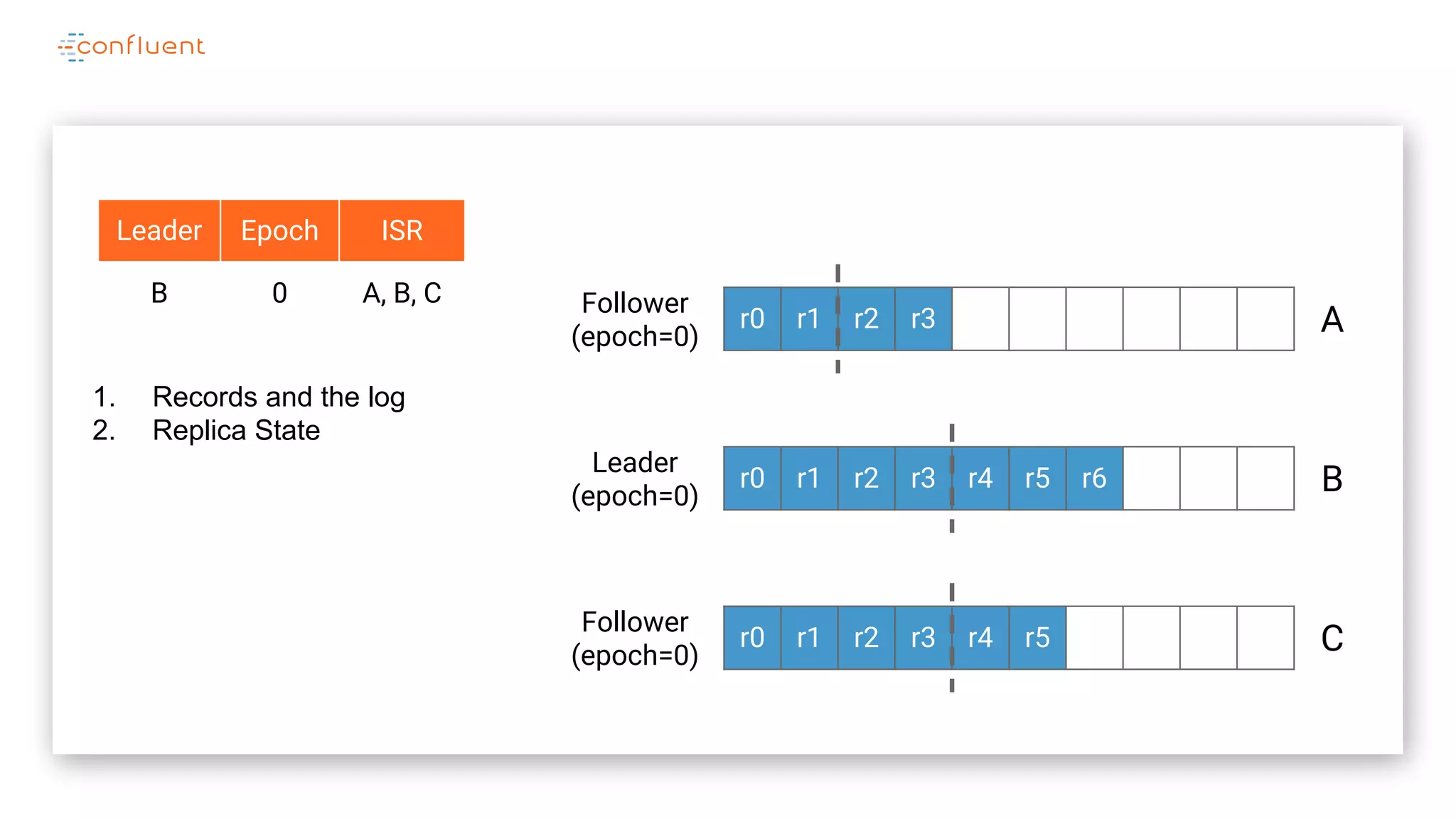
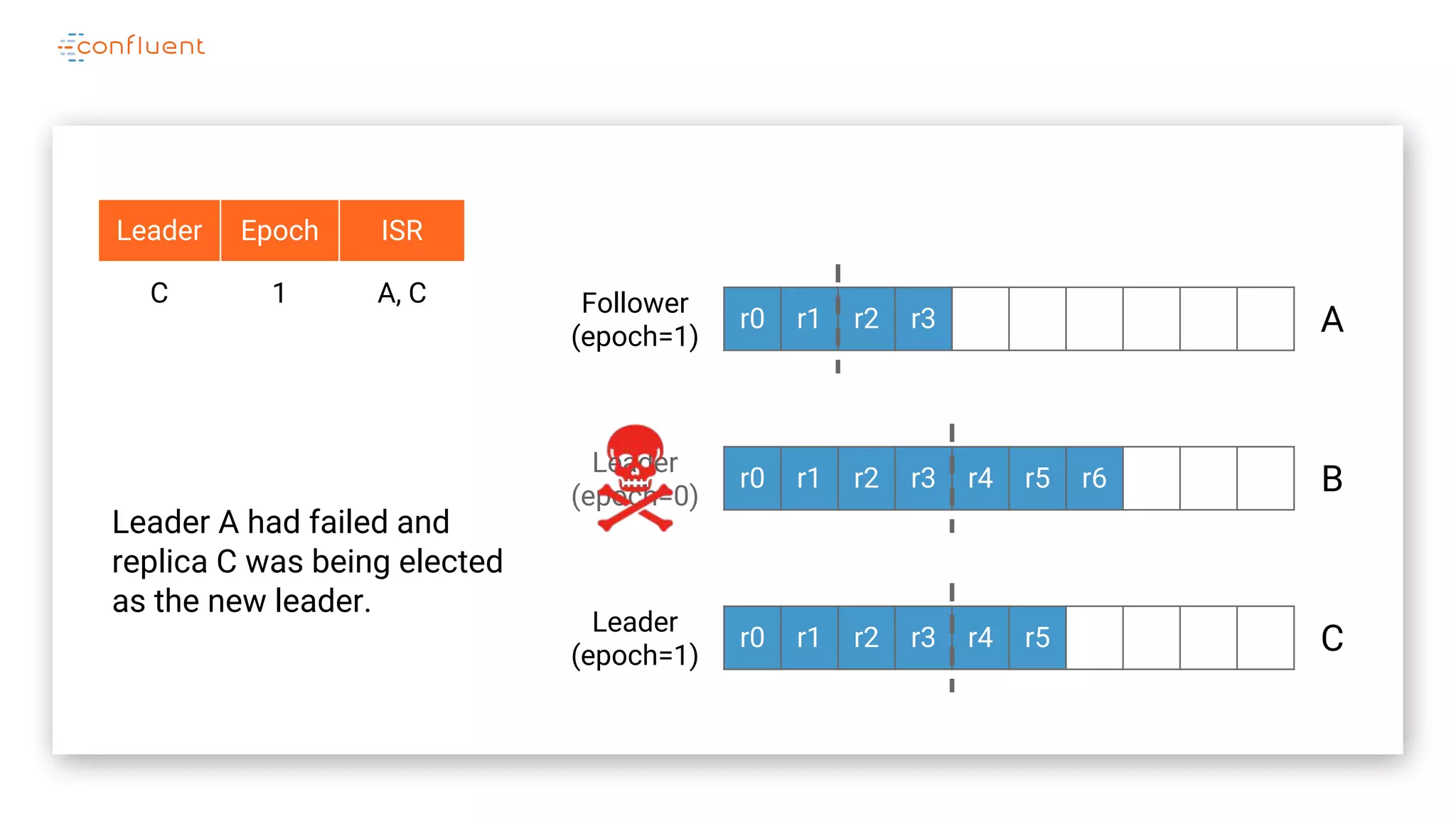
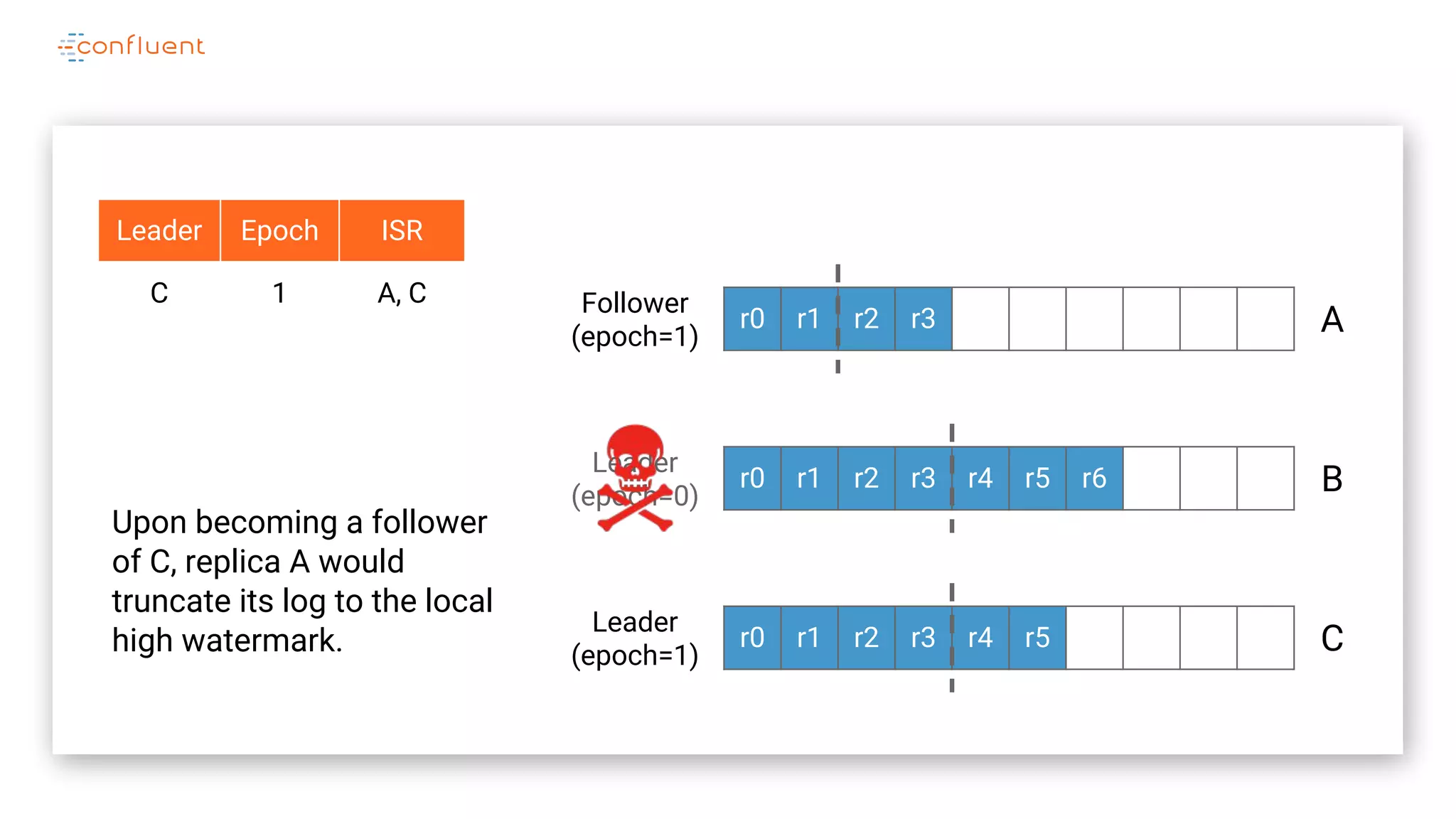
