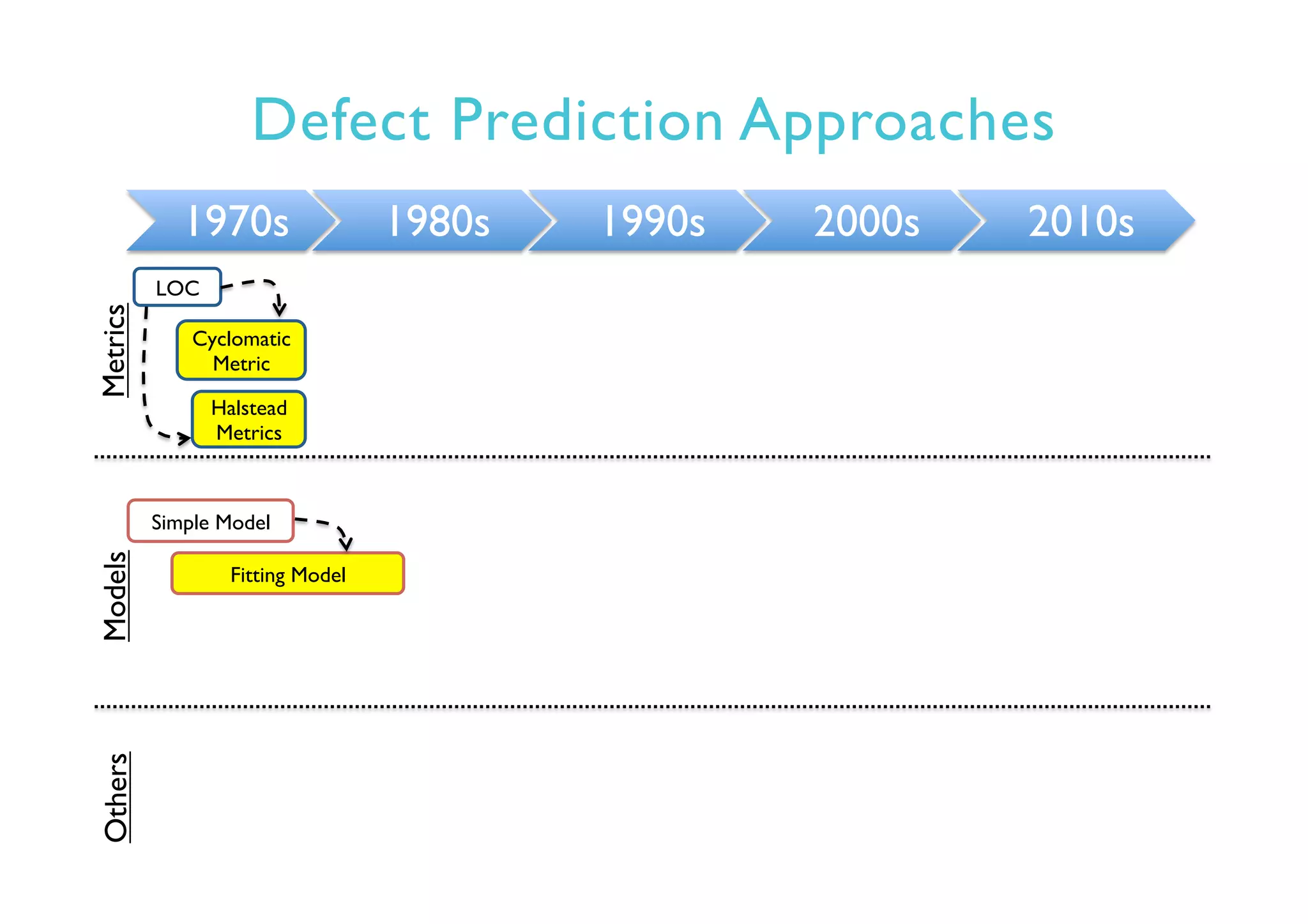
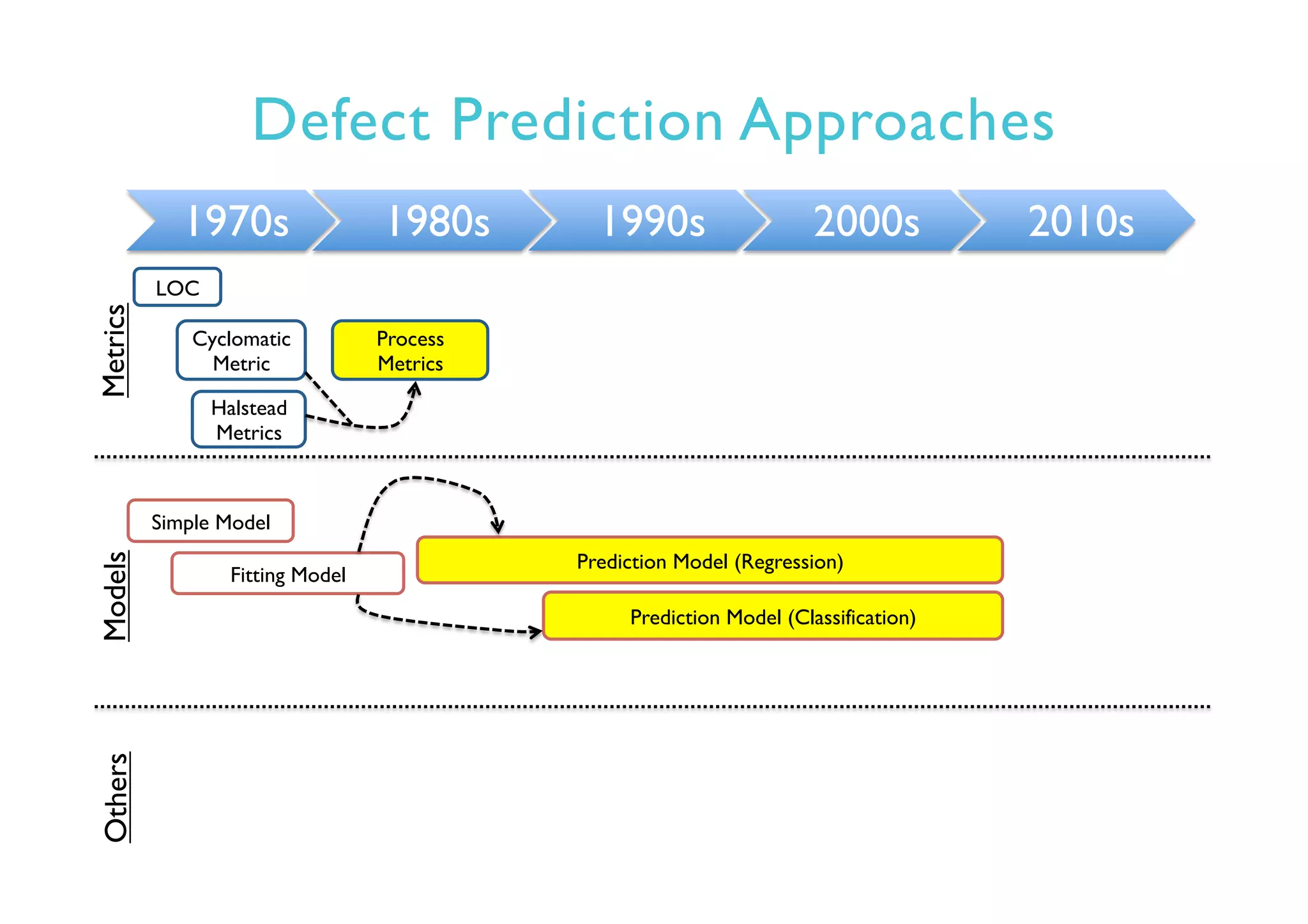
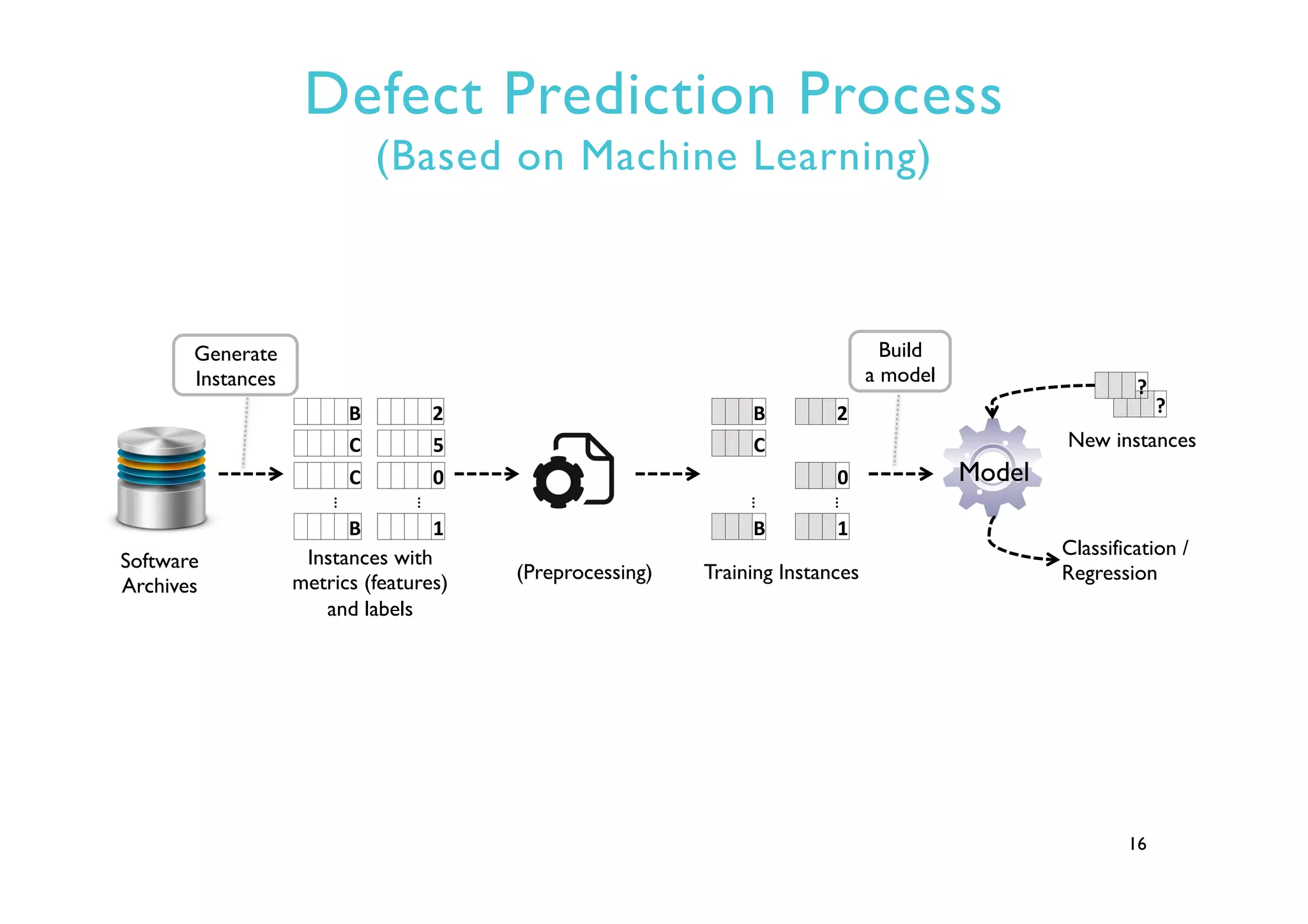
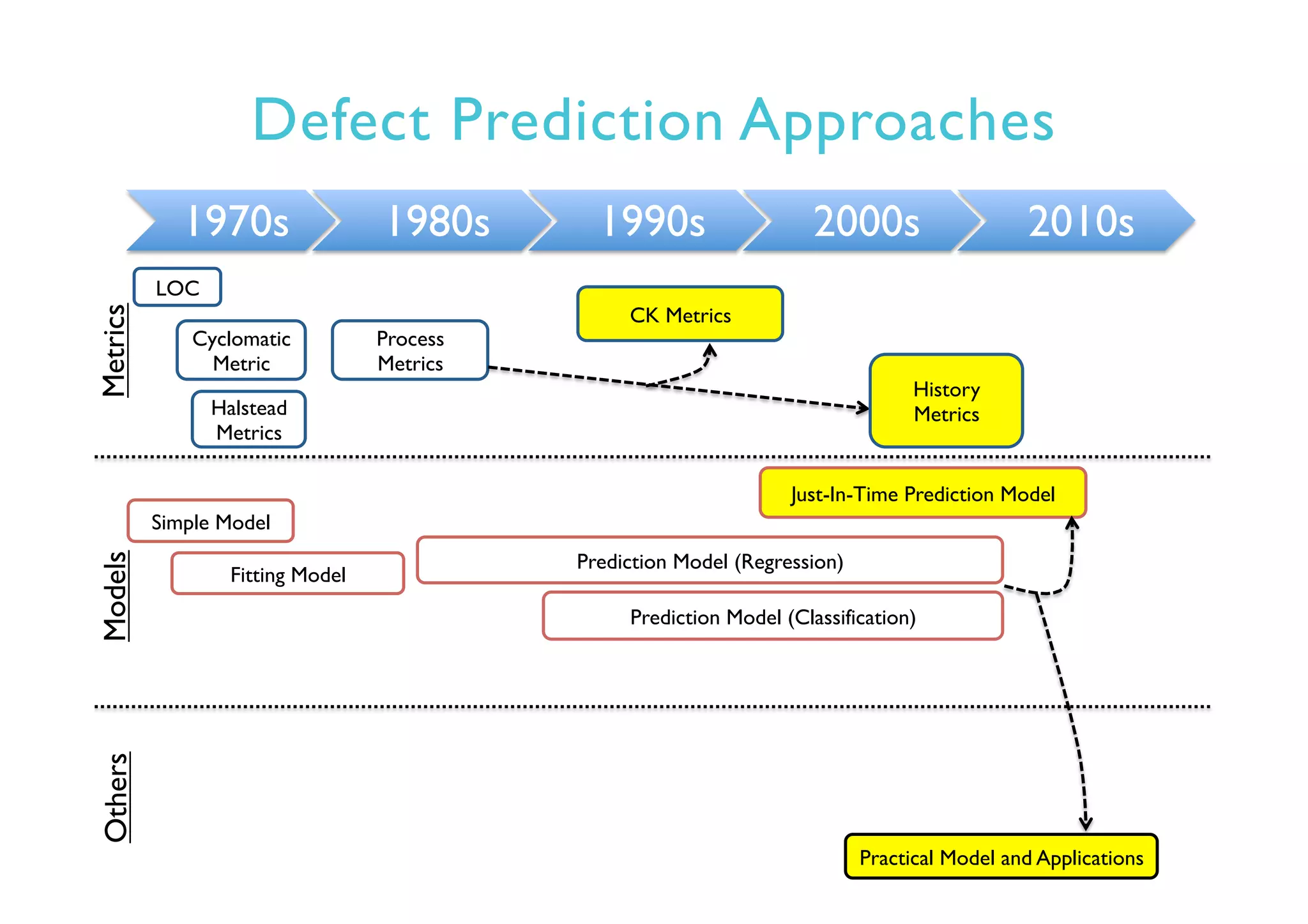
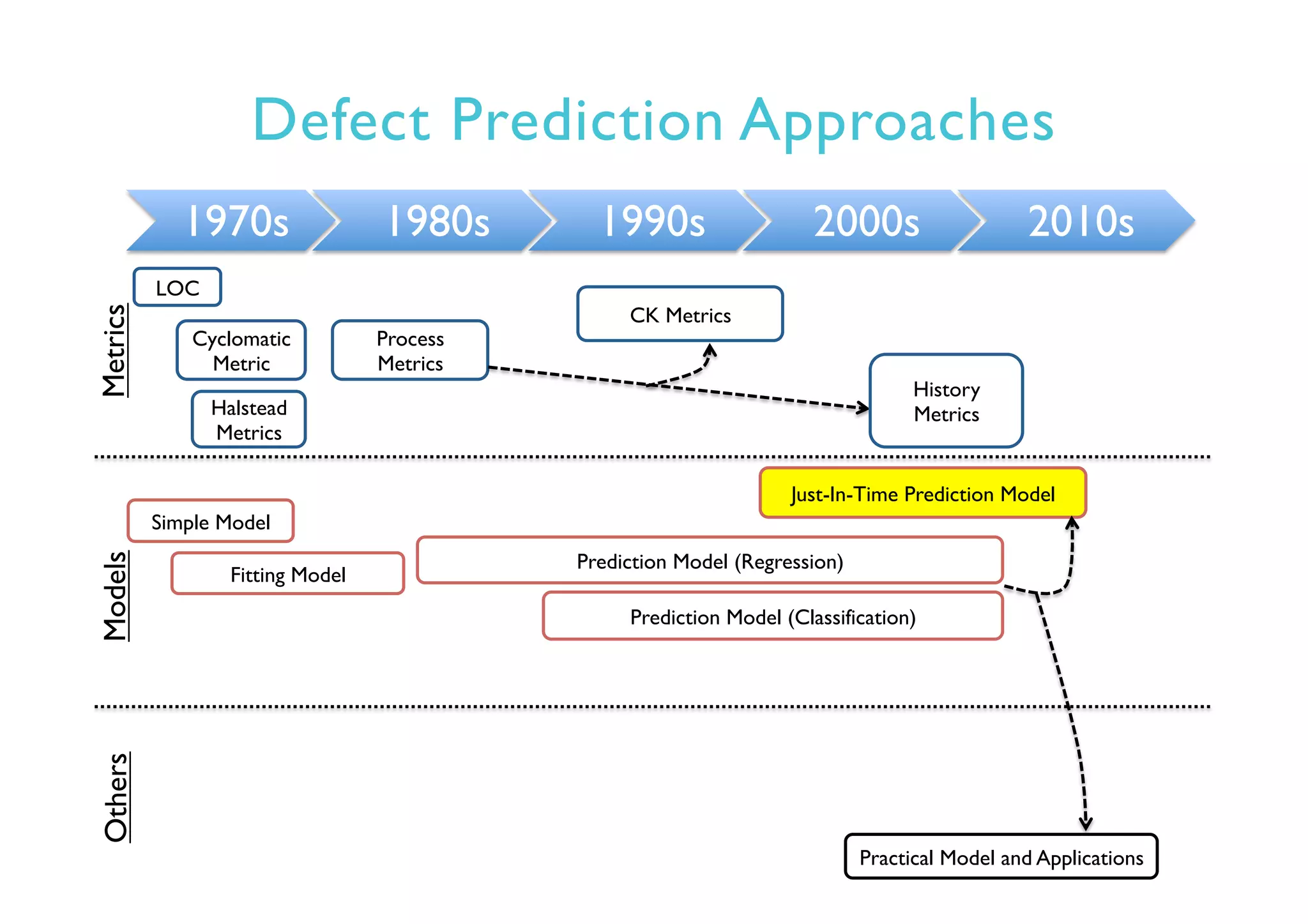
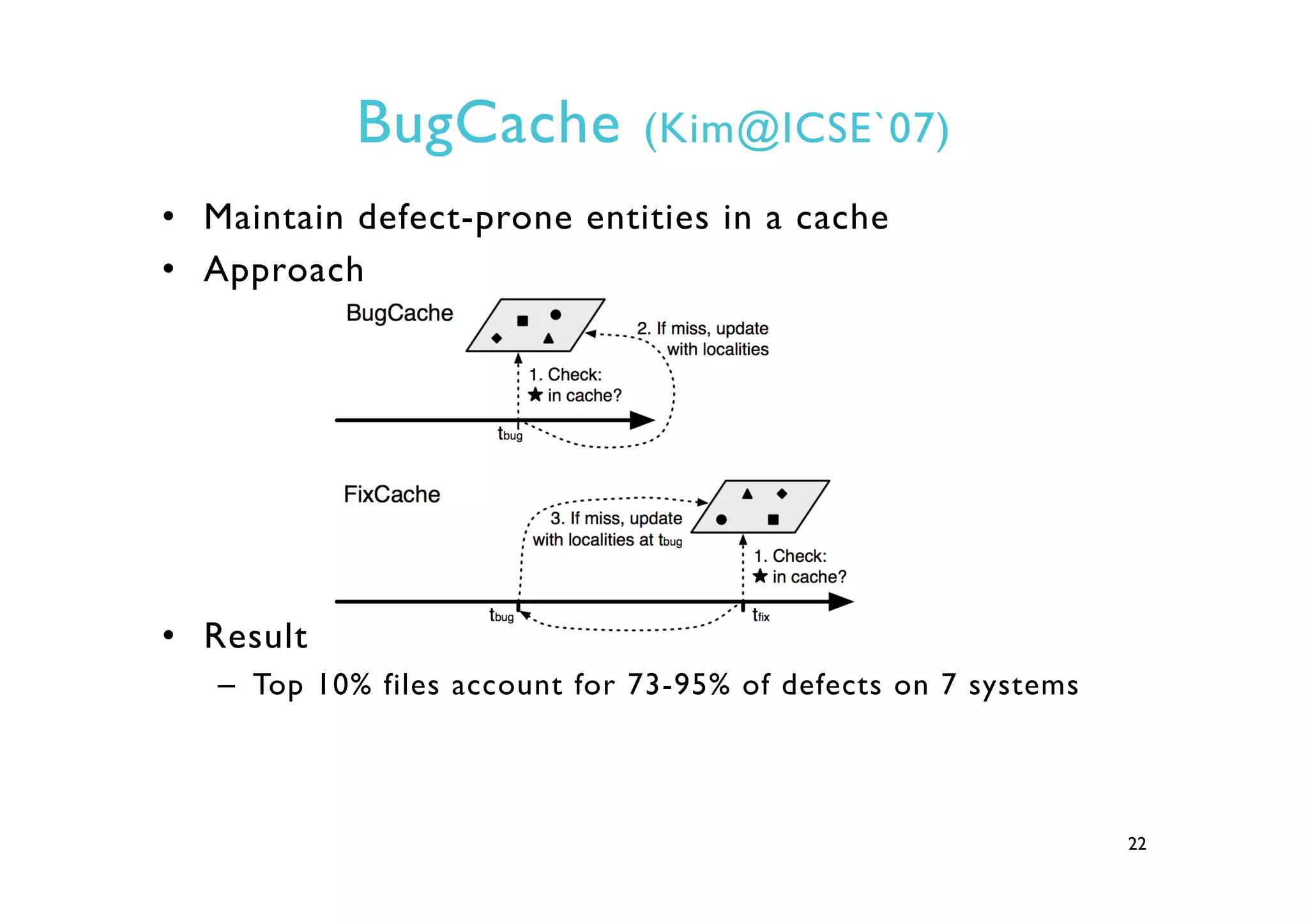
