

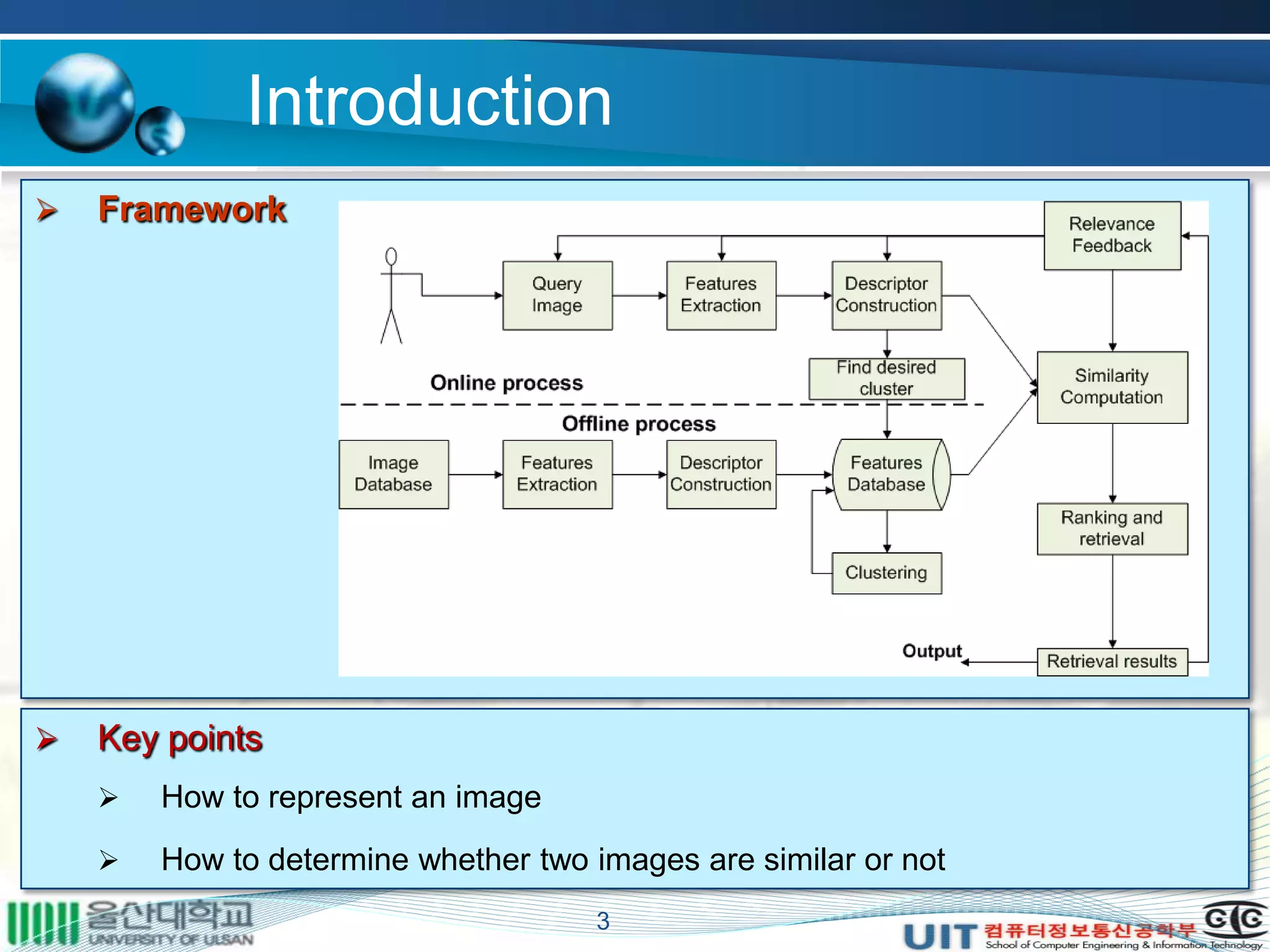






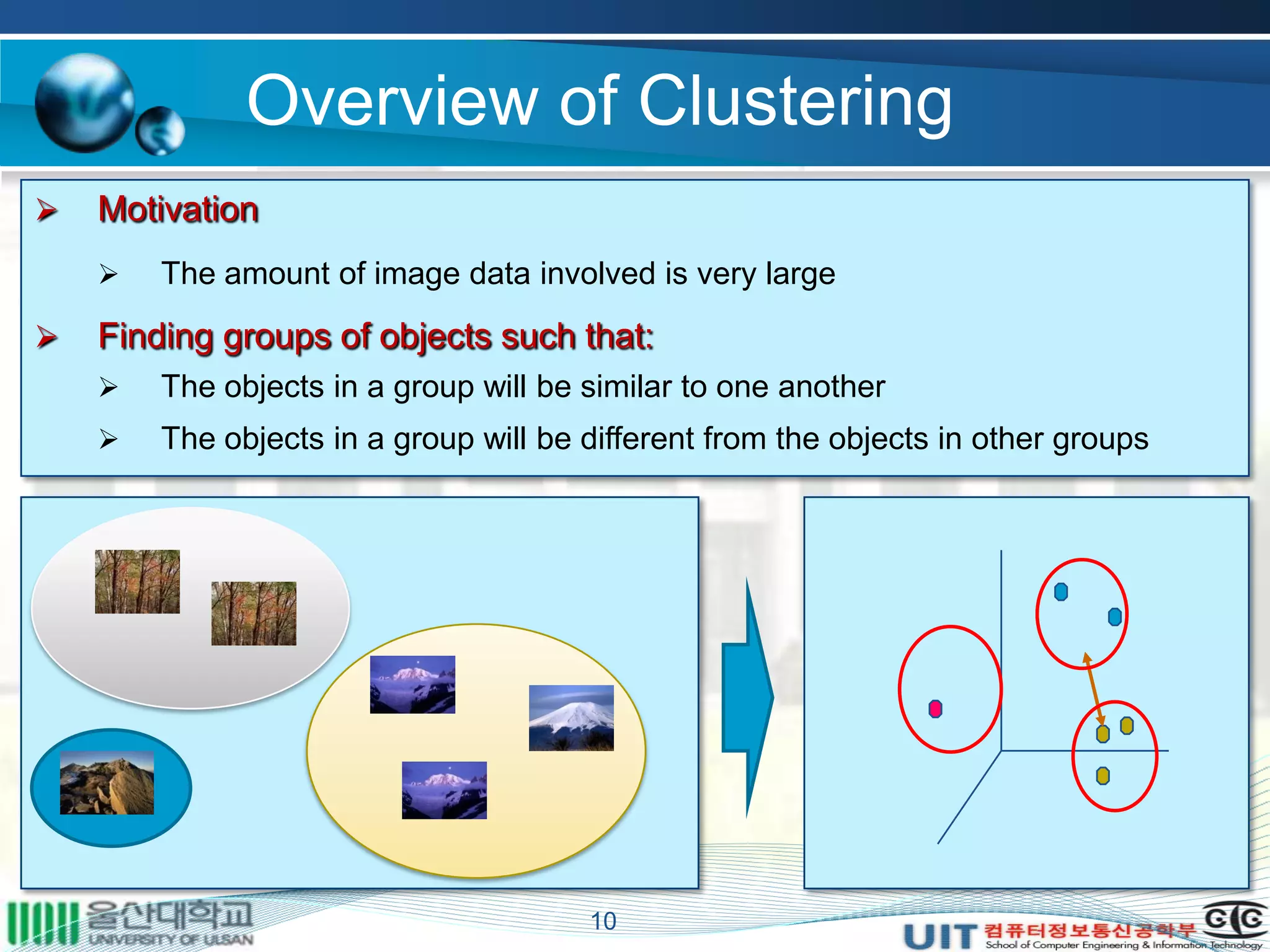

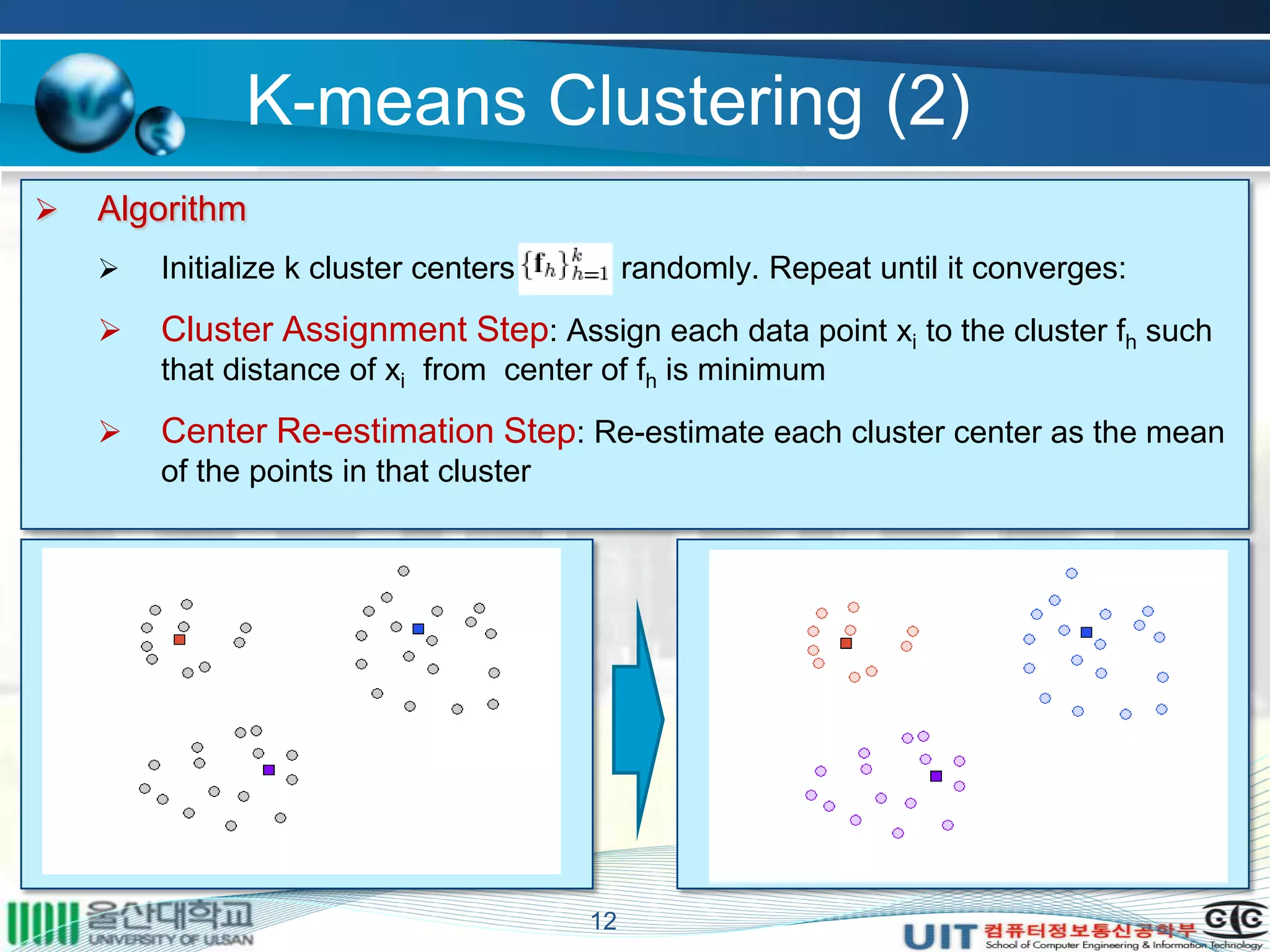