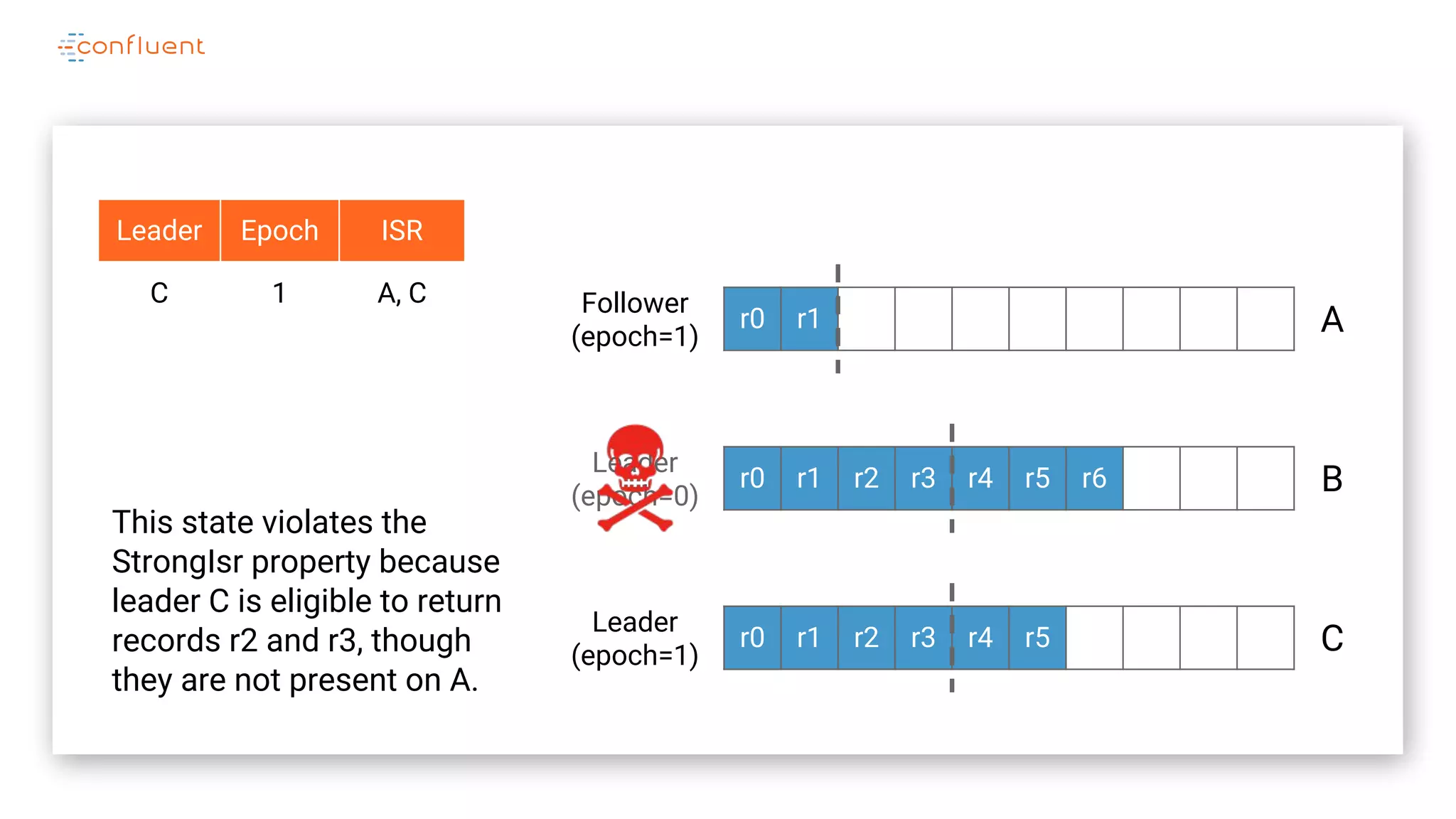
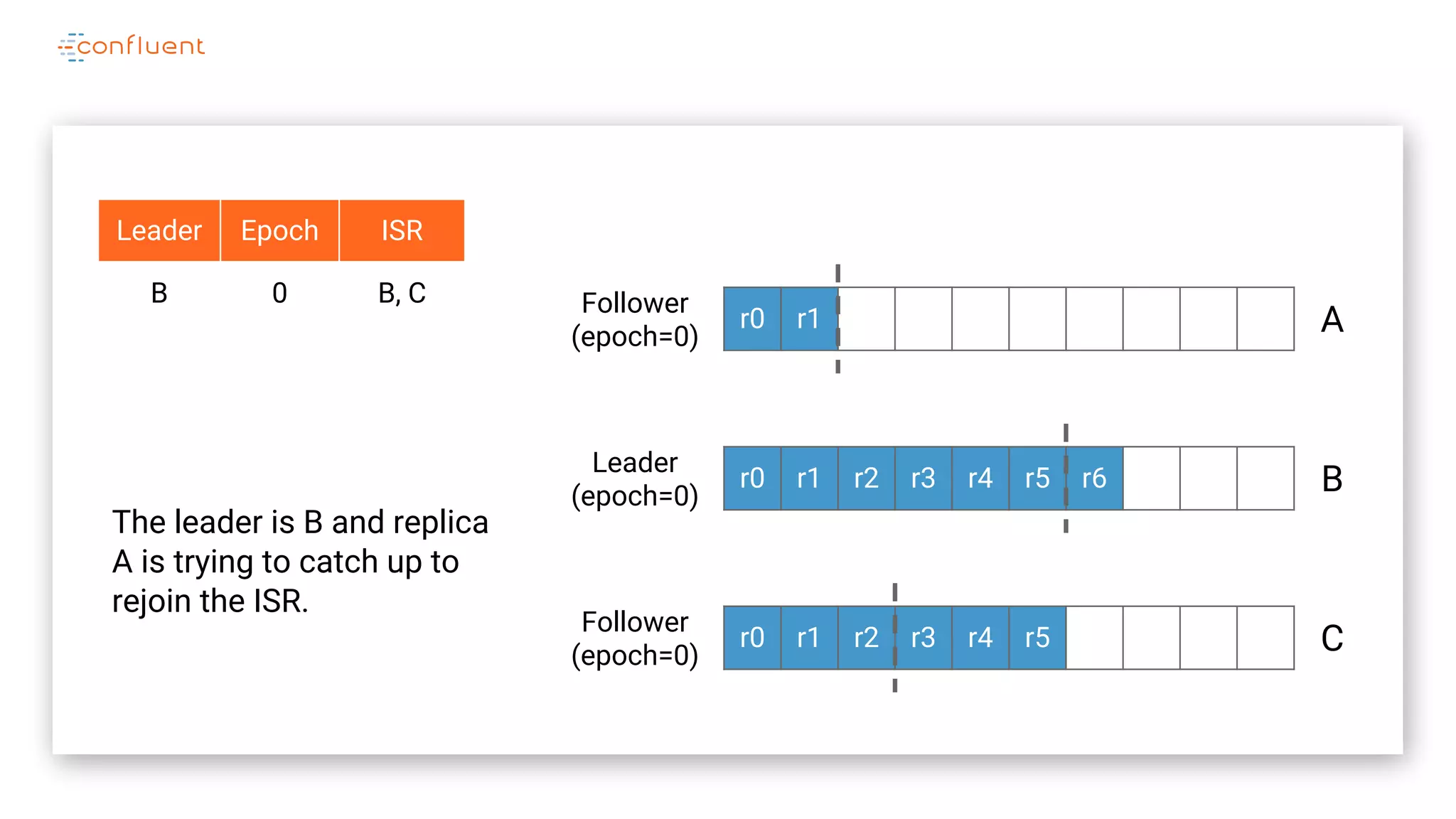
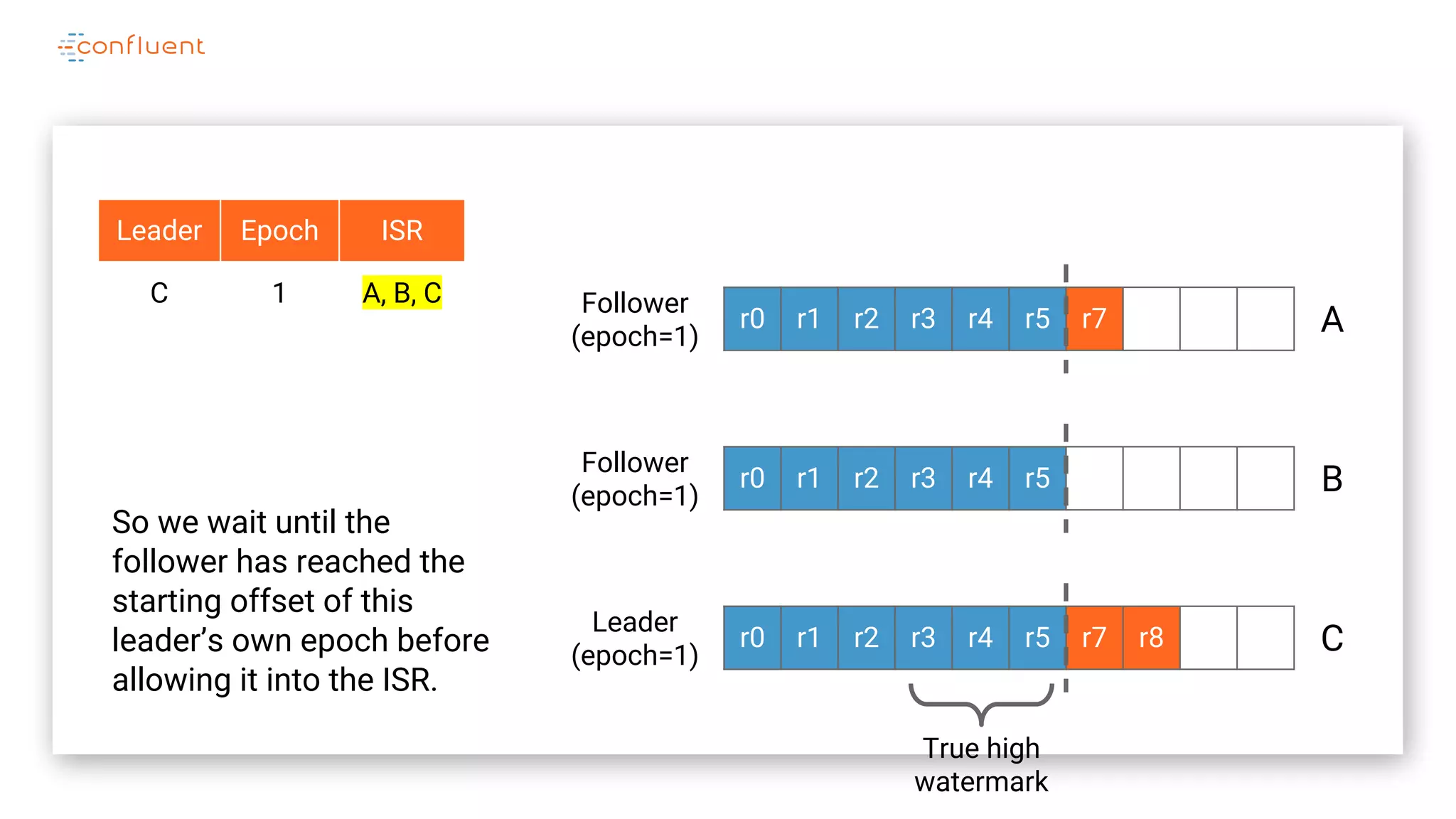