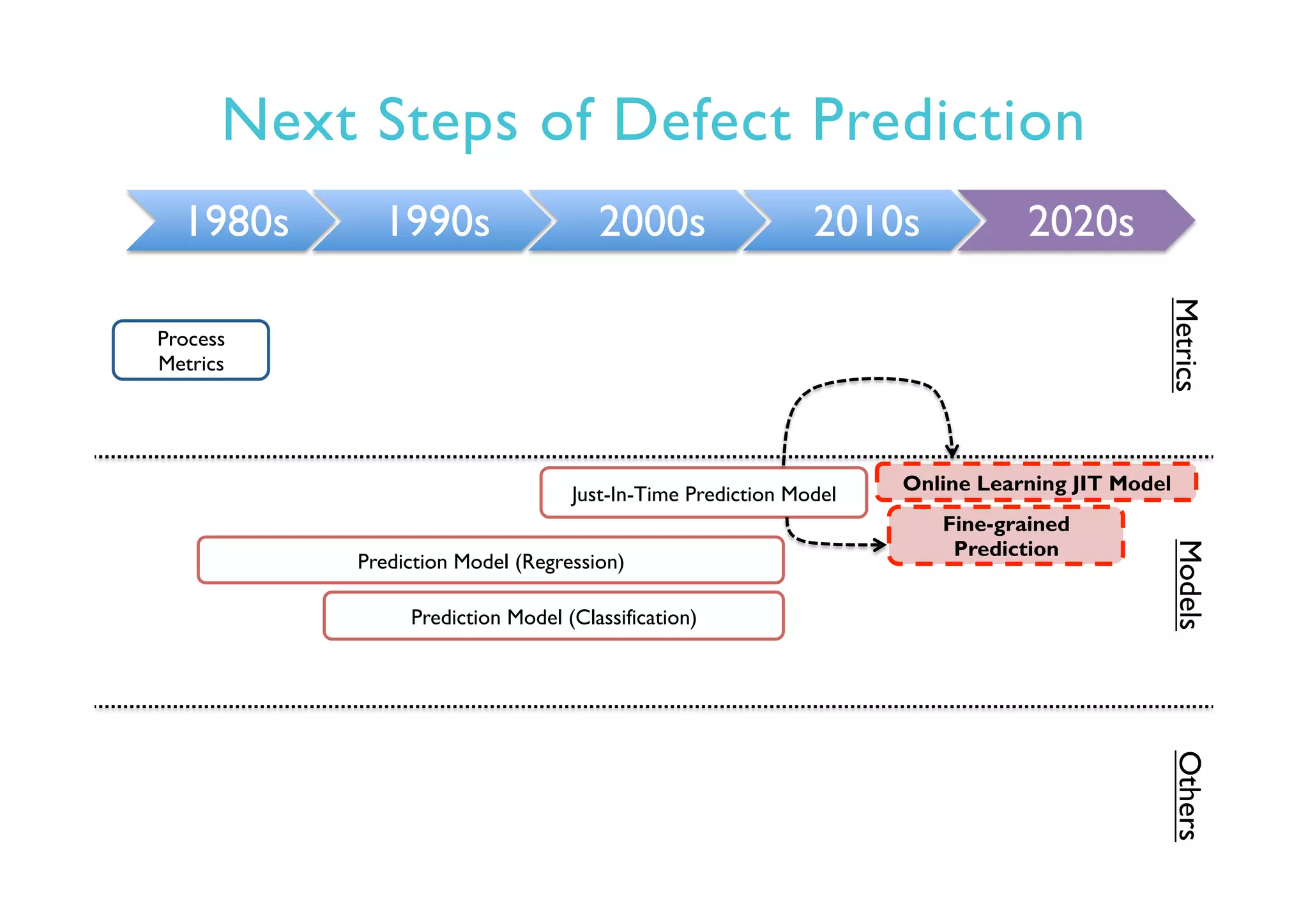
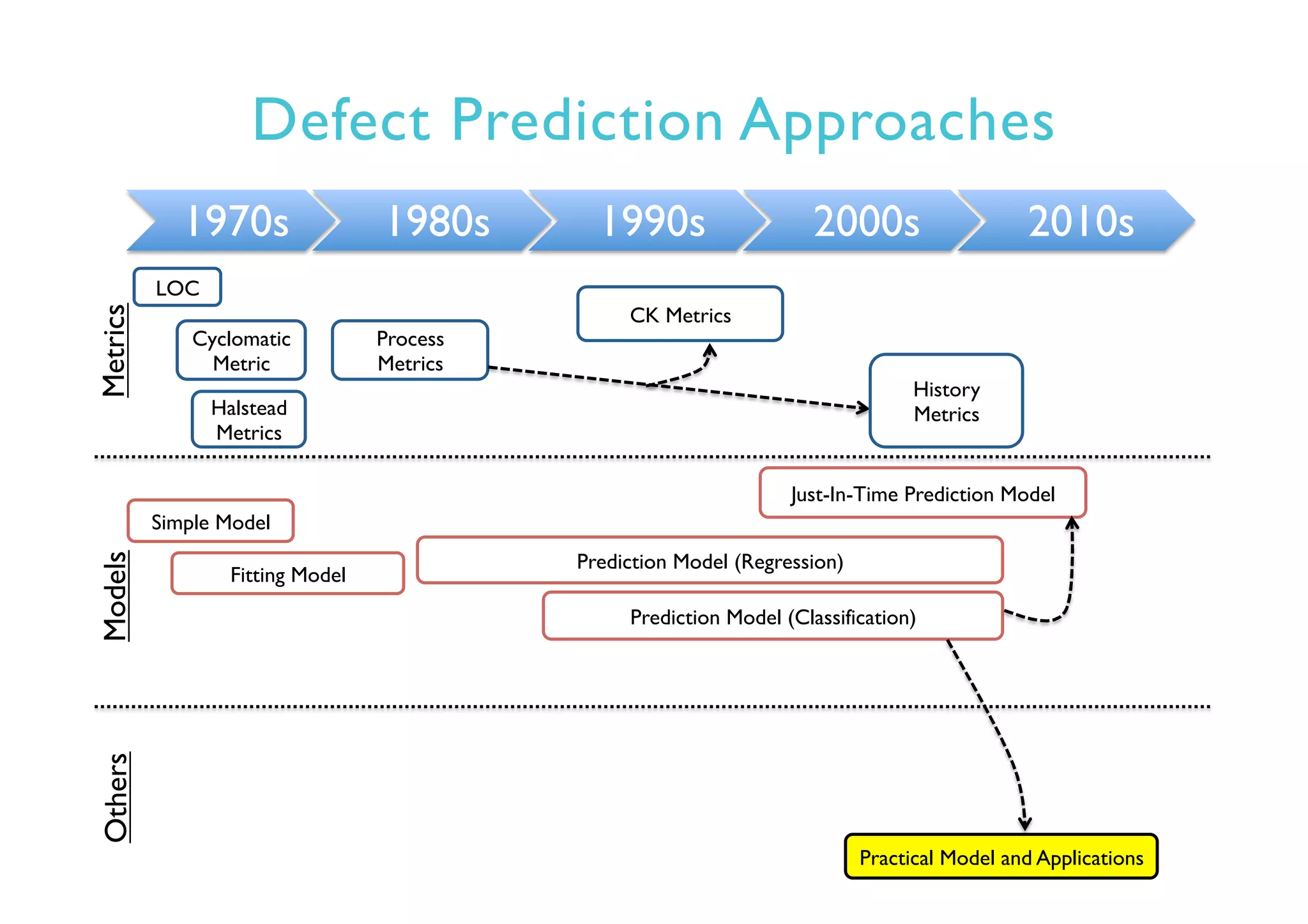
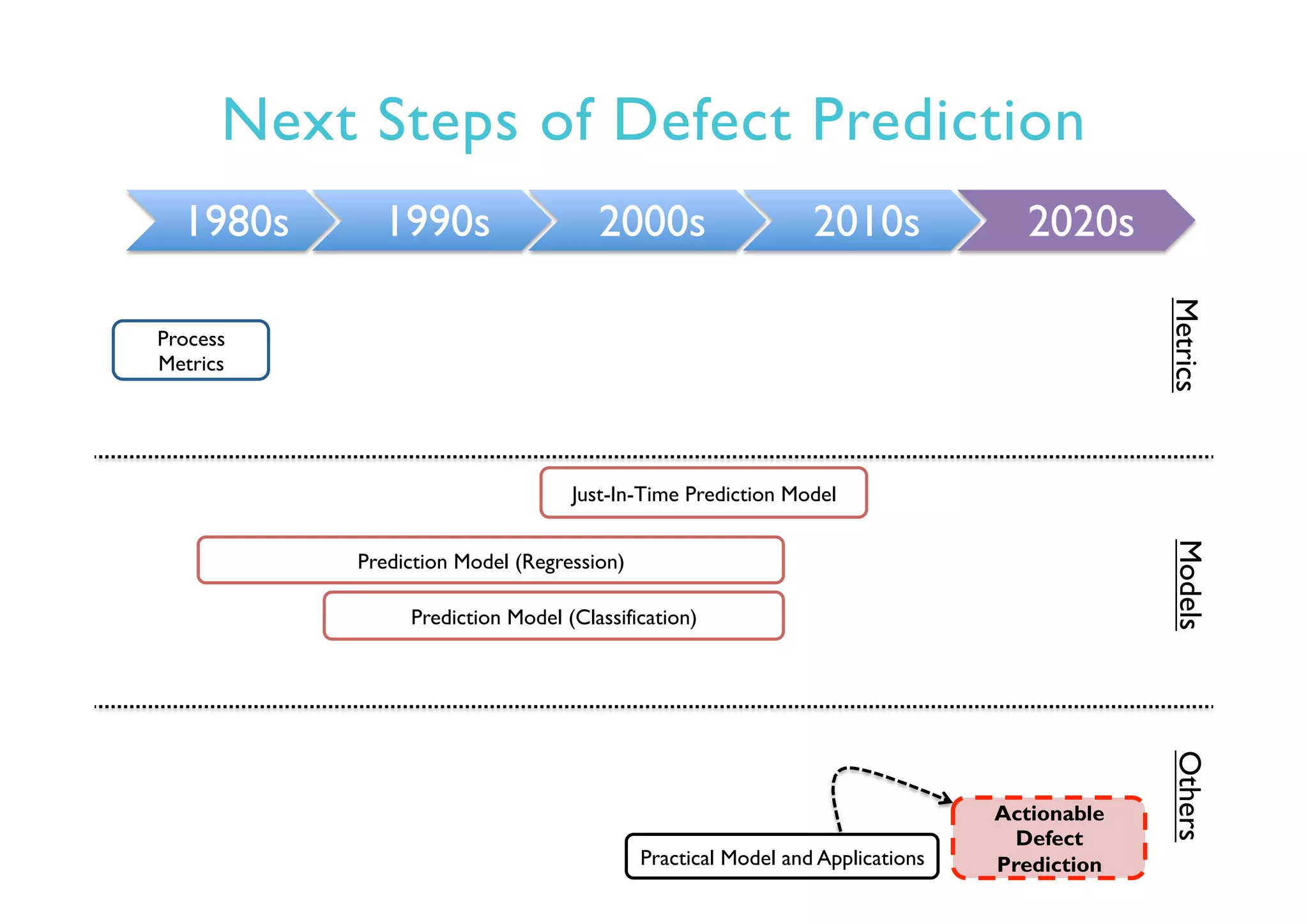
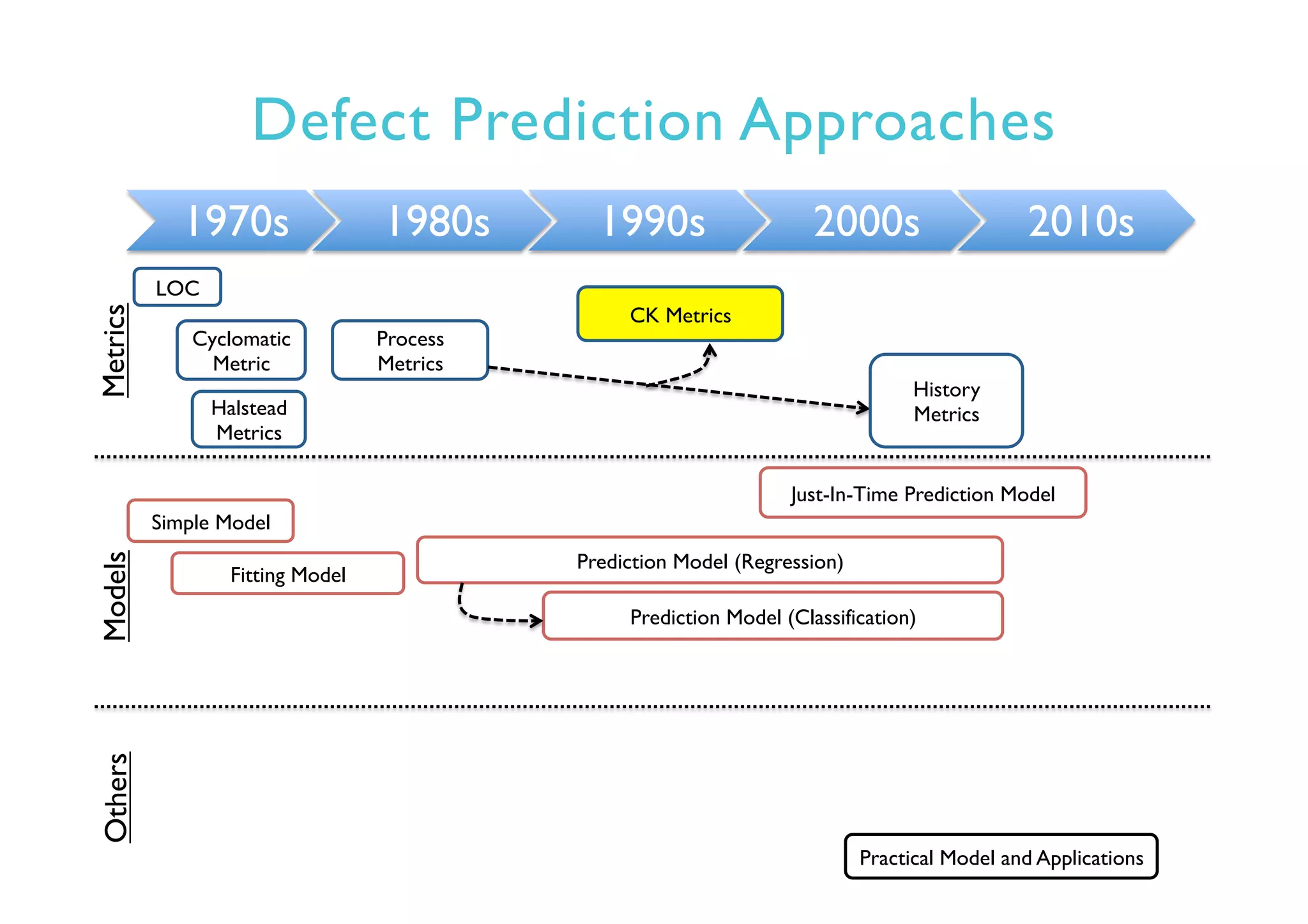
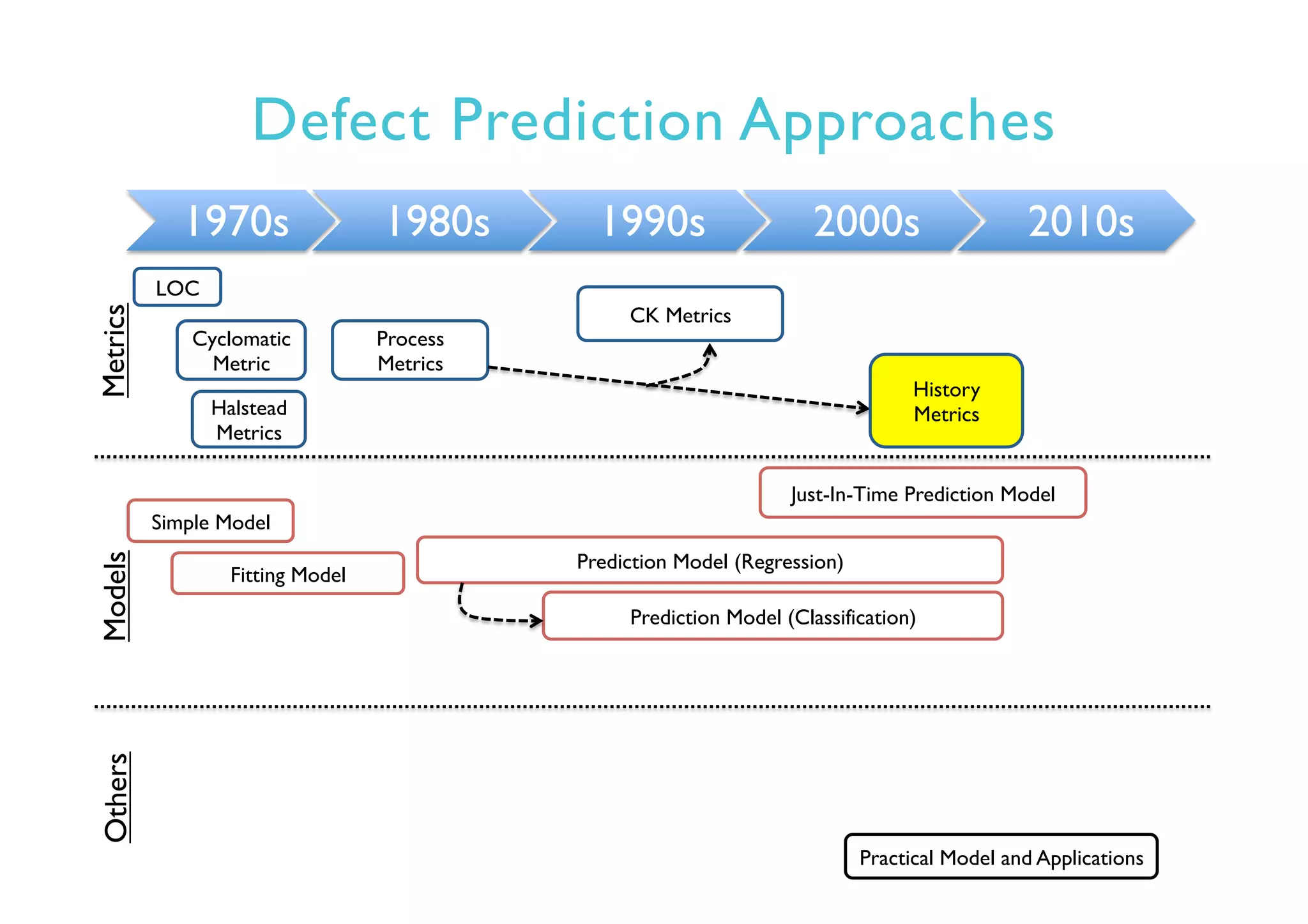
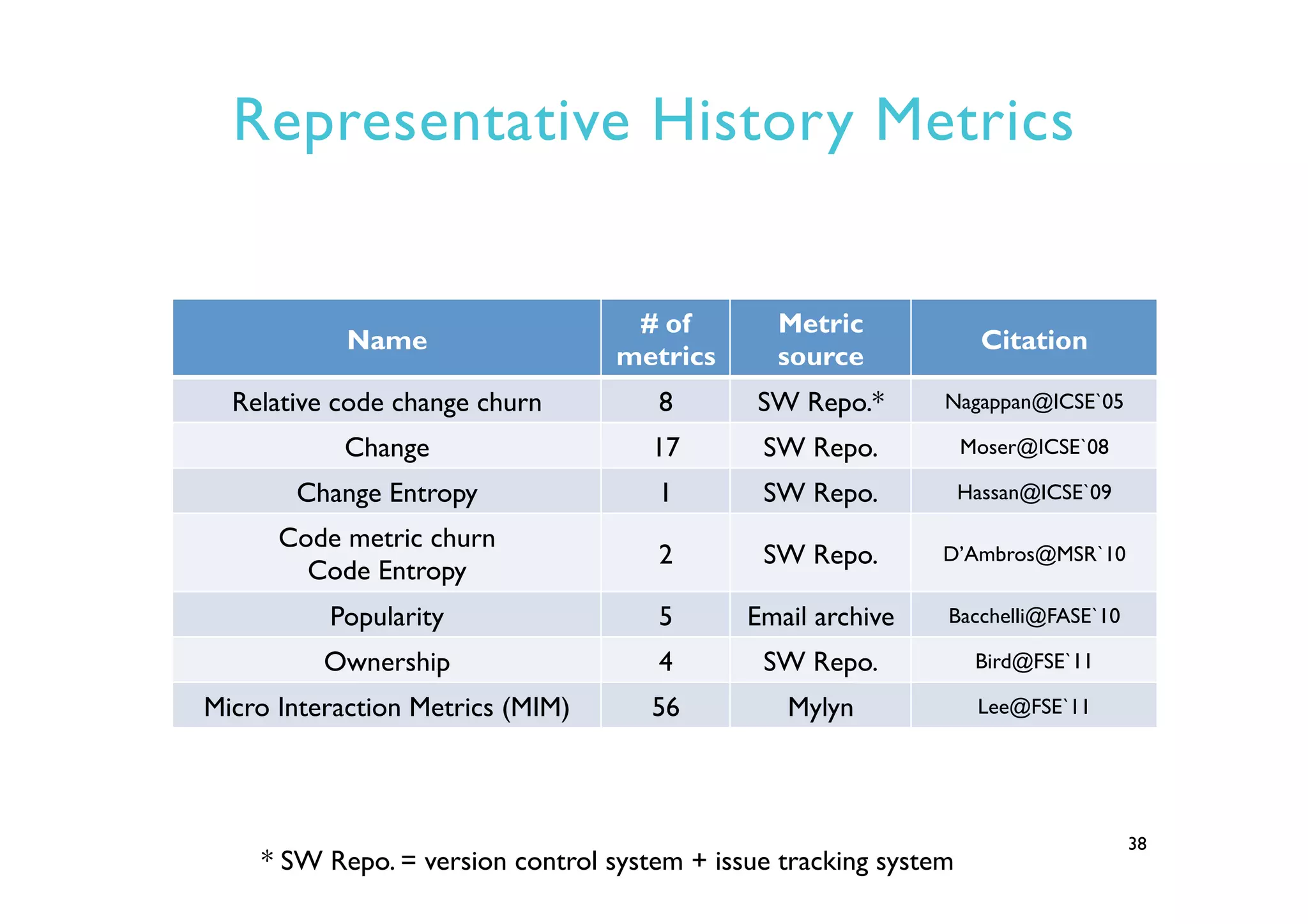
