Downloaded 60 times


















![Page | 24
BREAST CANCER DETECTION USING PROTEOMES
axons. Each neural unit is connected with many others, and links can enhance or inhibit the
activation state of adjoining neural units. [further explanation needed] Each individual neural
unit computes using summation function. There may be a threshold function or limiting function
on each connection and on the unit itself, such that the signal must surpass the limit before
propagating to other neurons. These systems are self-learning and trained, rather than explicitly
programmed, and excel in areas where the solution or feature detection is difficult to express in
a traditional computer program.
The neural net is configured as further,
n_nodes_hl1 = 100
n_nodes_hl2 = 200
n_nodes_hl3 = 100
n_classes = 5
batch_size = 3
hm_epochs = 300
The accuracy obtained is 66.67%.
UNSUPERVISED LEARNING: K MEANS CLUSTERING
k-means is one of the simplest unsupervised learning algorithms that solve the well-known
clustering problem. The procedure follows a simple and easy way to classify a given data
set through a certain number of clusters (assume k clusters) fixed apriority. The main idea is
to define k centers, one for each cluster. These centers should be placed in a
cunning way because of different location causes different result. So, the better choice is to
place them as much as possible far away from each other.
The next step is to take each point belonging to a given data set and associate it to the nearest
center. When no point is pending, the first step is completed and an early group age is done. At
this point we need to re-calculate k new centroids as barycenter of the clusters resulting from
the previous step. After we have these k new centroids, a new binding must be
done between the same data set points and the nearest new center. A loop has been generated.
Because of this loop we may notice that the k centers change their location step by step until no
more changes are done or in other words centers do not move any more.
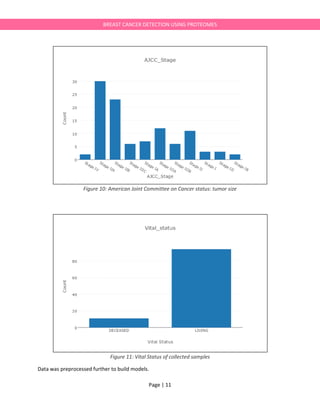
We generated 5 Principal Components but used only 3 Principal Components to show the Data
Points and the result generated is as shown below:](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-24-320.jpg)




![Page | 33
BREAST CANCER DETECTION USING PROTEOMES
#Edit some names for potential matching later (TCGA)
Proteomics.columns=[re.sub('.[0-9][0-9]TCGA','',x) for x in Proteomics.columns]
IDs['Complete_TCGA_ID']=[re.sub('TCGA-','',x) for x in IDs['Complete_TCGA_ID']]
#Code the tumor type to the patient ID
IDDict=dict(zip(IDs['Complete_TCGA_ID'],IDs['Tumor']))
#Add the healthy subjects
IDDict[Proteomics.columns[-3]]='Healthy'
IDDict[Proteomics.columns[-2]]='Healthy'
IDDict[Proteomics.columns[-1]]='Healthy'
#Get the X variables separate
#Excluding 1st three columns
ProteomicsXRaw=Proteomics[Proteomics.columns[3:len(Proteomics.columns)]].T
ProteomicsXRaw.head()
ProteomicsXRaw.shape](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-33-320.jpg)

![Page | 35
BREAST CANCER DETECTION USING PROTEOMES
#Scaling
for inputs in range(len(ProteomicsX.T)):
ProteomicsX.T[inputs]=preprocessing.scale(ProteomicsX.T[inputs])
#How is the distribution of the sample intensities after imputing and transforming? More suitable
for PCA?