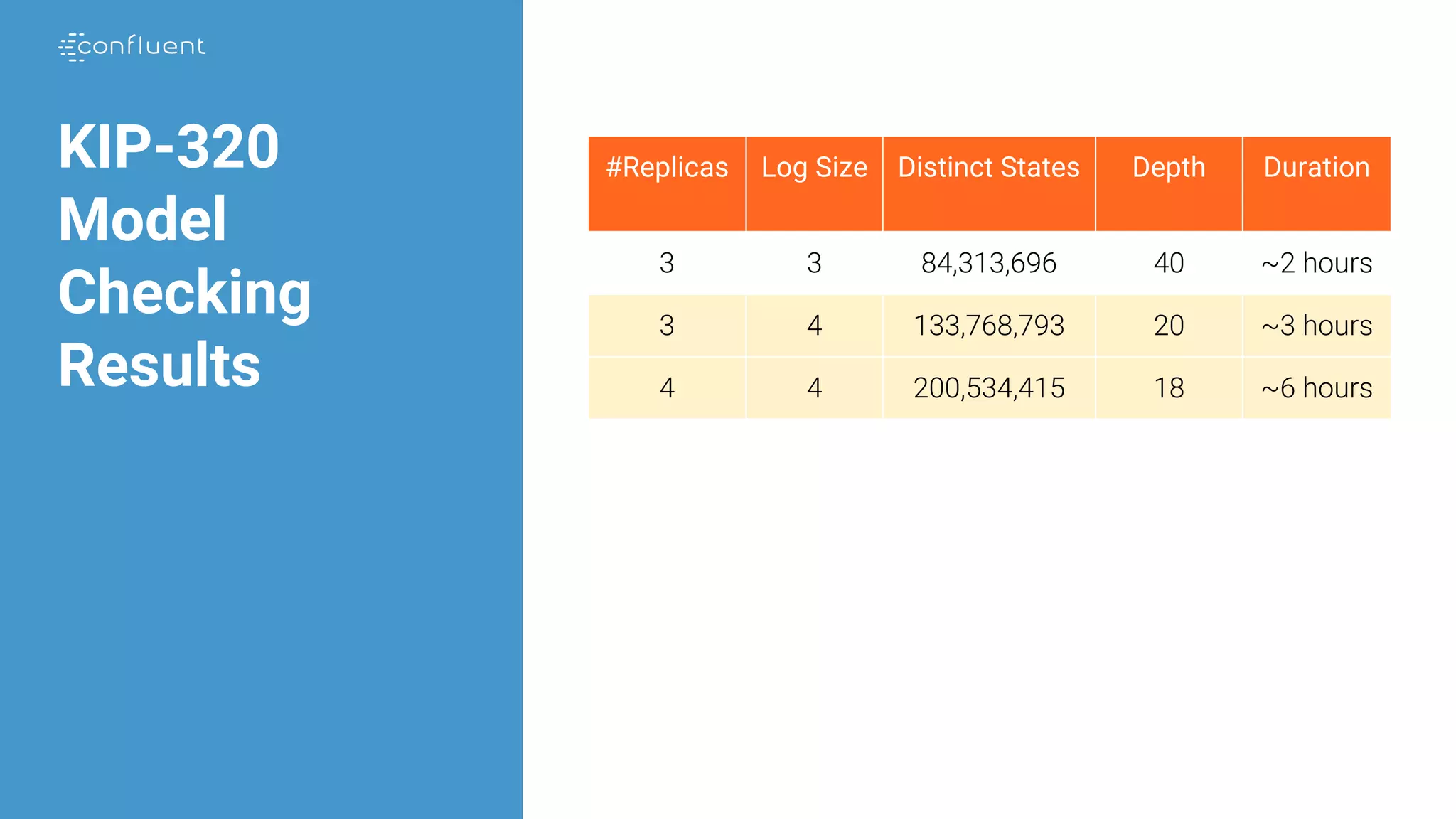
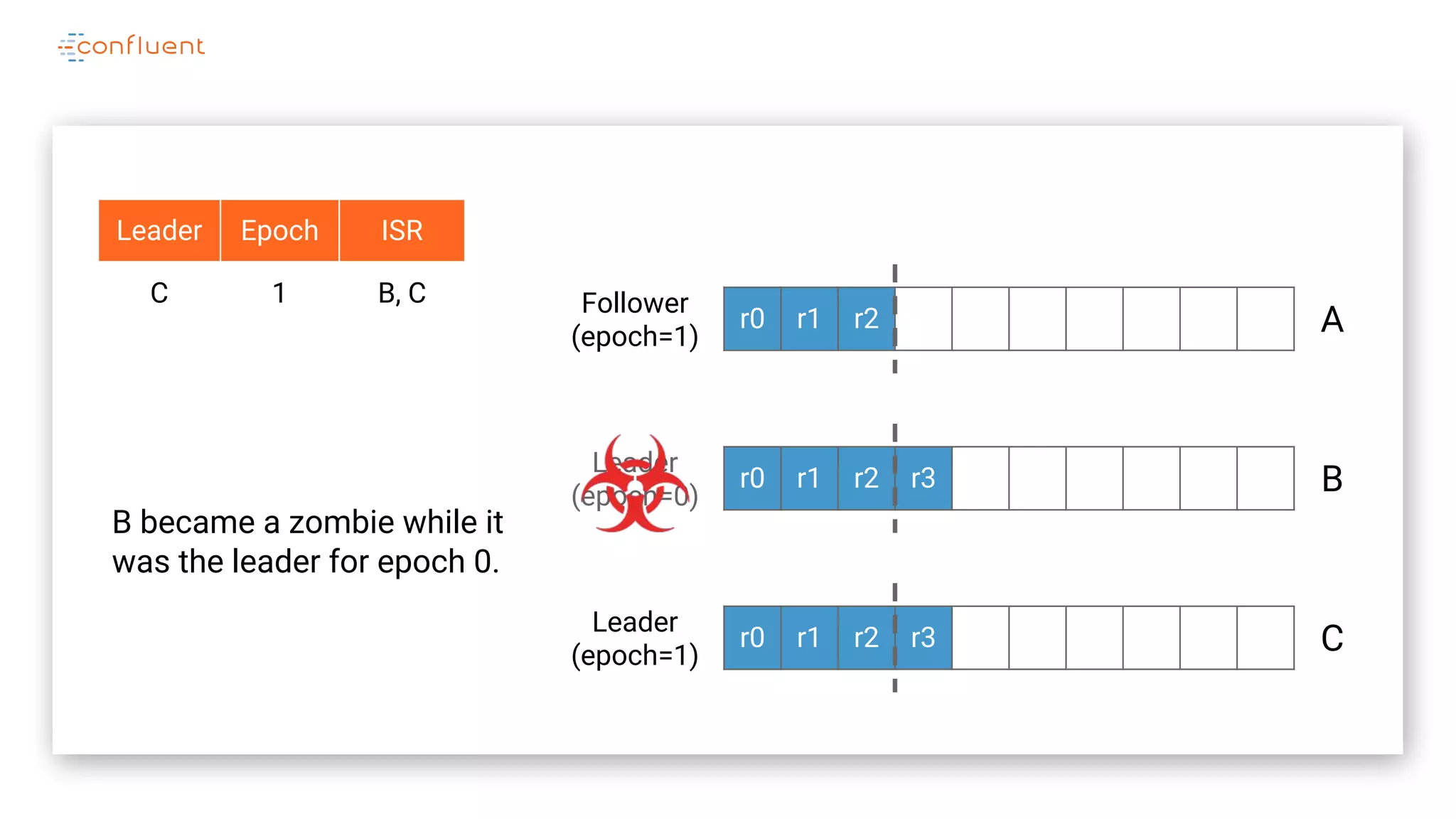
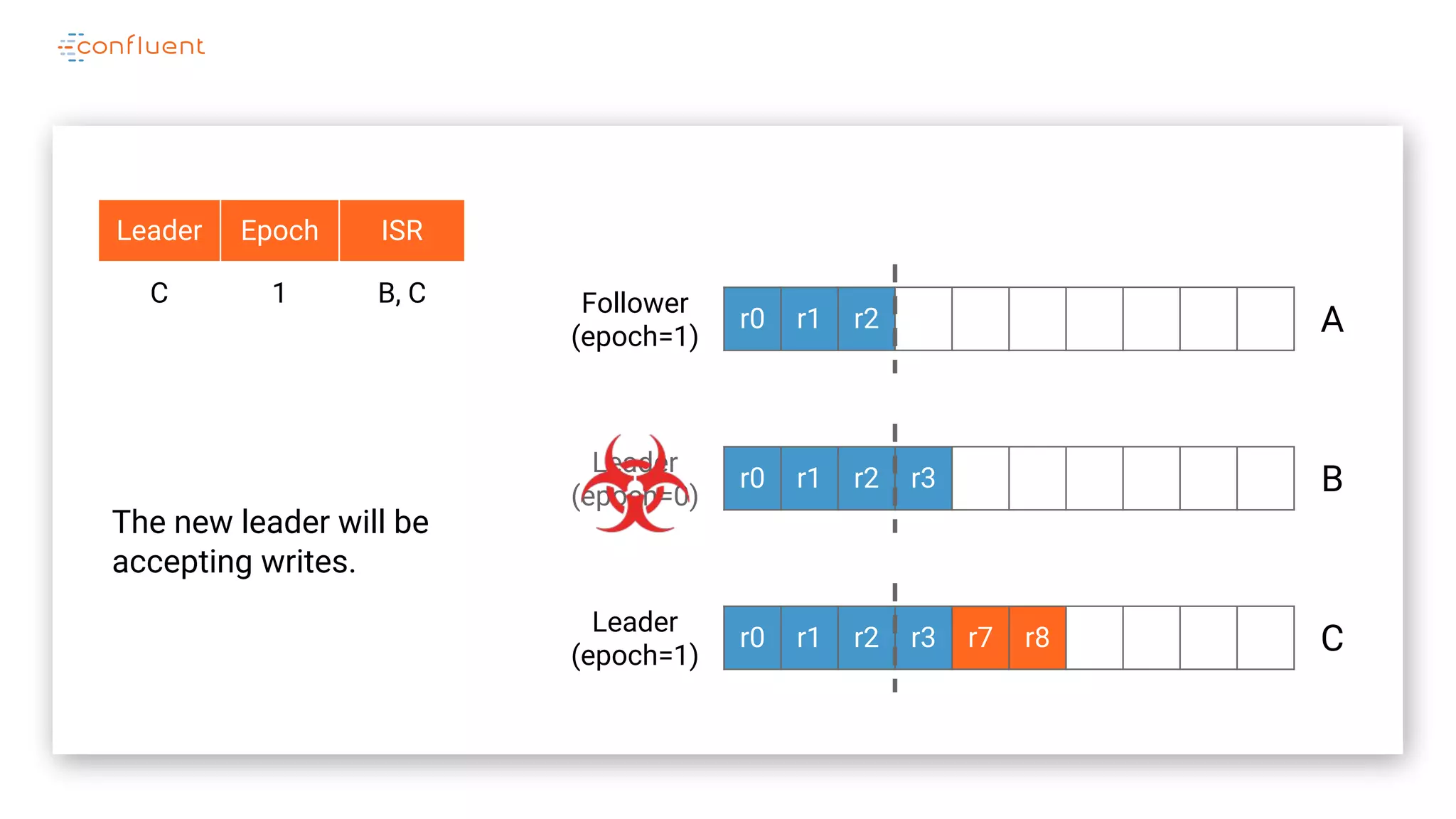
The document details Kafka's log replication mechanism, emphasizing its high availability and the protocol used for replicating logs across replicas. It describes the roles of leaders and followers, the state management with ZooKeeper, the concept of in-sync replicas (ISR), and how the high watermark is tracked for managing committed and uncommitted messages. Additionally, it highlights scenarios involving leader elections and the handling of replicas that fall behind or become out of sync.
























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