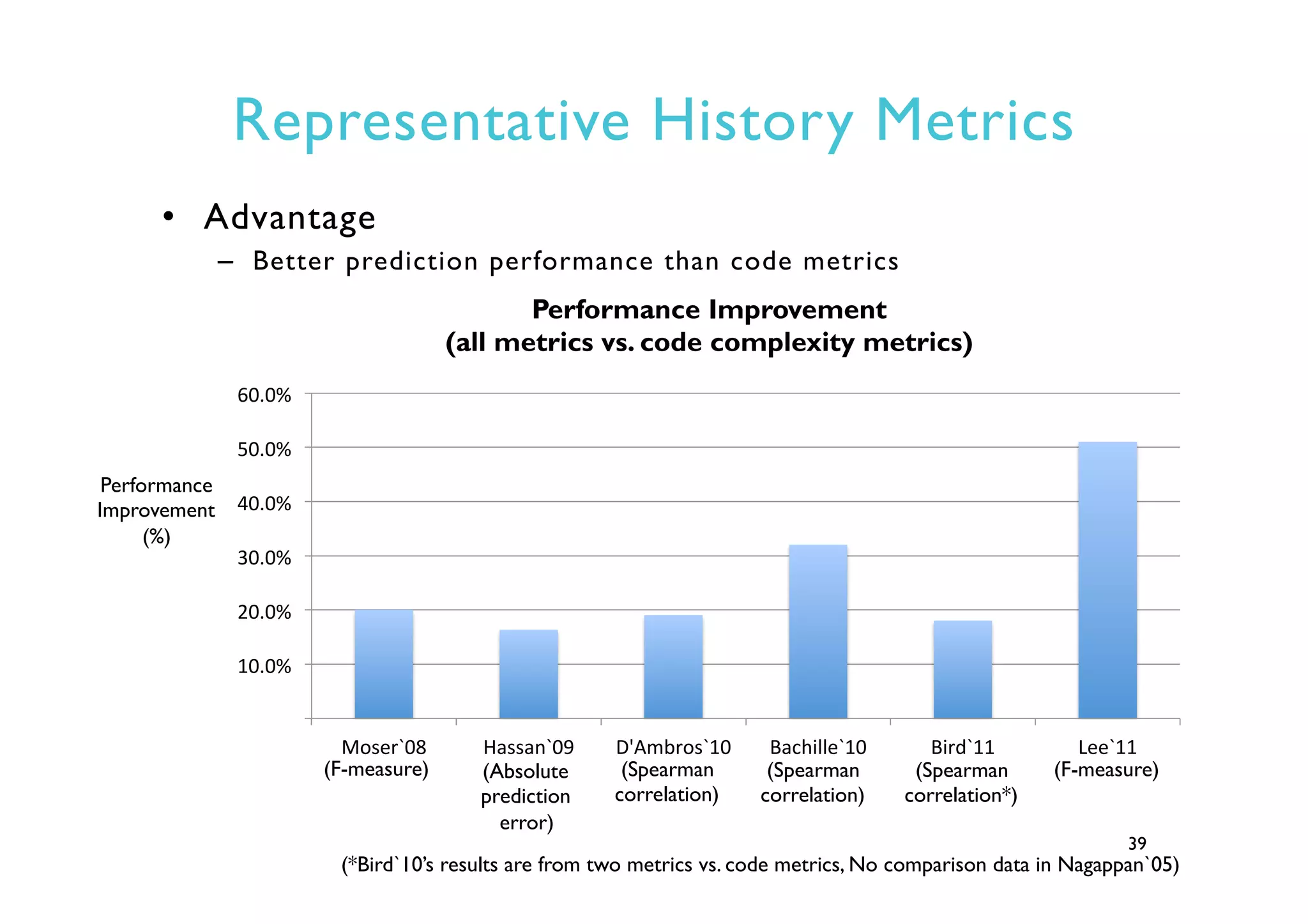
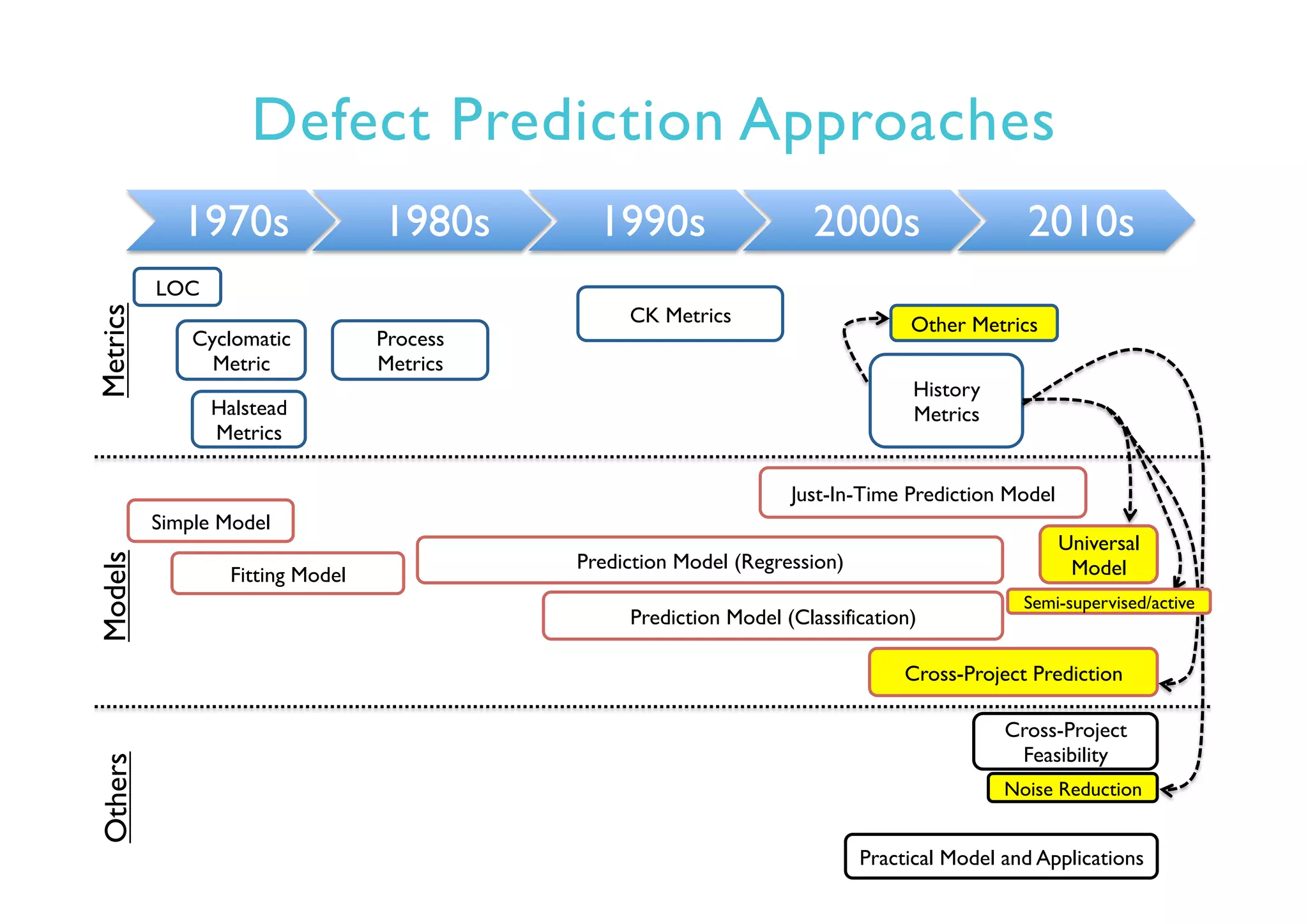
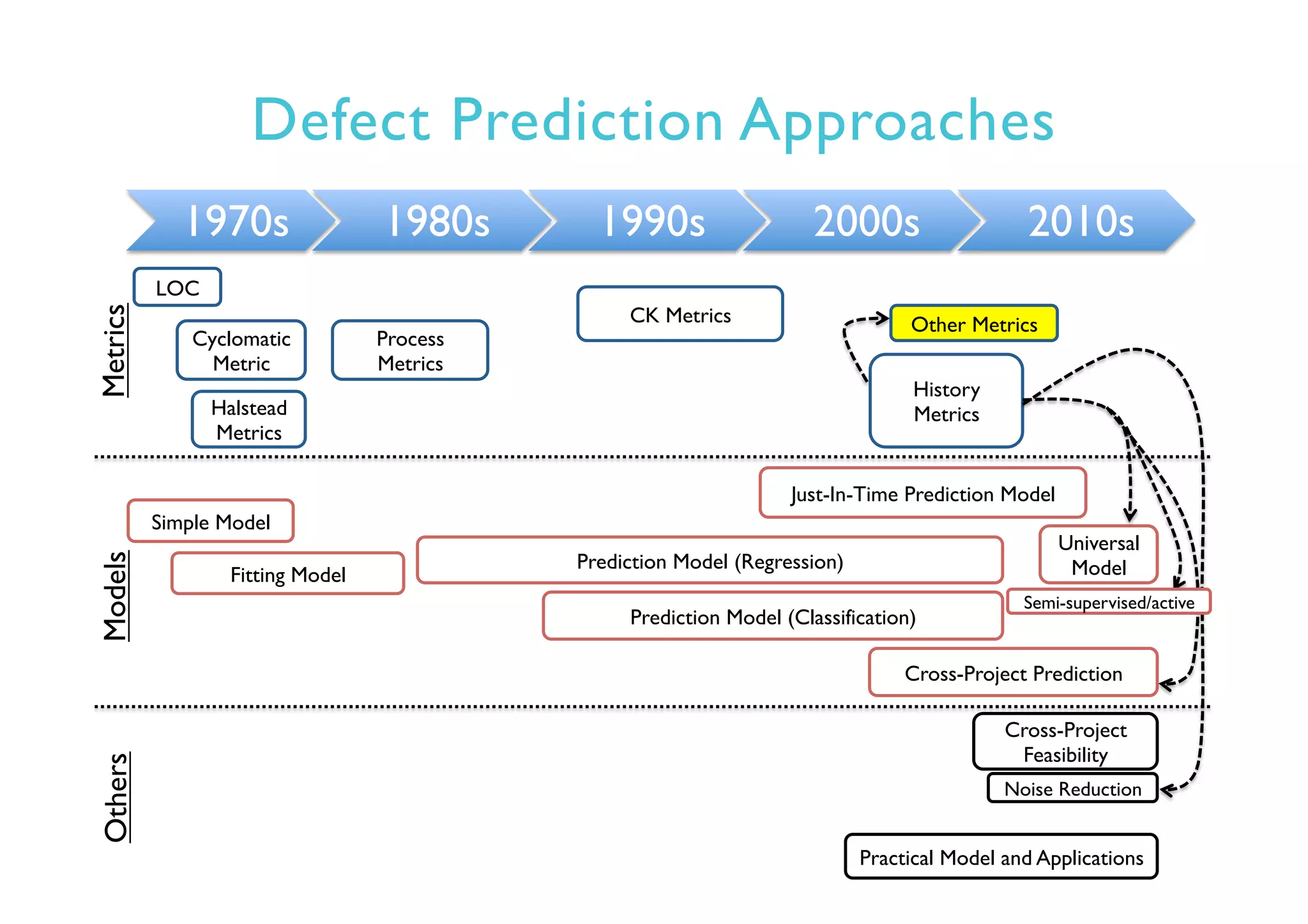
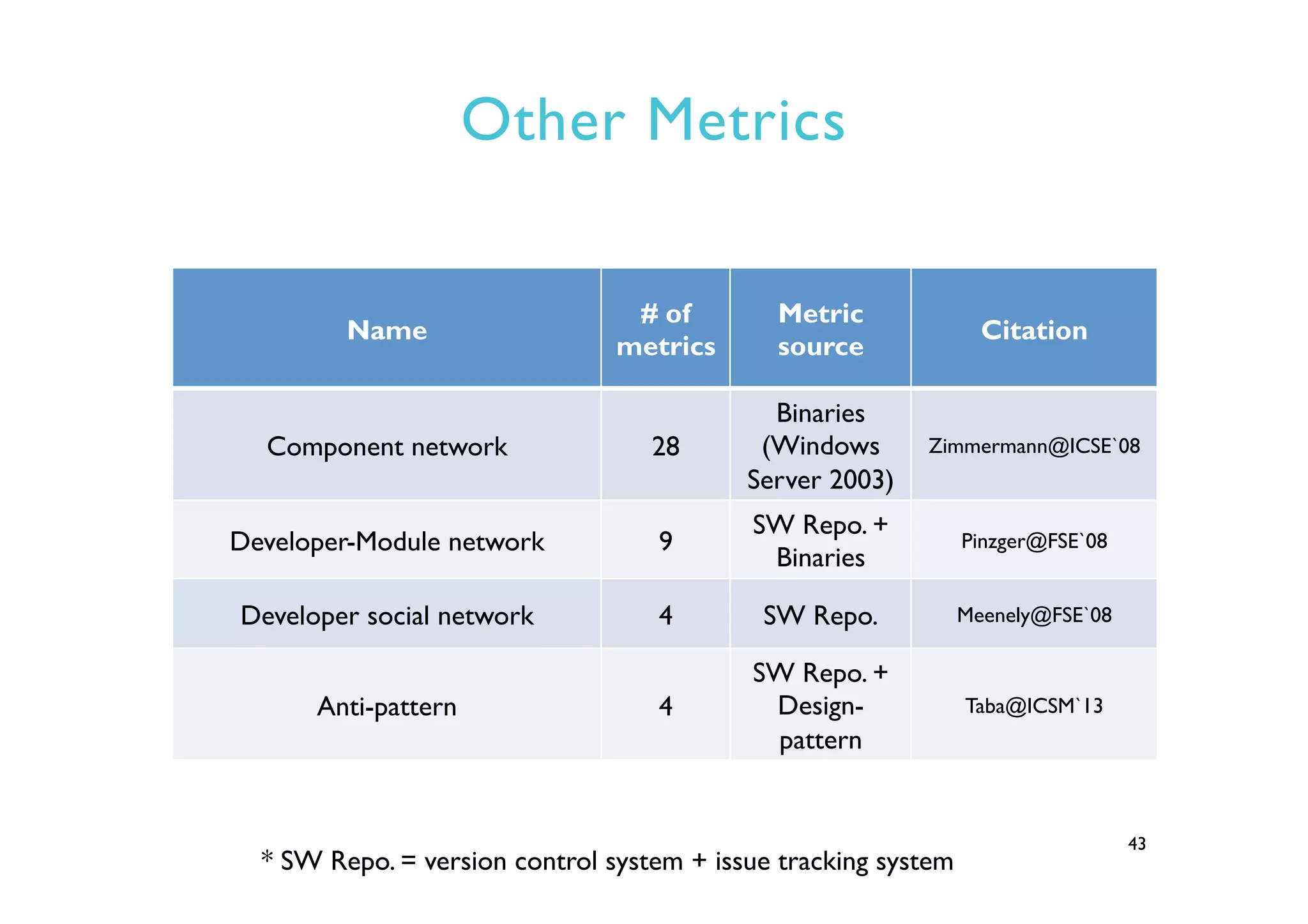
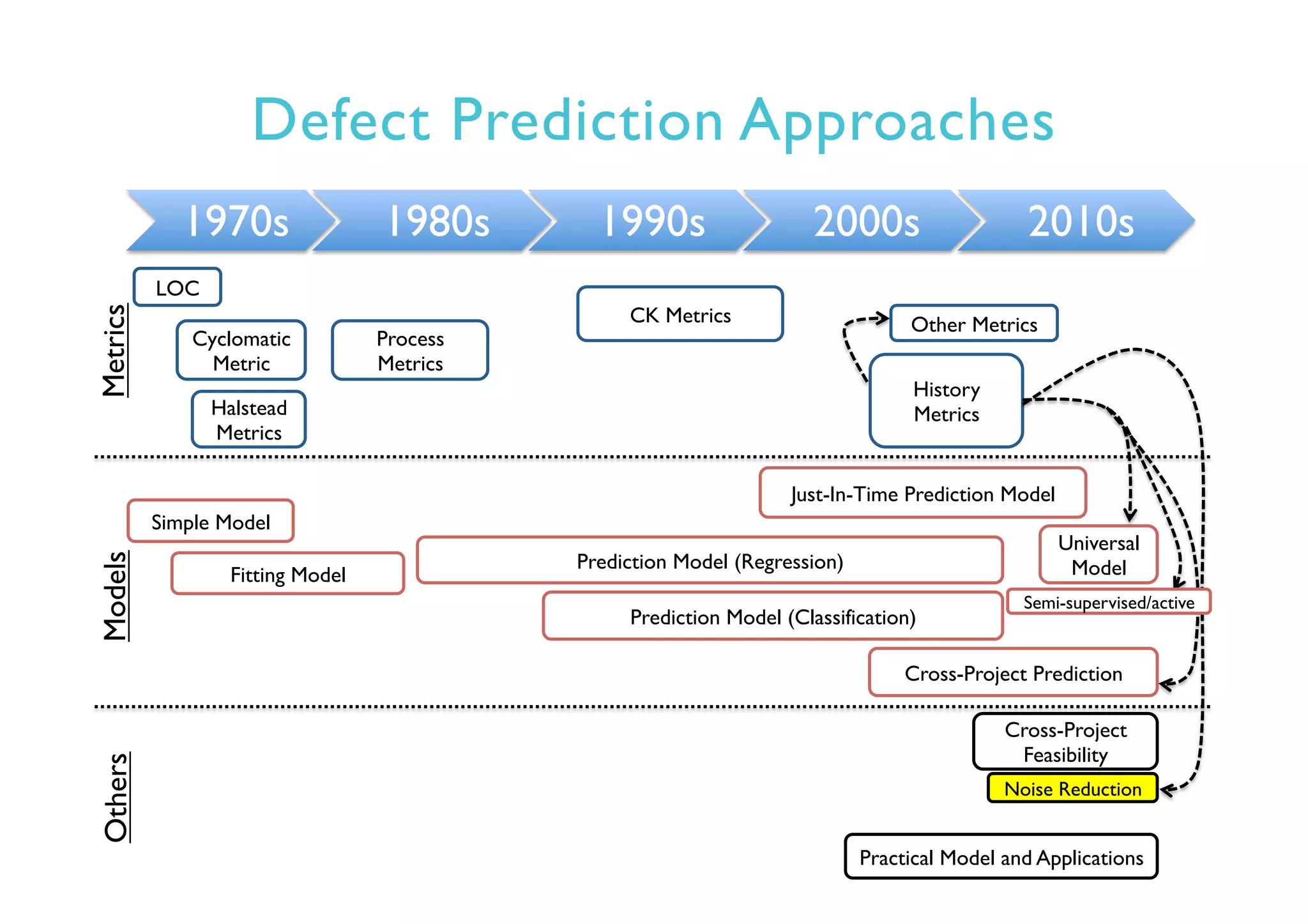
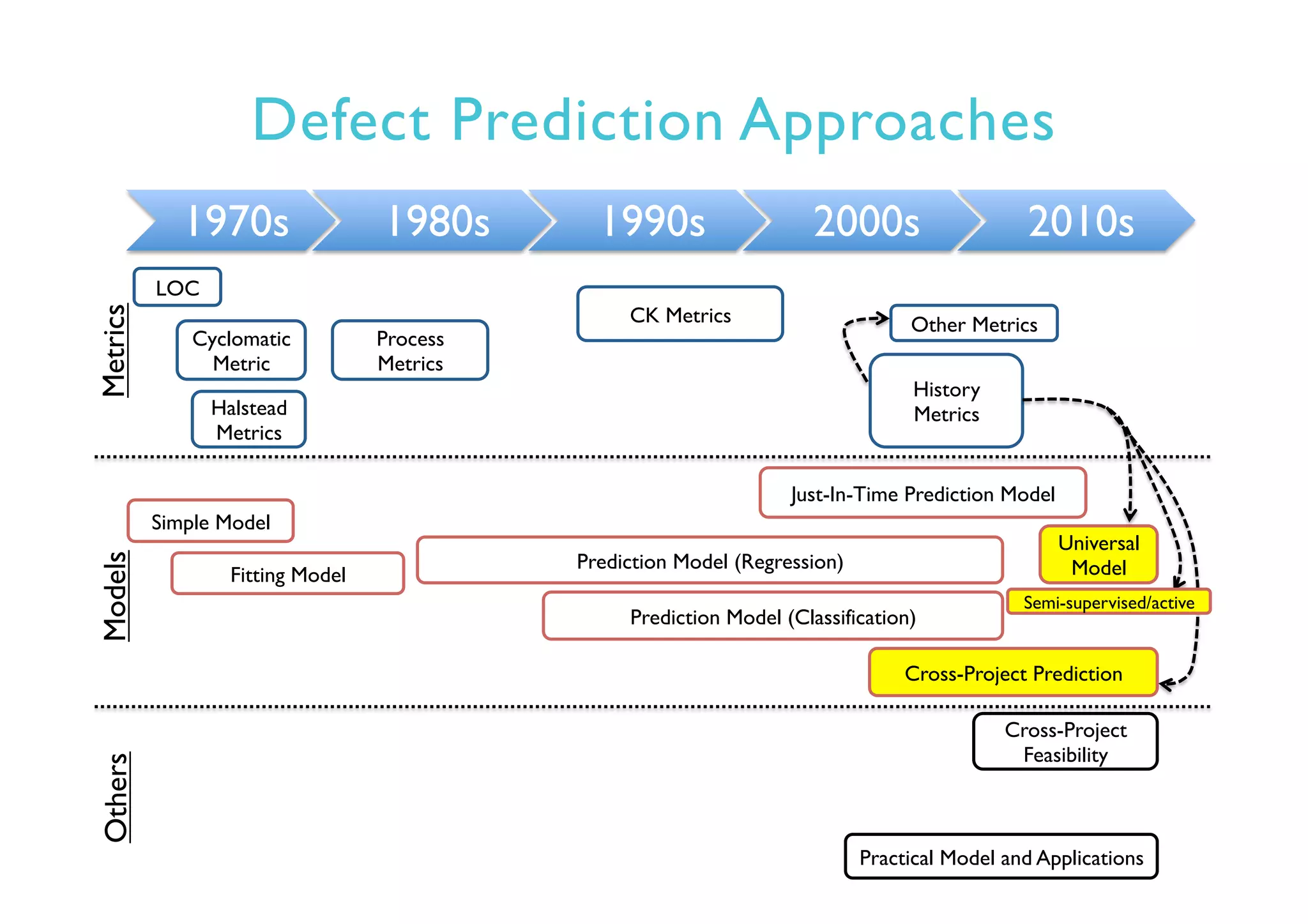