SampleIntensities=ProteomicsX.sum(axis=0)
SampleDist=plt.hist(SampleIntensities)
plt.title('Sample Intensity Distribution')
plt.show()
IntermedSet=[IDDict[x] for x in list(ProteomicsXRaw.index)]
#PCA
pca=PCA(n_components=5)
ProteomicsX_pca=pca.fit(ProteomicsX)
ProteomicsX_pca2=ProteomicsX_pca.transform(ProteomicsX)](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-35-320.jpg)
![Page | 36
BREAST CANCER DETECTION USING PROTEOMES
#Merging two arrays, one with PCAs and another with tumor types.
a = pd.DataFrame(ProteomicsX_pca2)
b = pd.DataFrame(IntermedSet)
frames = [a,b]
result = pd.concat(frames, axis = 1)
#rename columns
result.columns = ['pca_1','pca_2','pca_3','pca_4','pca_5','tumor']
Results.head()
Result.shape
#split into test train.
X1 = result[[0,1,2,3,4]]
y1 = result[[5]]
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X1, y1, test_size=0.3, random_state=45)
X_train1, X_test1, y_train1, y_test1 = train_test_split(X1, y1, test_size=0.3, random_state=45)
#make y dummy variable for train1 and test1
i = ['tumor']
y_train1 = pd.get_dummies(y_train1, columns = i, drop_first = False)
y_test1 = pd.get_dummies(y_test1, columns = i, drop_first = False)](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-36-320.jpg)
![Page | 37
BREAST CANCER DETECTION USING PROTEOMES
#visualization
#see the tumor types and their frequency.
import plotly.plotly as py
import plotly.graph_objs as go
import numpy as np
x = y1.tumor
data = [go.Histogram(x=x)]
layout = go.Layout(
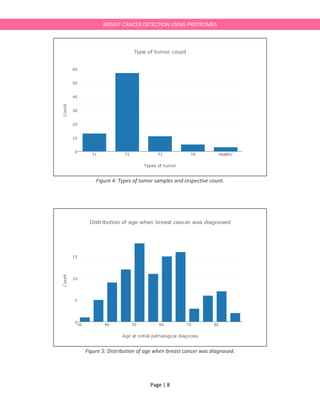
title='Type of tumor count',
xaxis=dict(
title='Types of tumor'
),
yaxis=dict(
title='Count'
),
bargap=0.2,
bargroupgap=0.1
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='styled histogram')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-37-320.jpg)
![Page | 38
BREAST CANCER DETECTION USING PROTEOMES
#see the age distribution of smaples.
import plotly.plotly as py
import plotly.graph_objs as go
import numpy as np
x = IDs.Age_at_Initial_Pathologic_Diagnosis
data = [go.Histogram(x=x)]
layout = go.Layout(
title='Distribution of age when breast cancer was diagnosed',
xaxis=dict(
title='Age at initial pathalogical diagnosis'
),
yaxis=dict(
title='Count'
),
bargap=0.2,
bargroupgap=0.1
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='styled histogram')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-38-320.jpg)
