Download to read offline

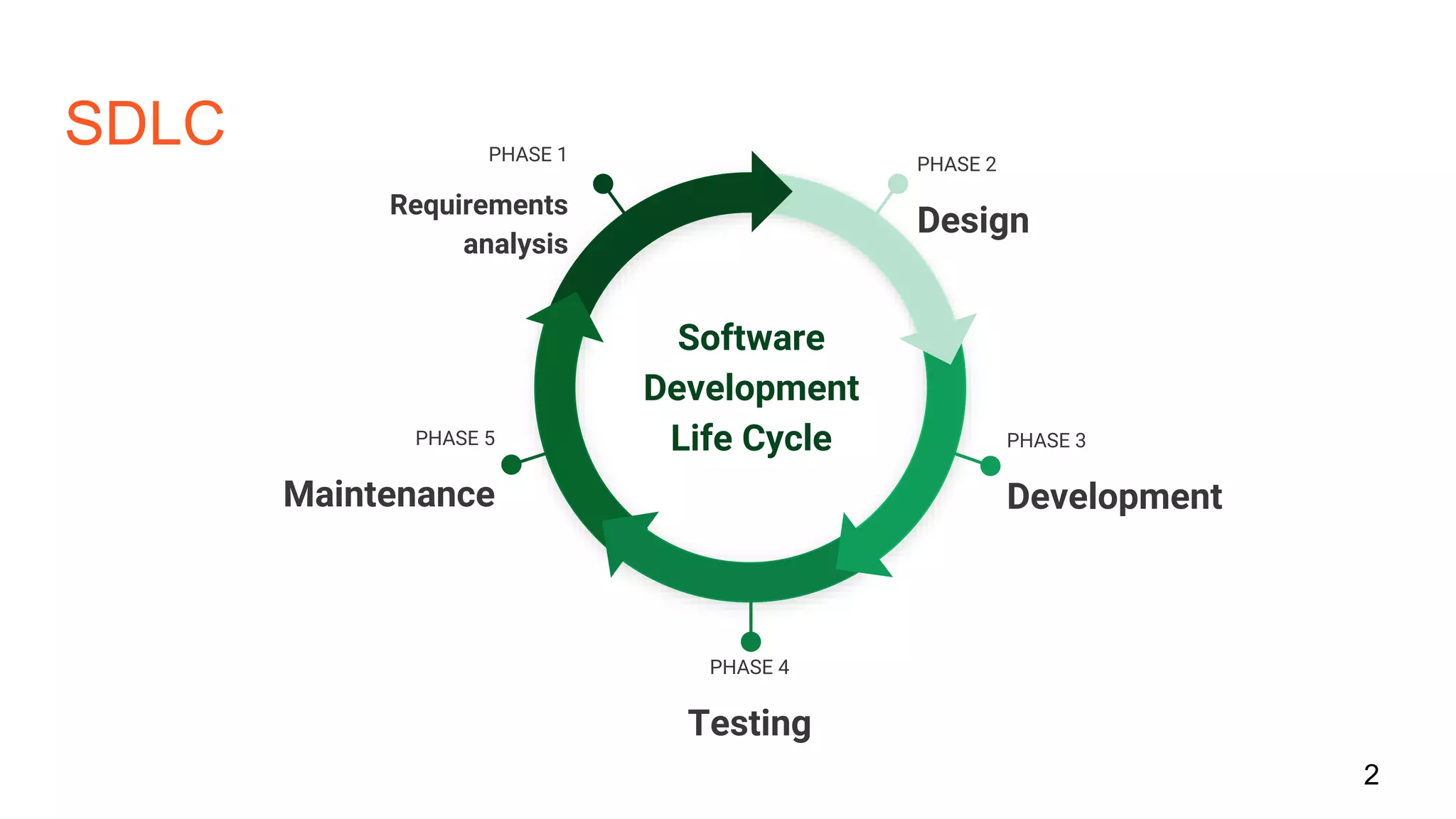












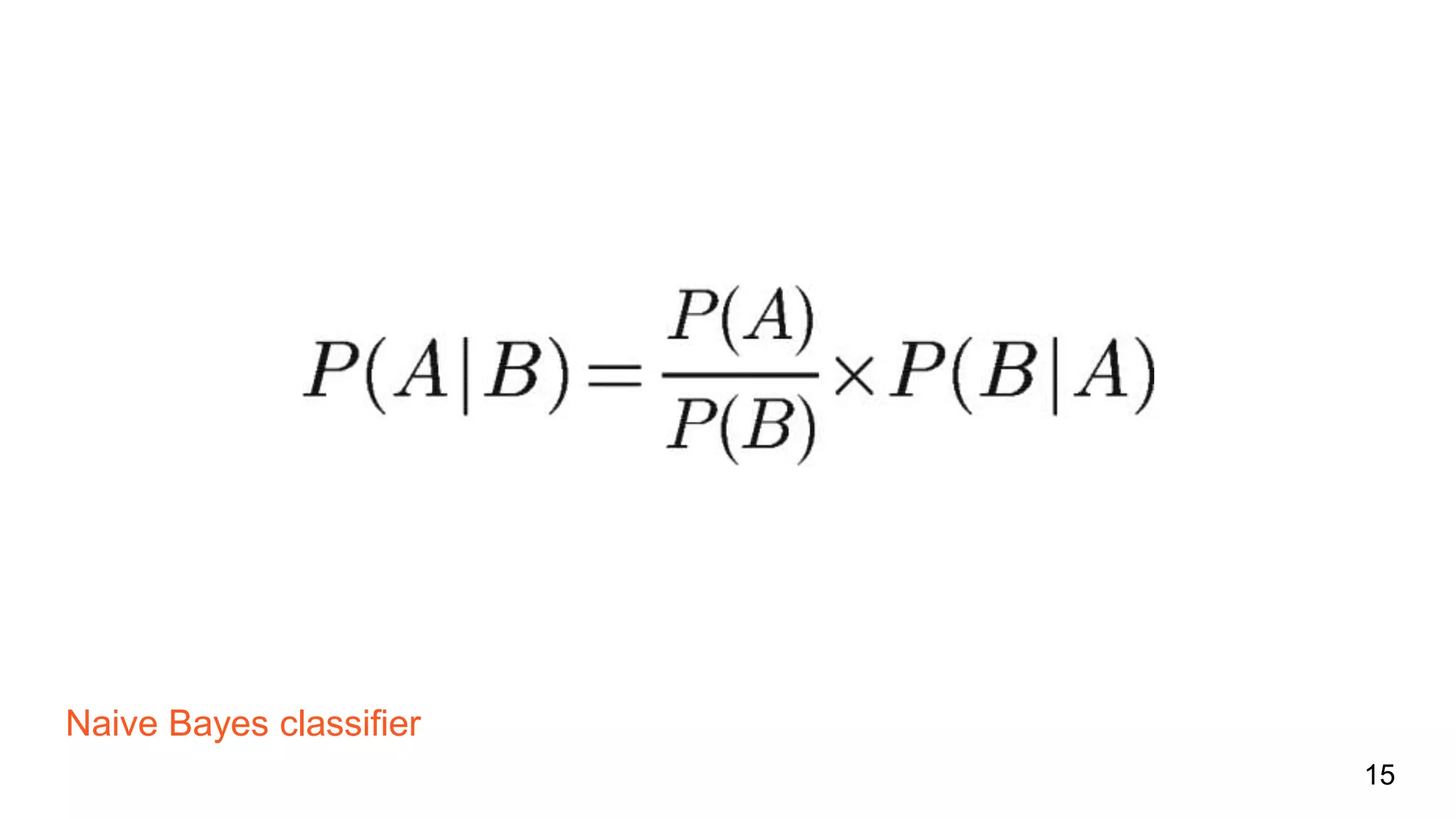
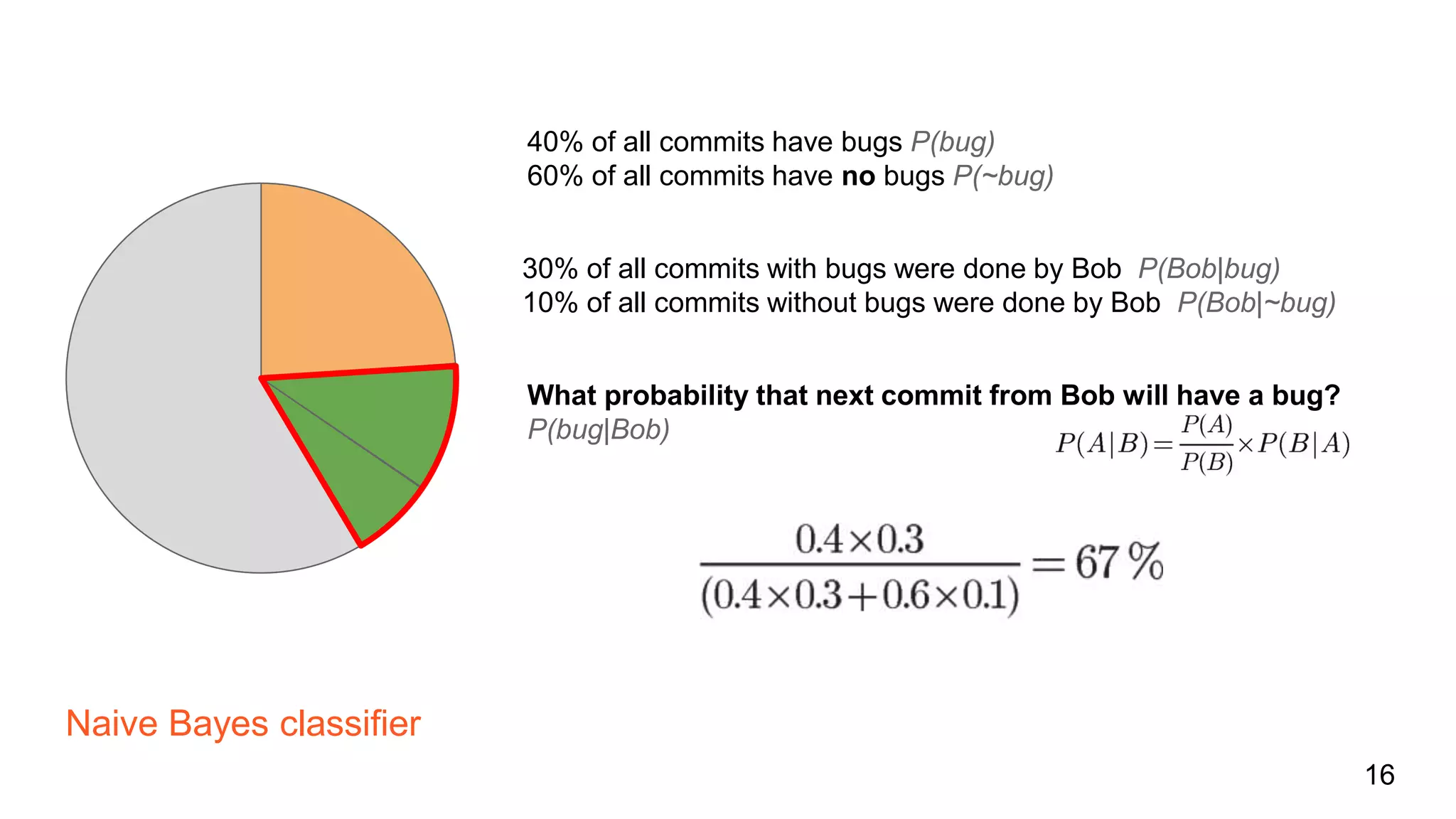