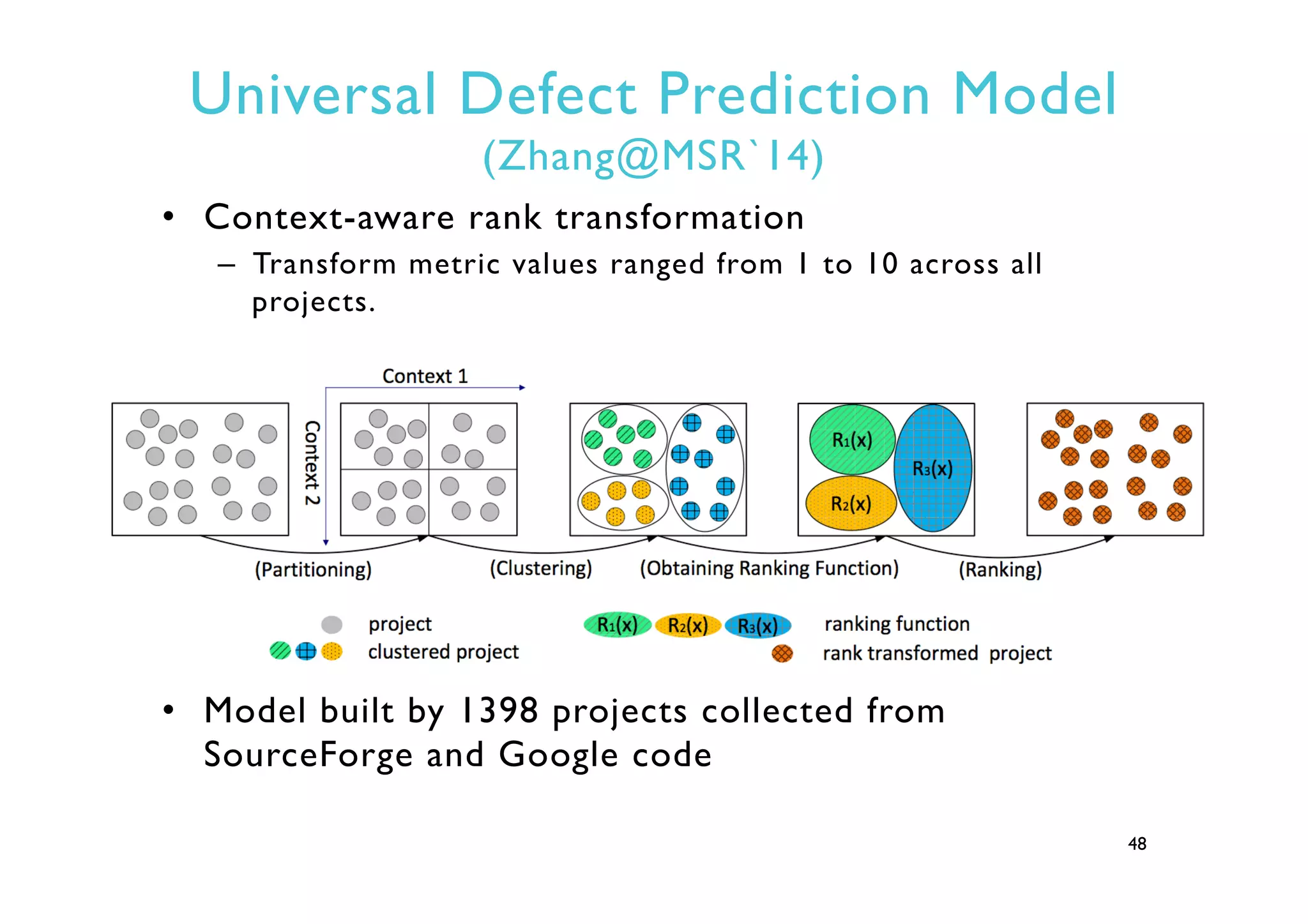
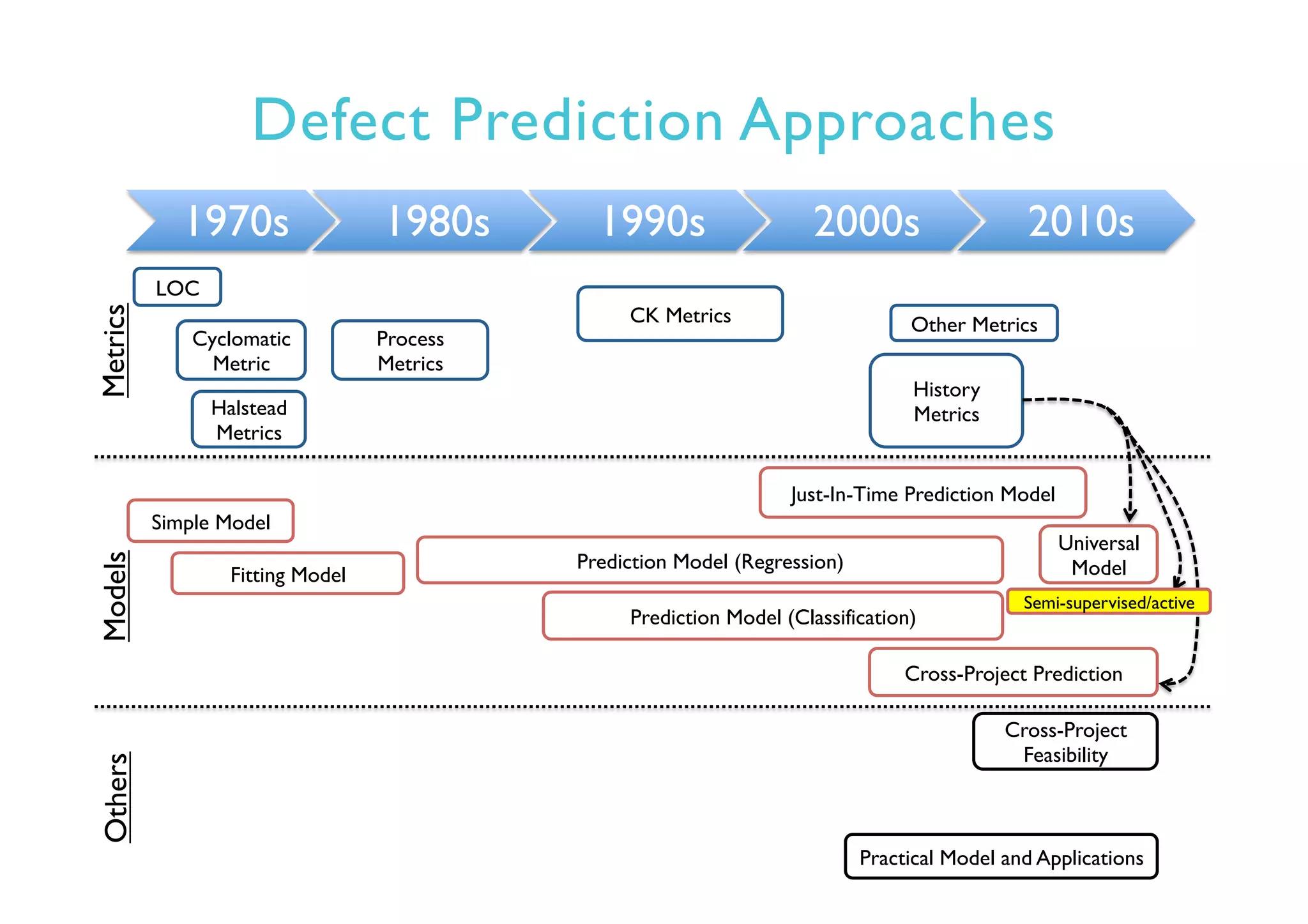
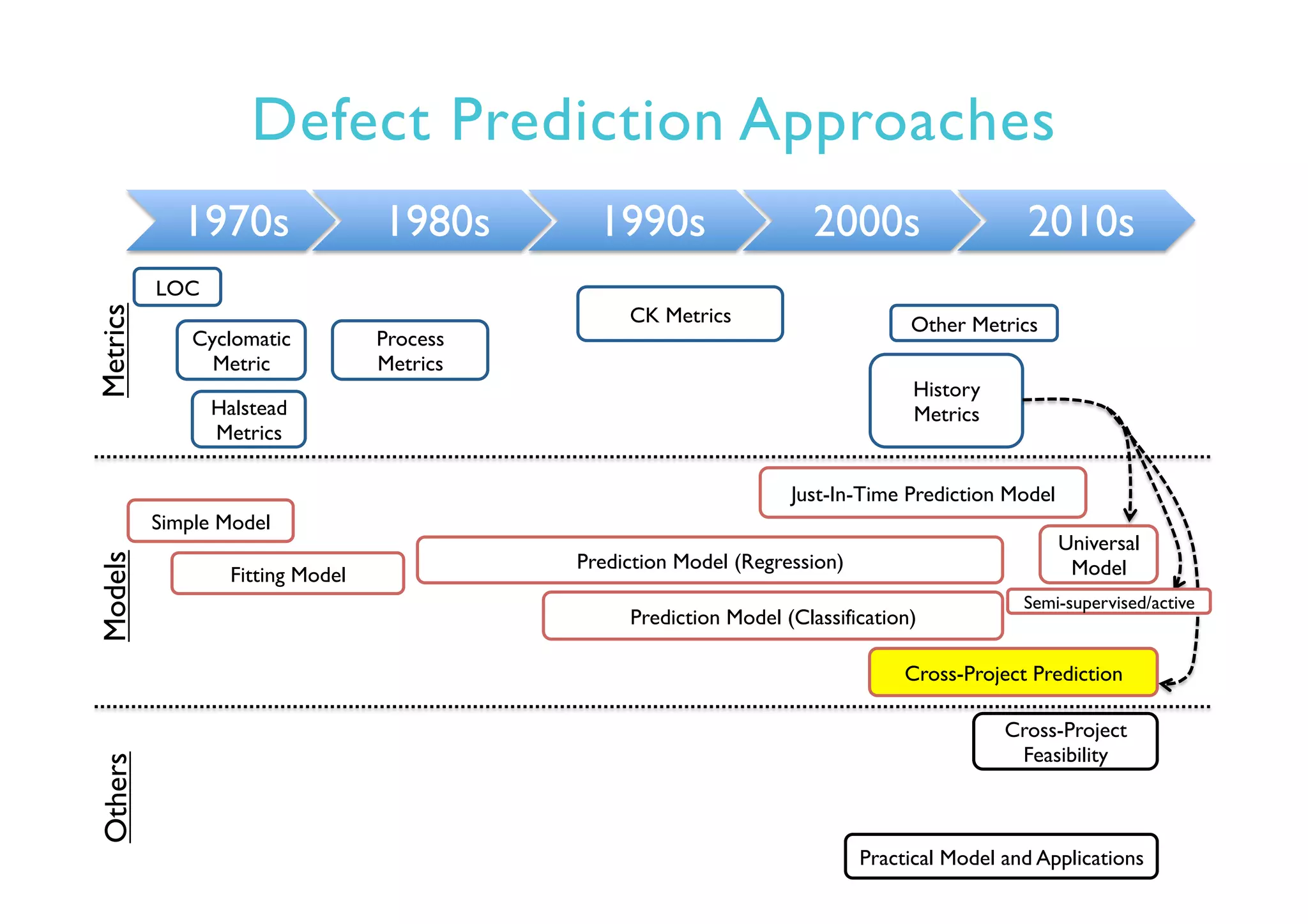
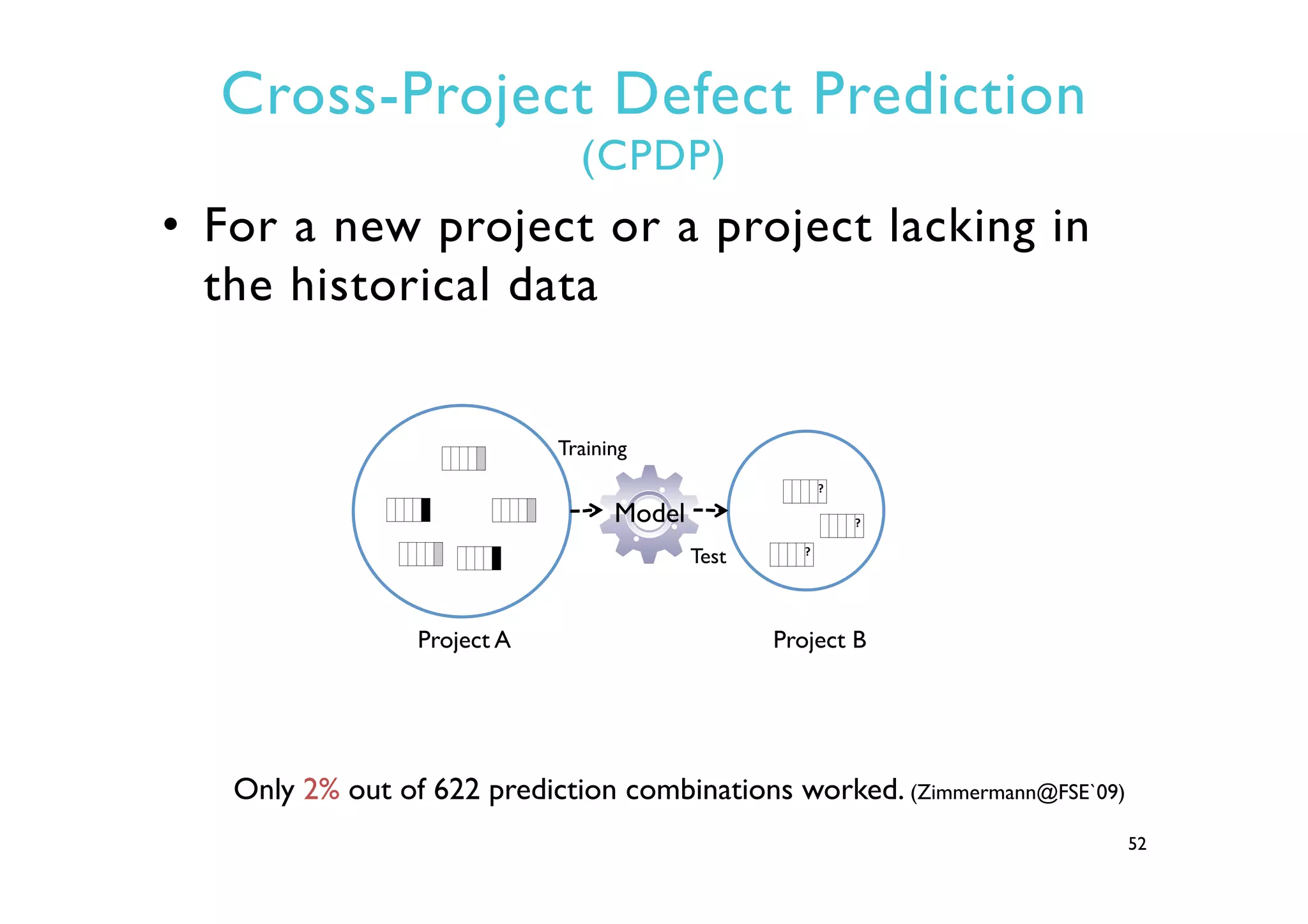
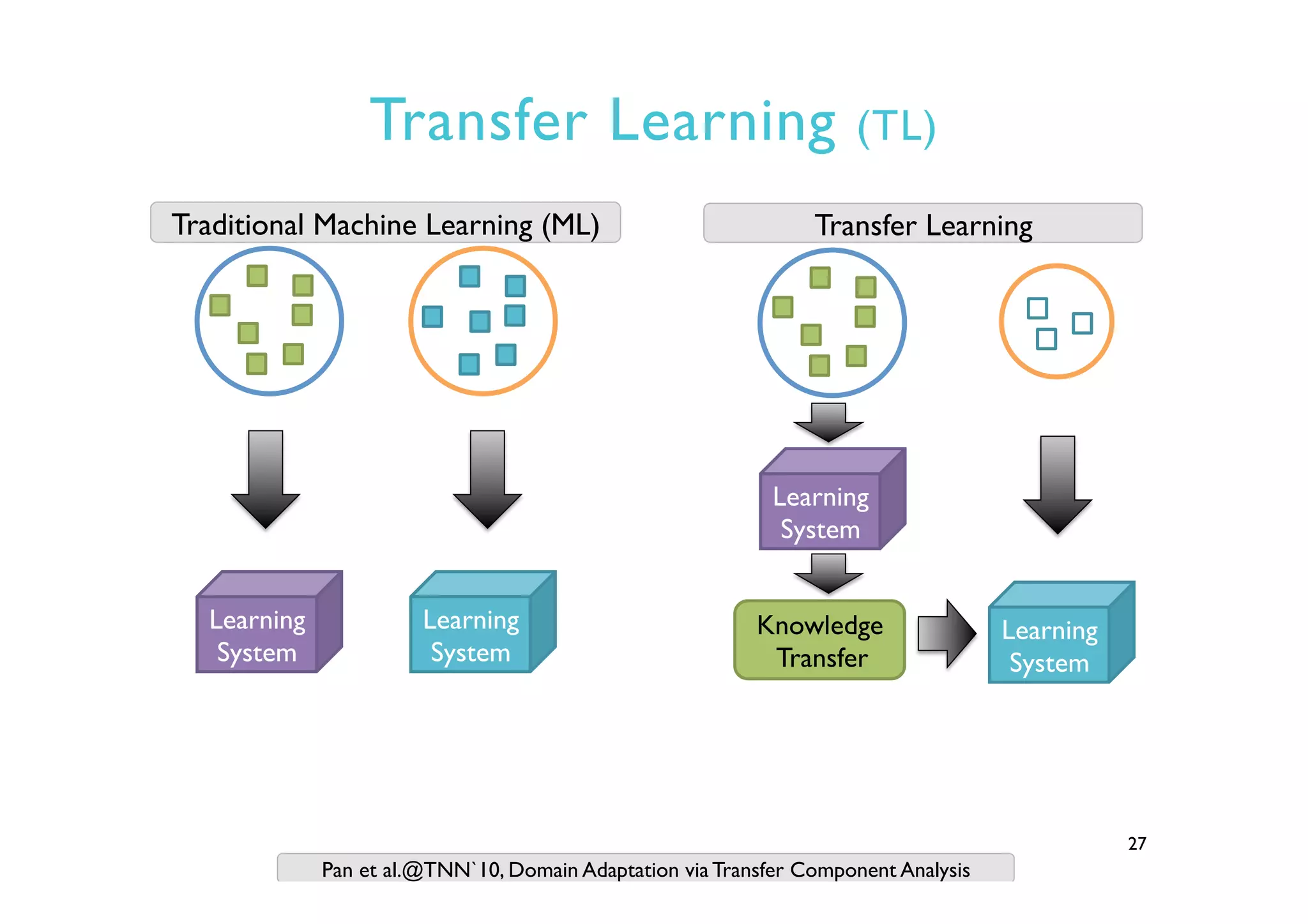
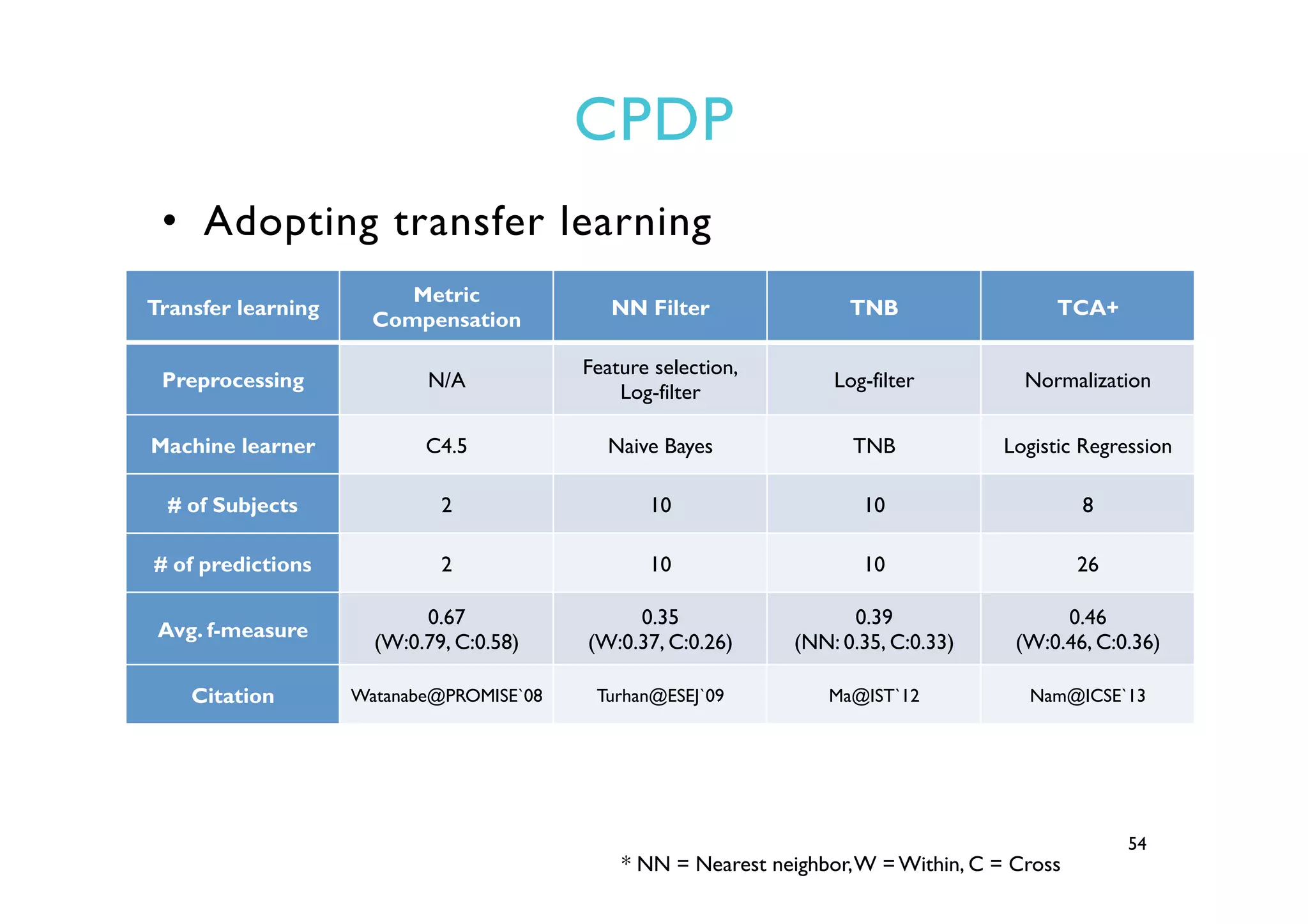