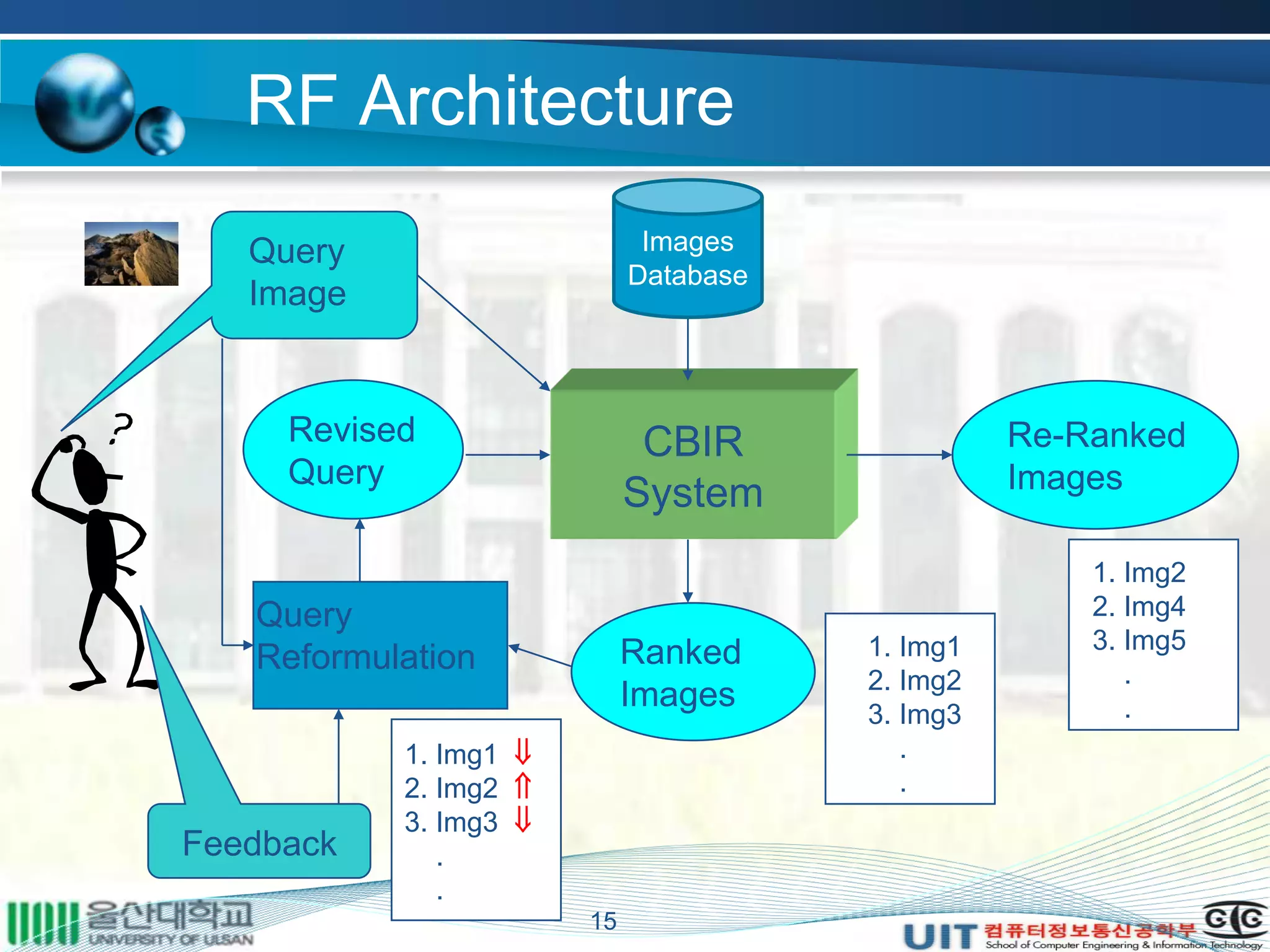



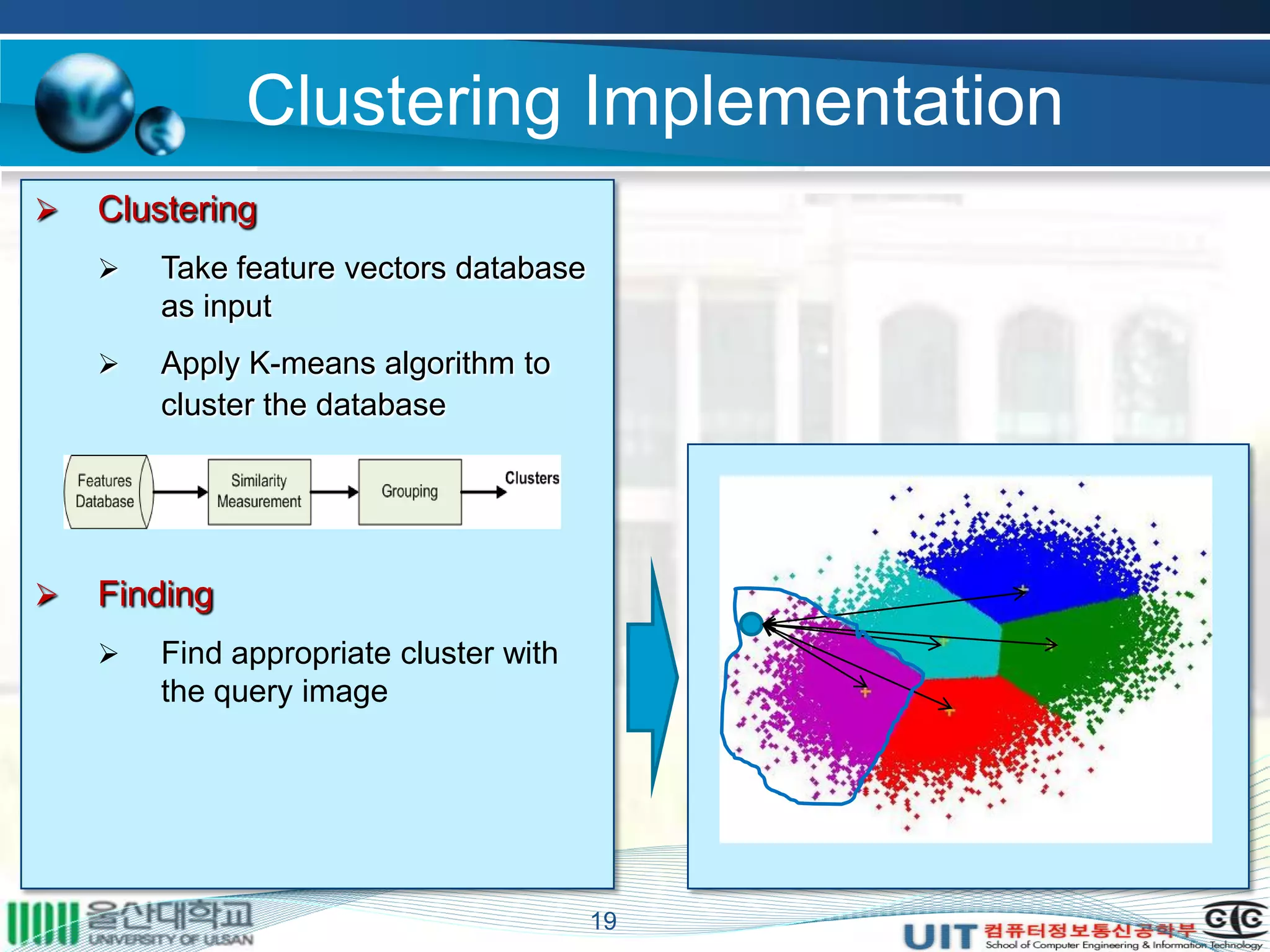
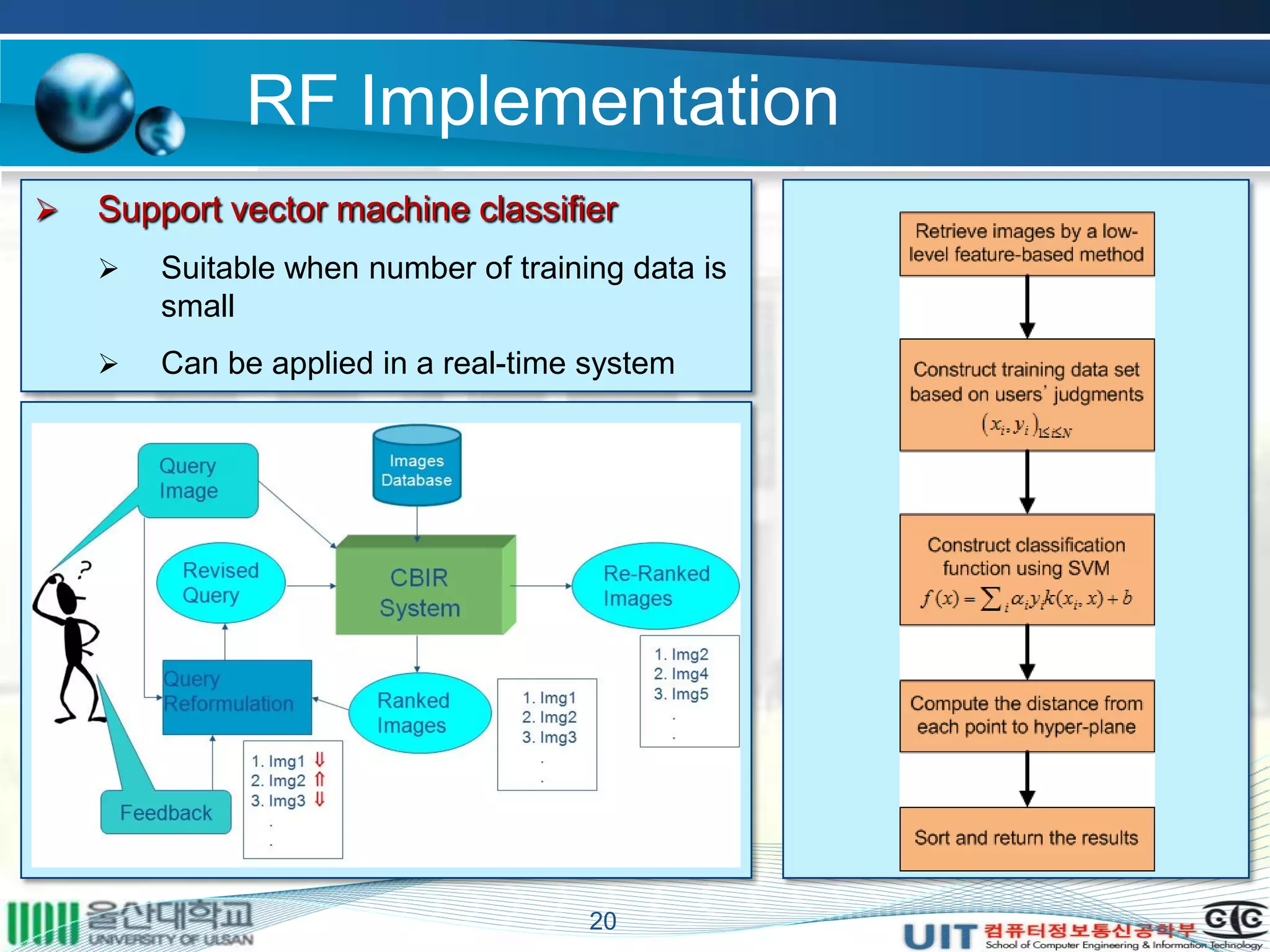