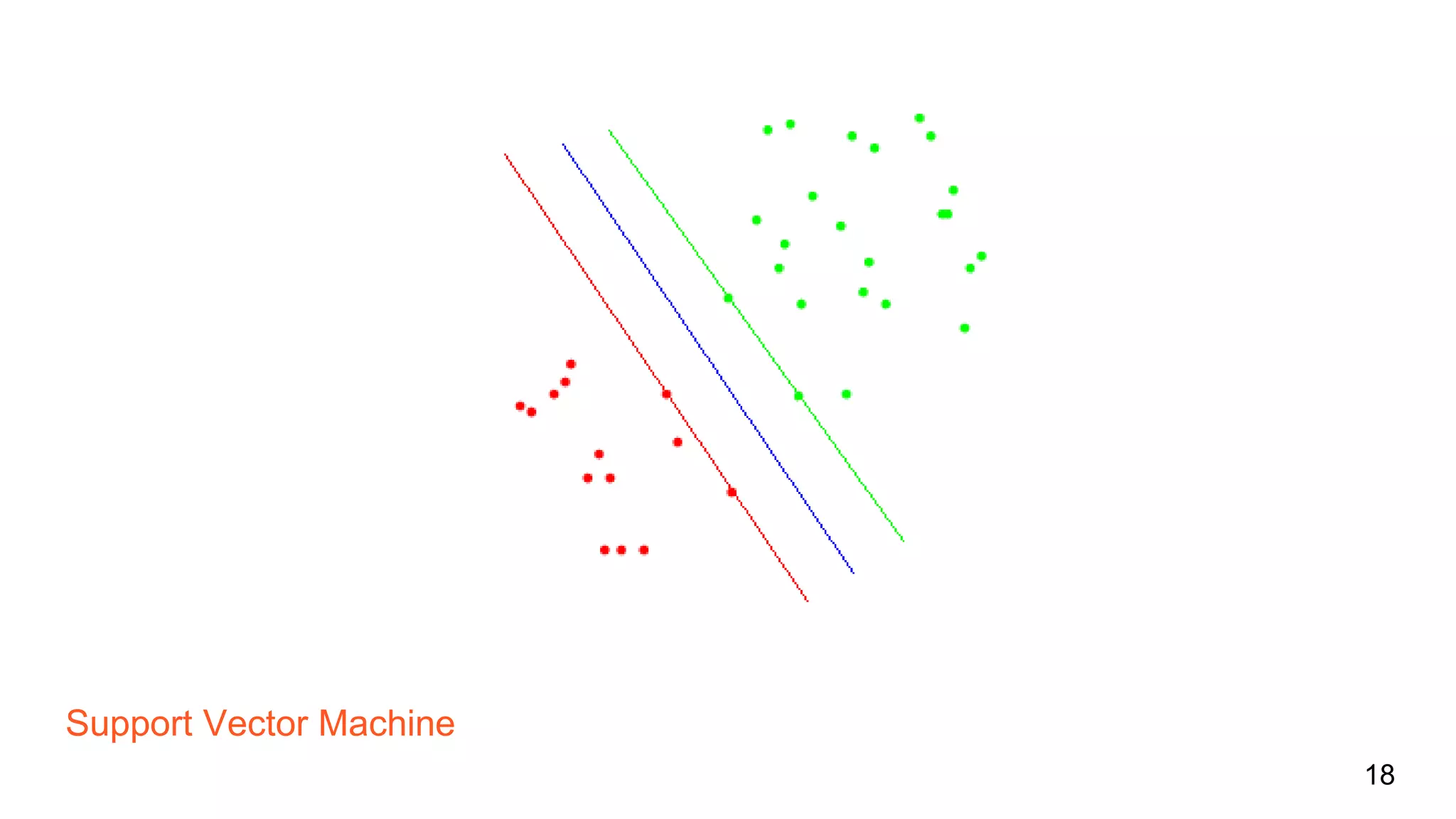
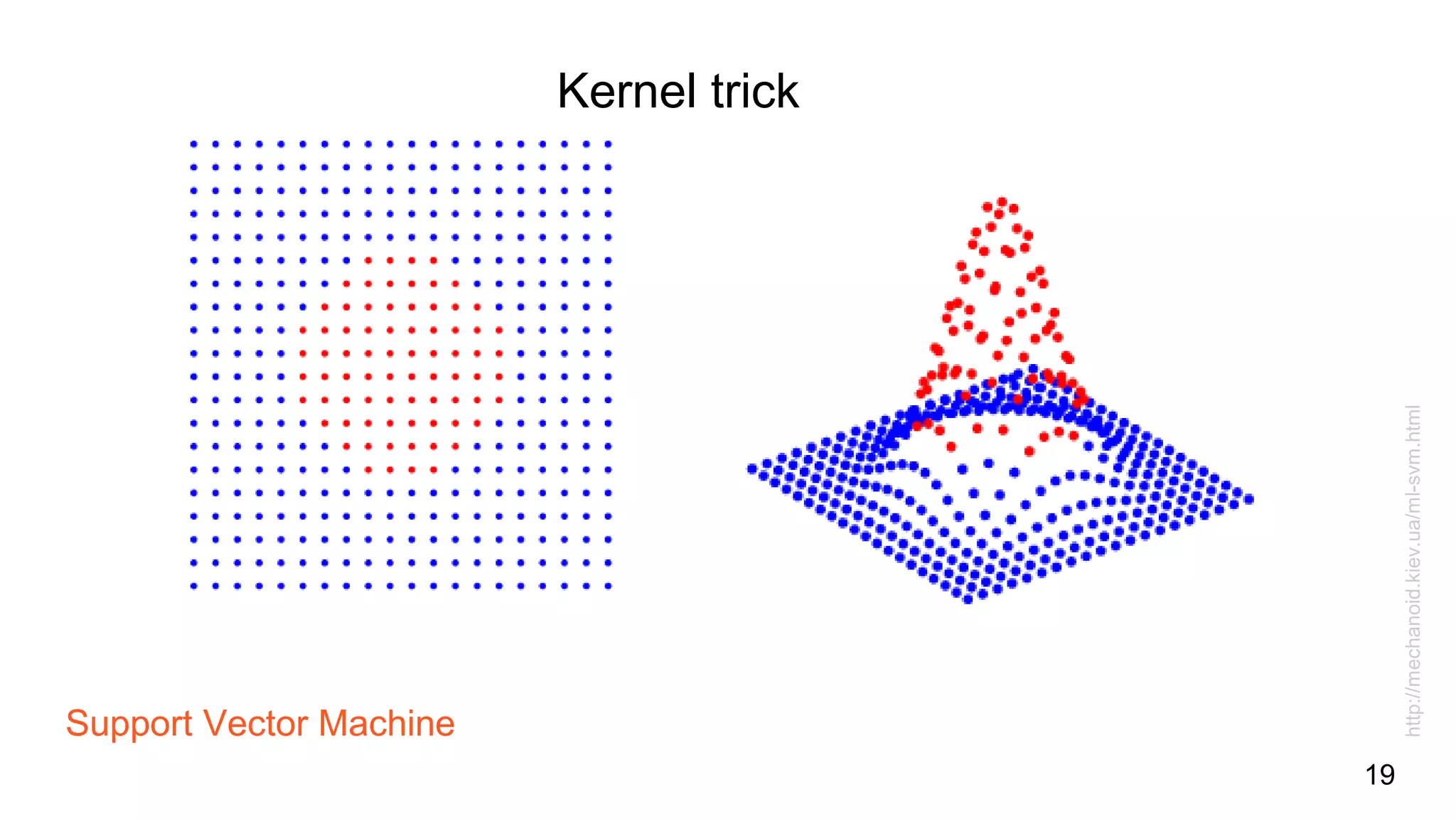

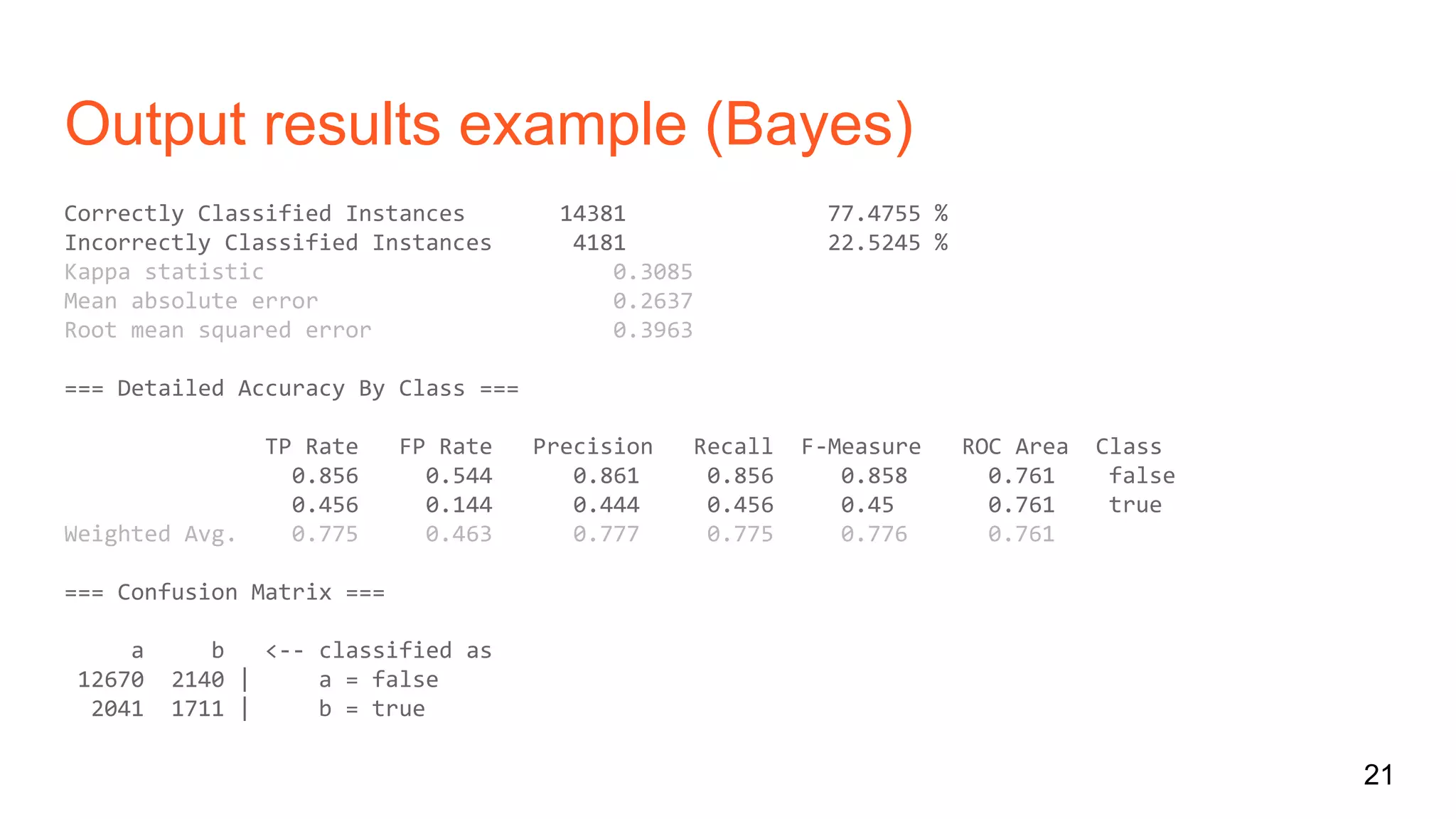





The document discusses bug prediction in software development using code history, highlighting the limitations of traditional practices like code reviews and automated testing. It describes a process of collecting data from commits to improve predictions of bug occurrences, utilizing machine learning tools such as Weka and implementing various classifiers. It concludes by noting the importance of analyzing commit history to reduce bugs and improve team practices.






































![[xp2013] Narrow Down What to Test](https://cdn.slidesharecdn.com/ss_thumbnails/zsoltfabokxp2013narrowdownwhattotestfull-151115174921-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



