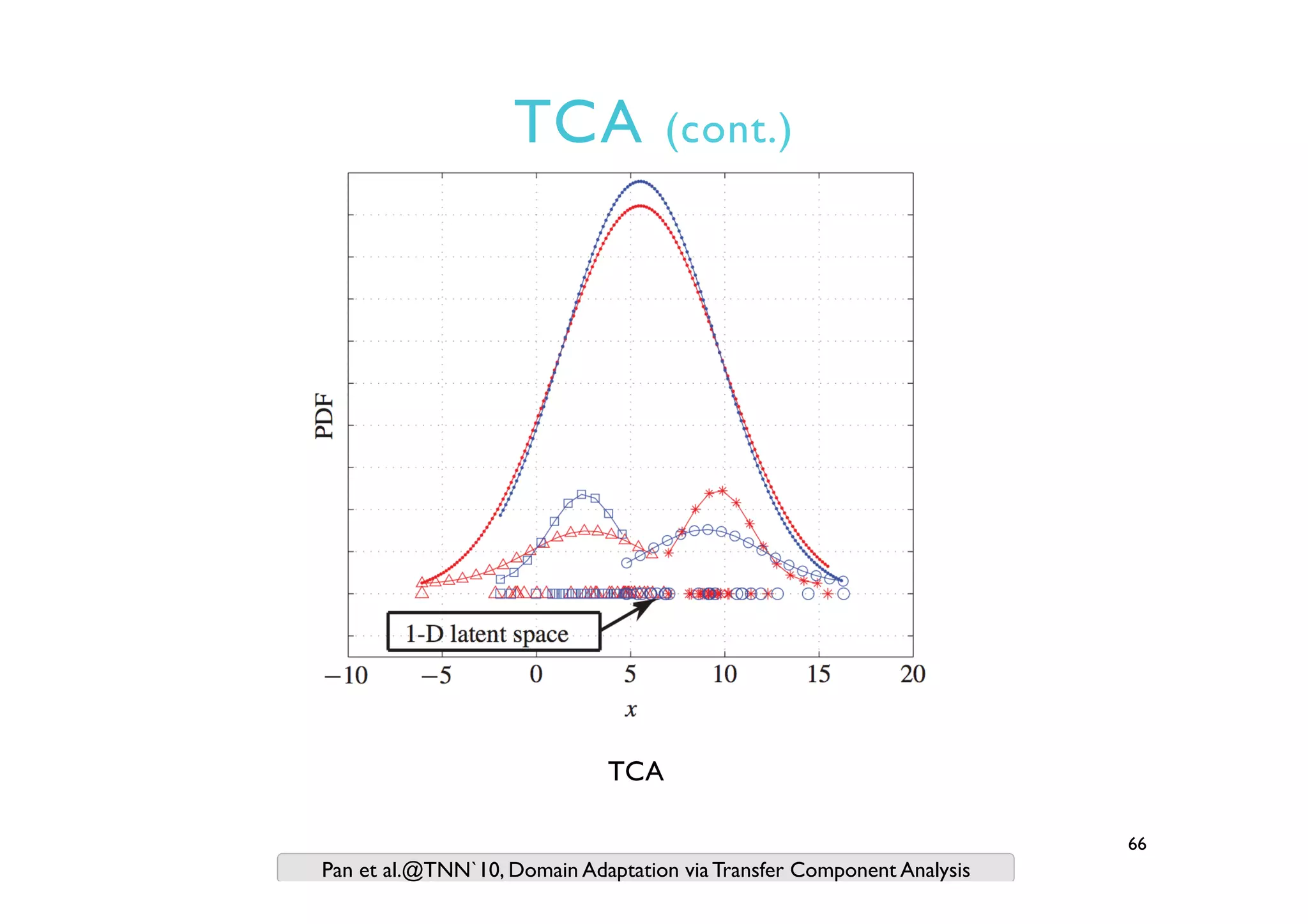
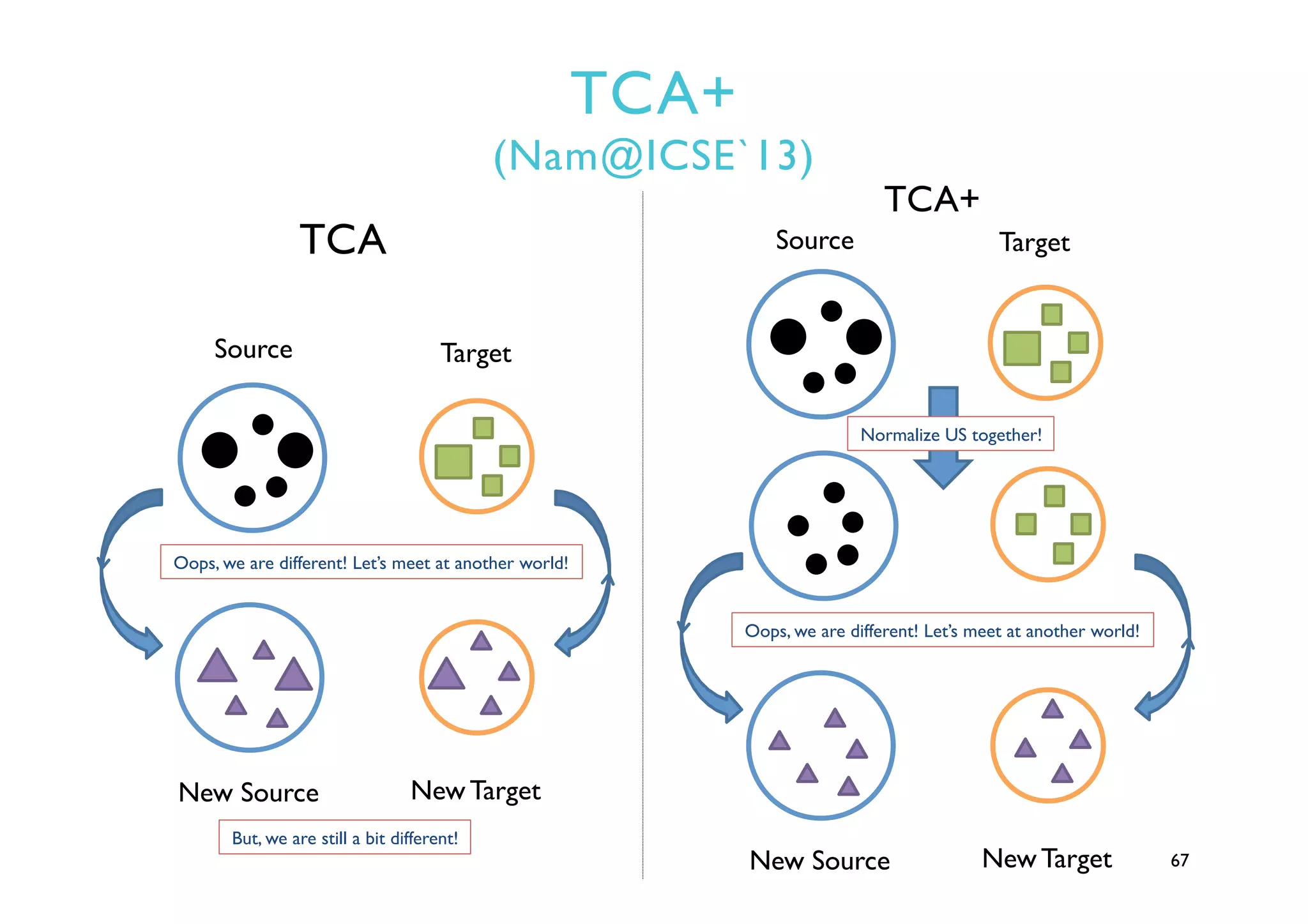
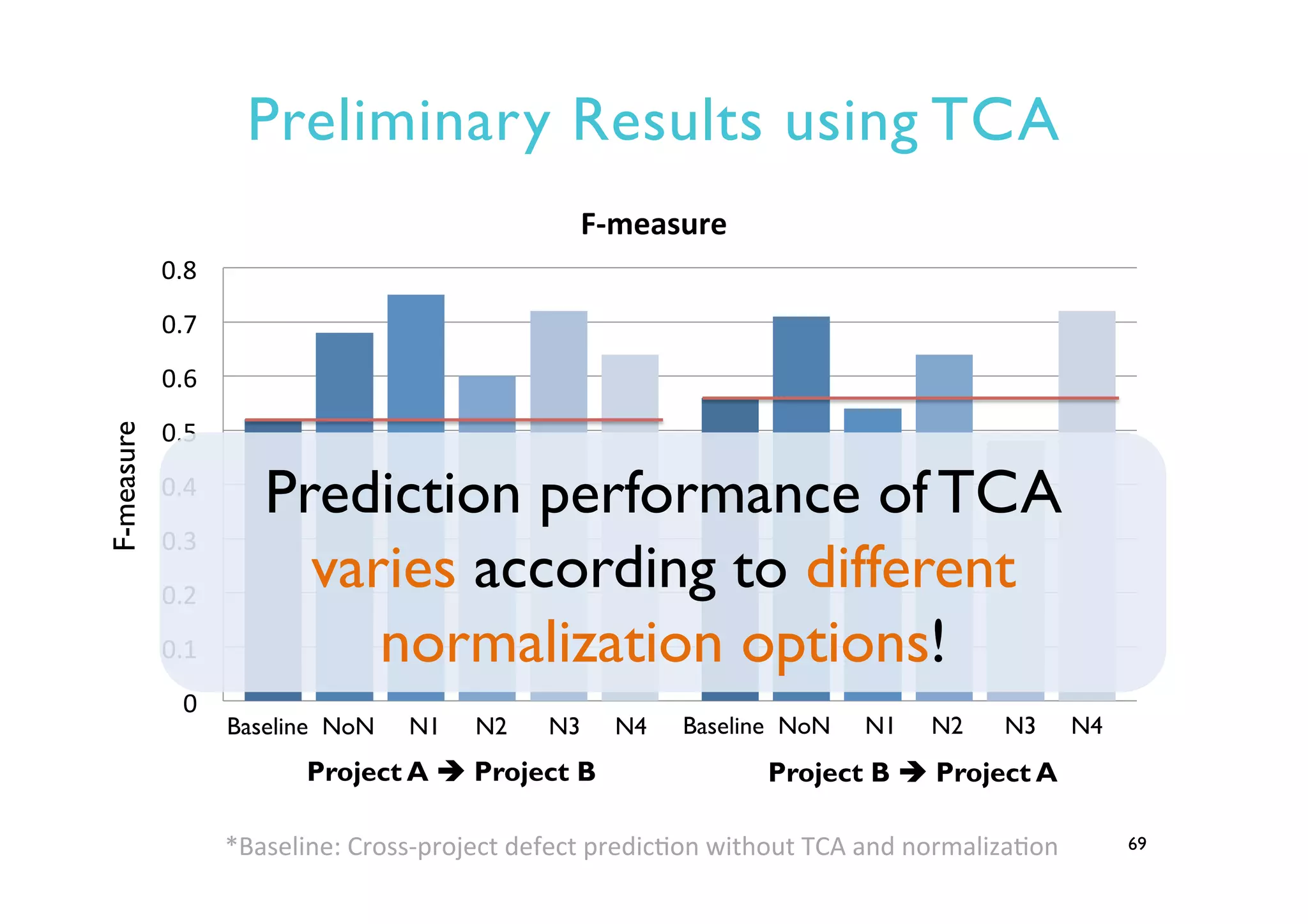
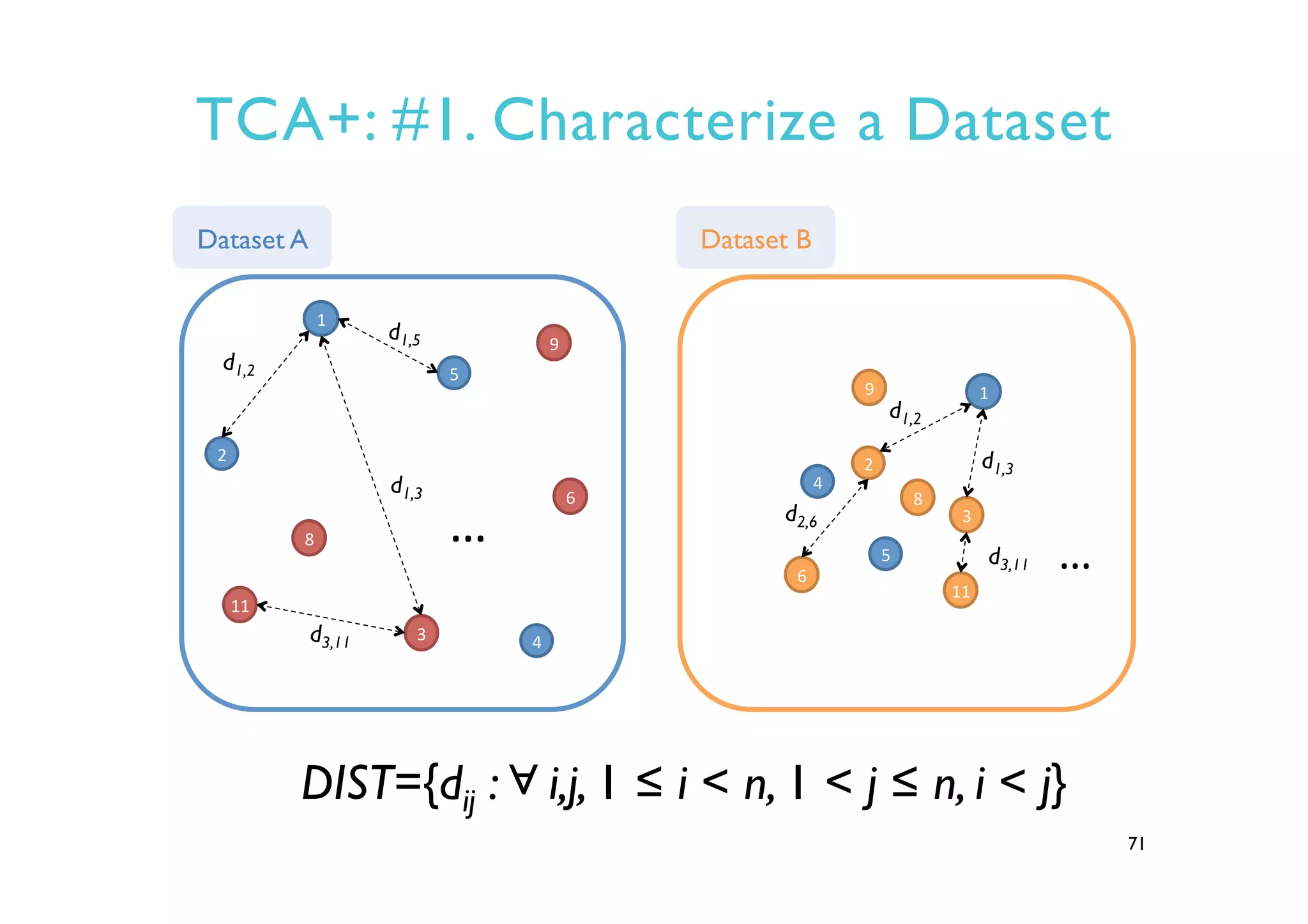
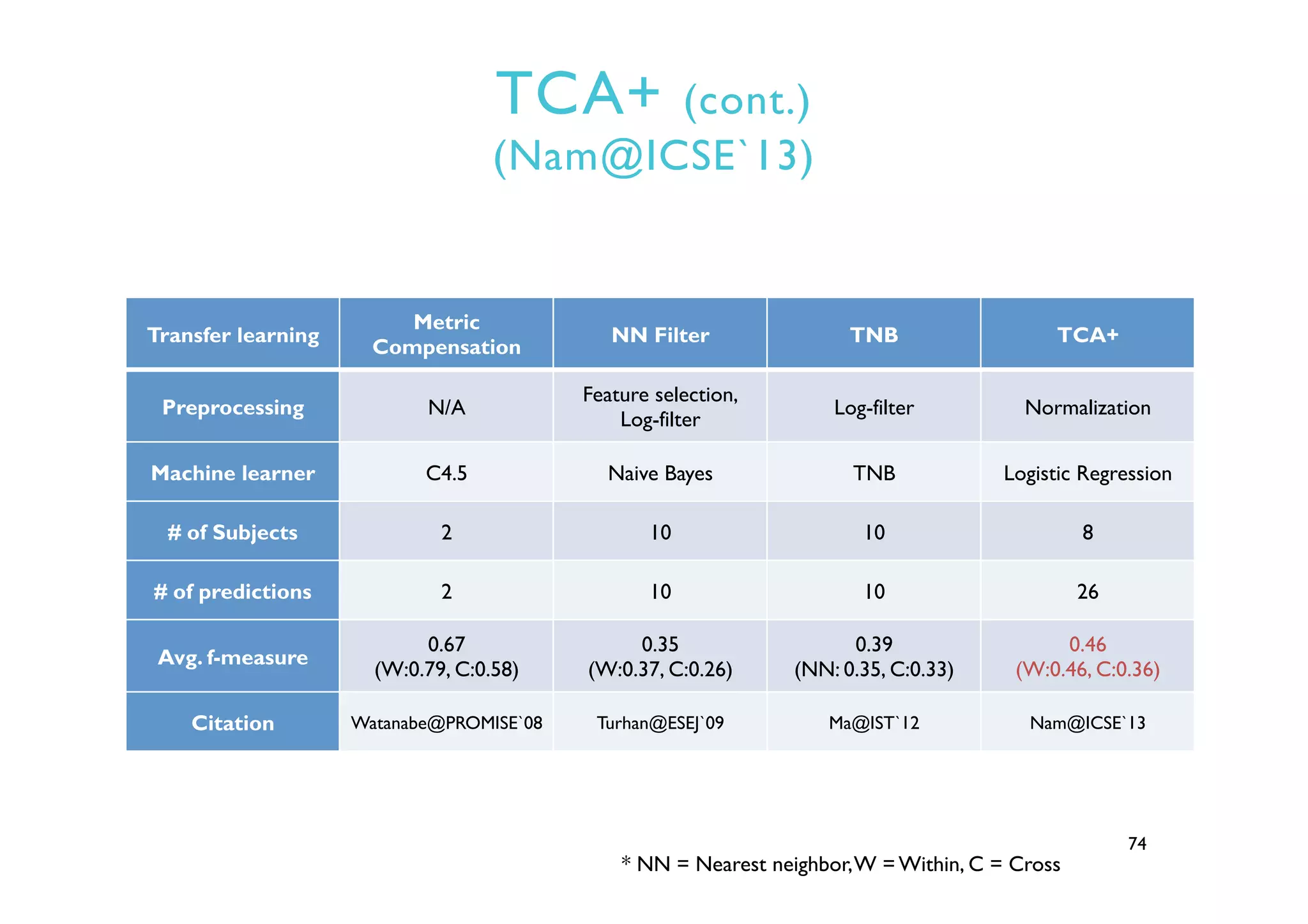
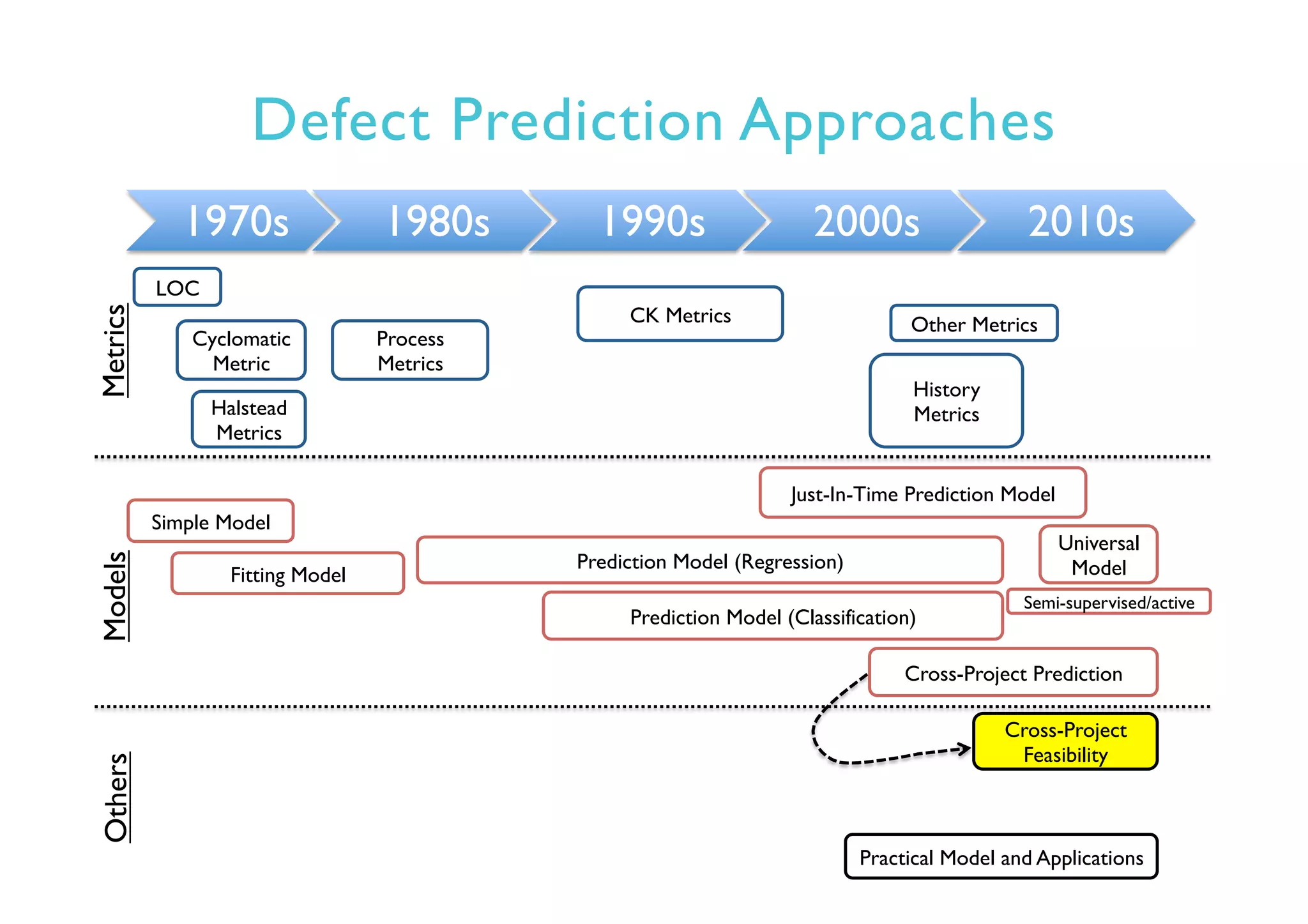