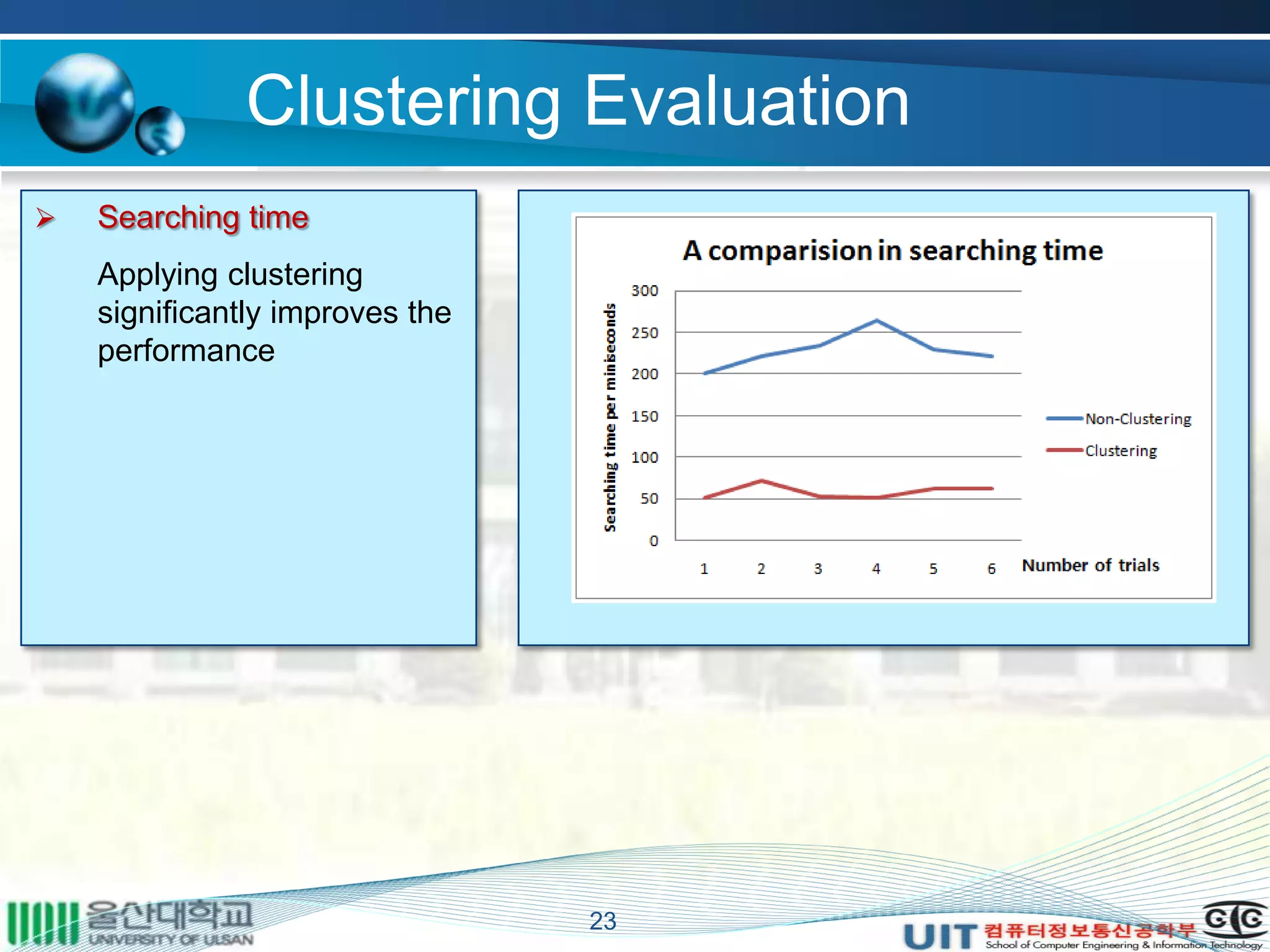





The document summarizes a master's thesis that proposed improvements to content-based image retrieval systems through clustering and relevance feedback. It describes extracting image features, measuring similarity, clustering images using k-means, obtaining user feedback to reformulate queries, and using support vector machines for relevance feedback. The implementation clustered a database of 9918 images, showed improved search times with clustering, and increased accuracy through iterative relevance feedback. The thesis demonstrated a complete content-based image retrieval system with enhanced performance.



































