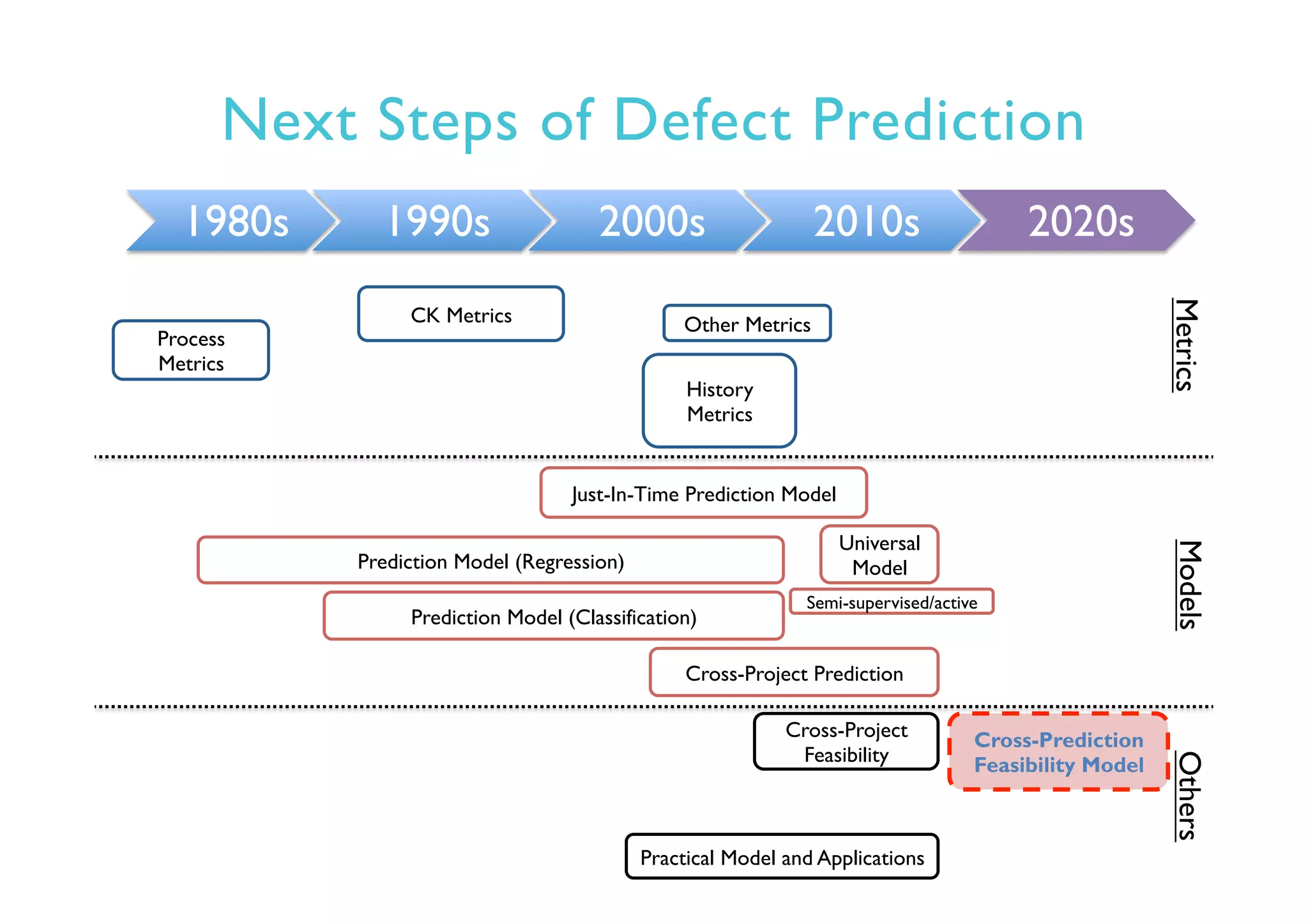
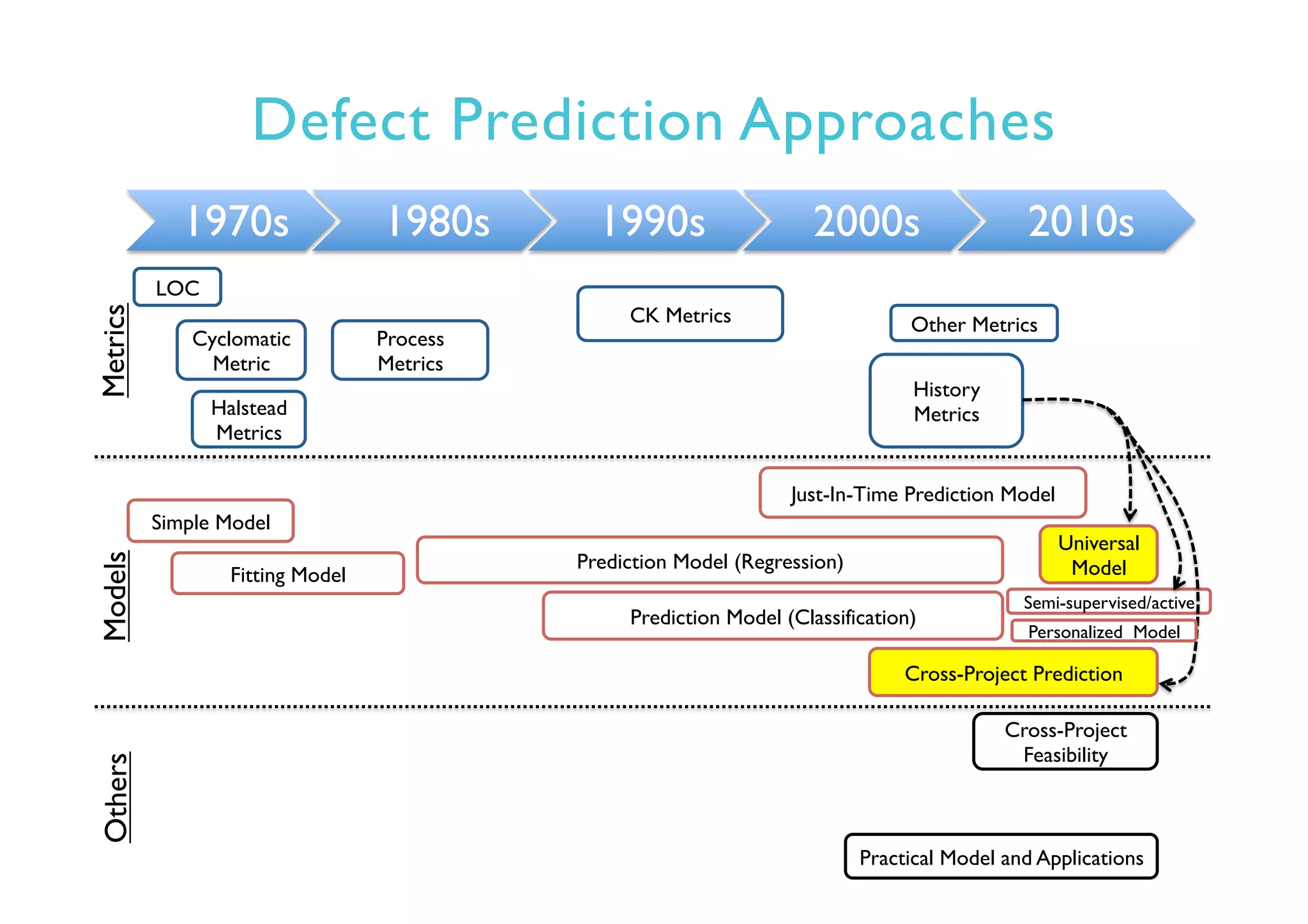
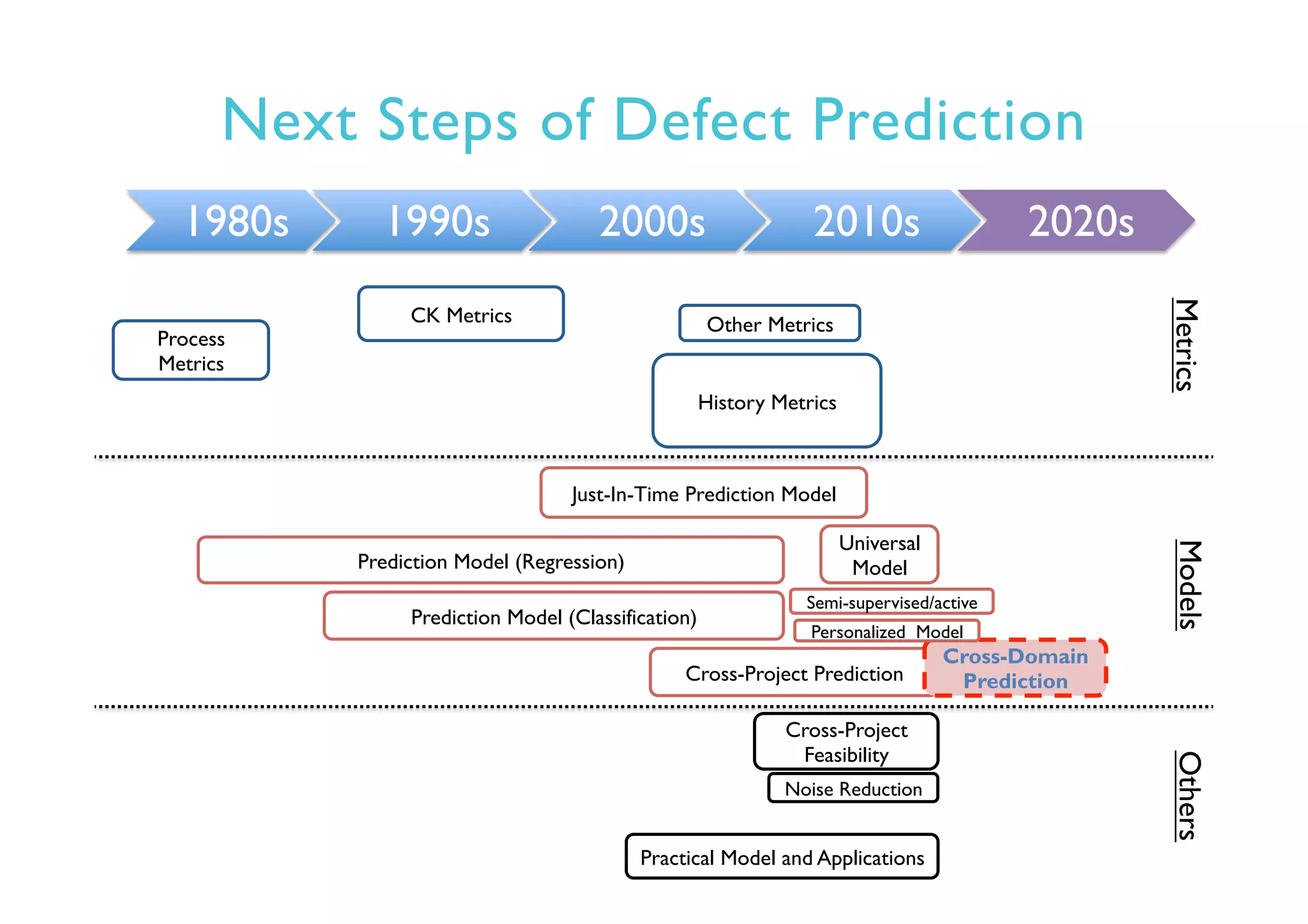
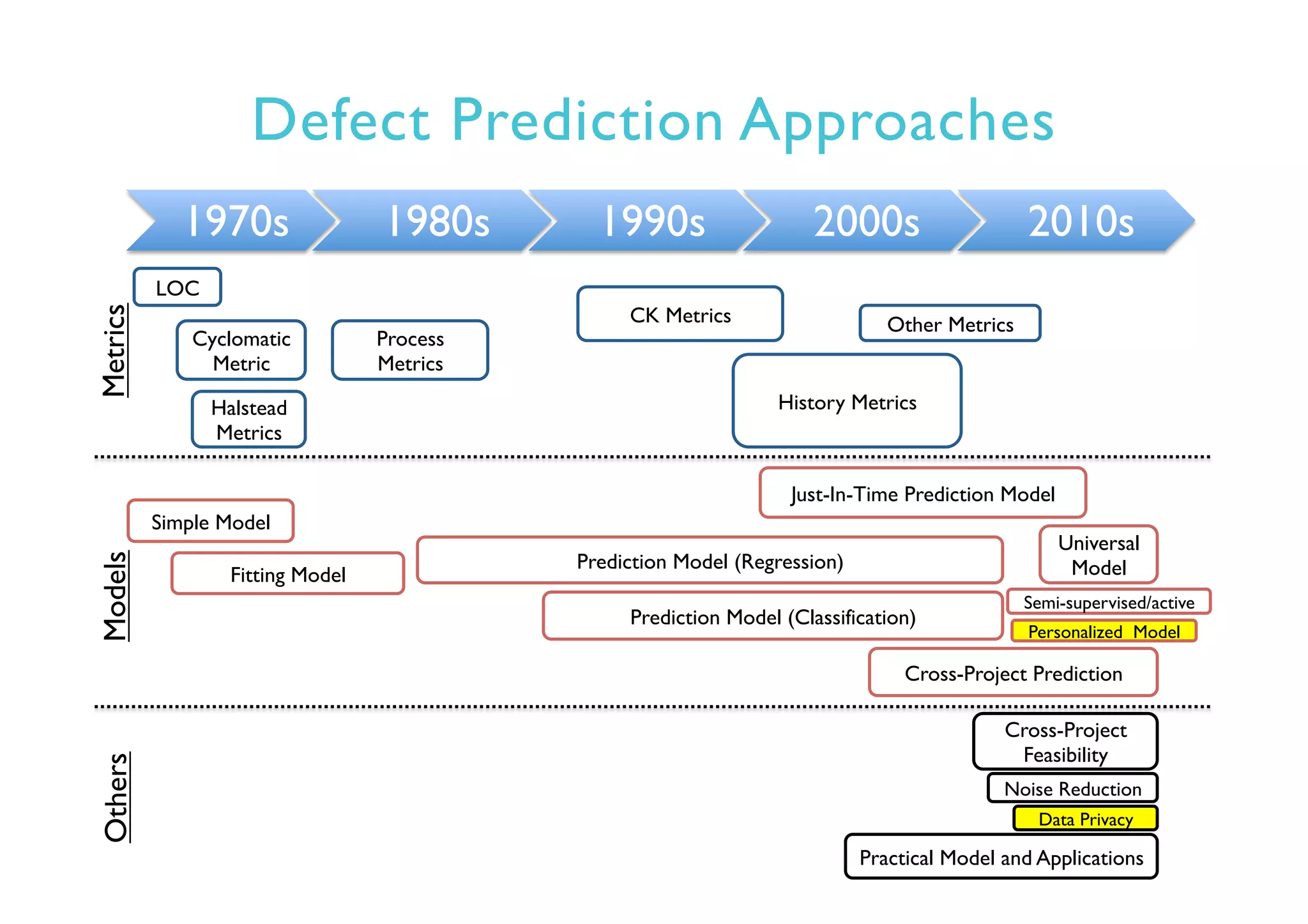
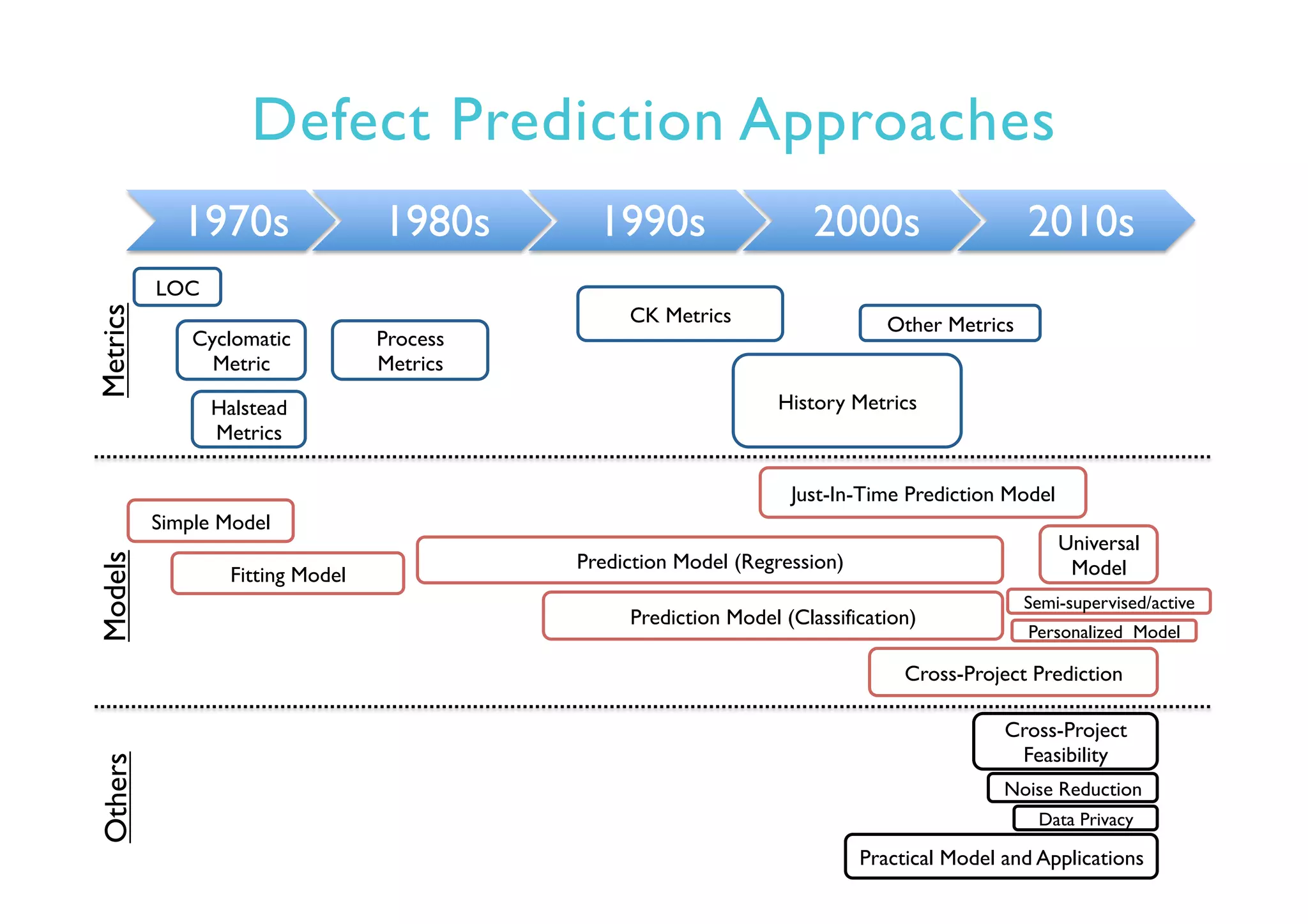
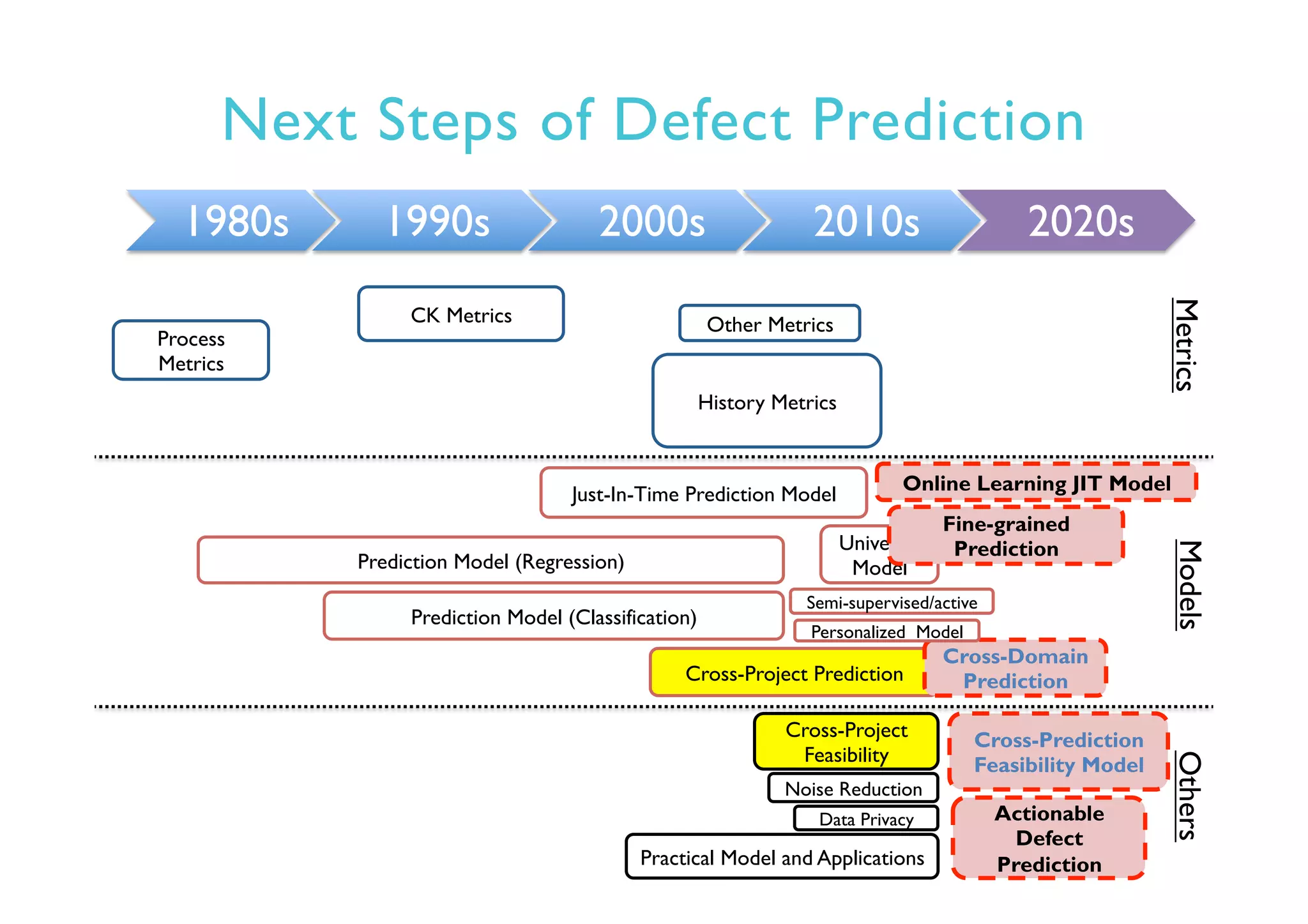
This document provides an outline and overview of approaches to software defect prediction. It discusses early approaches using simple metrics like lines of code in the 1970s and complexity metrics/fitting models in the 1980s. Prediction models using regression and classification emerged in the 1990s. Just-in-time prediction models and practical applications in industry are discussed for the 2000s. The use of history metrics from software repositories and challenges of cross-project prediction are also summarized.