![Page | 39
BREAST CANCER DETECTION USING PROTEOMES
# Estrogen status.
x = IDs.ER_Status
data = [go.Histogram(x=x)]
layout = go.Layout(
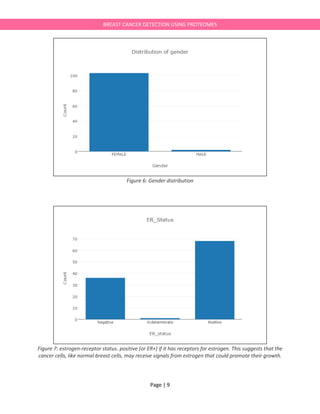
title='ER_Status',
xaxis=dict(
title='ER_status'
),
yaxis=dict(
title='Count'
),
bargap=0.2,
bargroupgap=0.1
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='styled histogram')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-39-320.jpg)
![Page | 40
BREAST CANCER DETECTION USING PROTEOMES
#Prostegene status
x = IDs.PR_Status
data = [go.Histogram(x=x)]
layout = go.Layout(
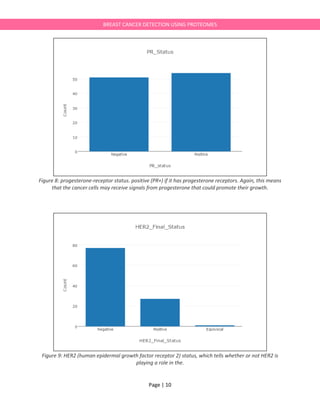
title='PR_Status',
xaxis=dict(
title='PR_status'
),
yaxis=dict(
title='Count'
),
bargap=0.2,
bargroupgap=0.1
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='styled histogram')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-40-320.jpg)
![Page | 41
BREAST CANCER DETECTION USING PROTEOMES
#HER2 Status
x = IDs.HER2_Final_Status
data = [go.Histogram(x=x)]
layout = go.Layout(
title='HER2_Final_Status',
xaxis=dict(
title='HER2_Final_Status'
),
yaxis=dict(
title='Count'
),
bargap=0.2,
bargroupgap=0.1
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='styled histogram')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-41-320.jpg)
![Page | 42
BREAST CANCER DETECTION USING PROTEOMES
#AJCC status of samples.
x = IDs.AJCC_Stage
data = [go.Histogram(x=x)]
layout = go.Layout(
title='AJCC_Stage',
xaxis=dict(
title='AJCC_Stage'
),
yaxis=dict(
title='Count'
),
bargap=0.2,
bargroupgap=0.1
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='styled histogram')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-42-320.jpg)
![Page | 43
BREAST CANCER DETECTION USING PROTEOMES
#Vital status of samples.
x = IDs.Vital_Status
data = [go.Histogram(x=x)]
layout = go.Layout(
title='Vital_status',
xaxis=dict(
title='Vital Status'
),
yaxis=dict(
title='Count'
),
bargap=0.2,
bargroupgap=0.1
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='styled histogram')
# Classification models_Supervised learning](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-43-320.jpg)

![Page | 45
BREAST CANCER DETECTION USING PROTEOMES
from sklearn.preprocessing import label_binarize
cm_svm = confusion_matrix(y_test, clf.predict(X_test))
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(cm_svm)
plt.title('Confusion matrix of the classifier for Support Vector machines')
fig.colorbar(cax)
labels = ['Healthy','T1','T2','T3','T4']
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
#Logistic regression
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
# estimator is intiated
log = LogisticRegression()
# model fitting
log.fit(X_train, y_train)](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-45-320.jpg)
![Page | 46
BREAST CANCER DETECTION USING PROTEOMES
# prediction
y_pred_log = log.predict(X_test)
# model score on accuracy
pred_logreg = metrics.accuracy_score(y_test, y_pred_log)
print ("Accuracy for Logistic Regression: {}%".format(pred_logreg * 100))
#Confusion matrix
cm_log = confusion_matrix(y_test, log.predict(X_test))
cm_df = pd.DataFrame(cm_log.T, index=clf.classes_, columns=clf.classes_)
cm_df.index.name = 'Predicted'
cm_df.columns.name = 'True'
print(cm_df)
#Confusion matrix visualization
cm_log = confusion_matrix(y_test, y_pred_log)
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(cm_log)
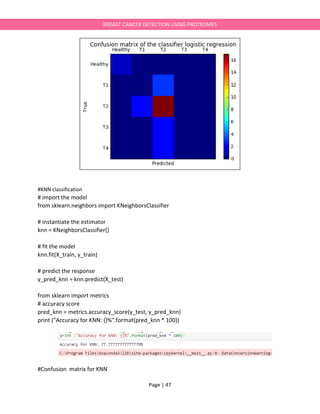
plt.title('Confusion matrix of the classifier logistic regression')
fig.colorbar(cax)
labels = ['Healthy','T1','T2','T3','T4']
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
True Healthy T1 T2 T3 T4
Predicted
Healthy 1 0 0 0 0
T1 0 0 2 0 0
T2 0 3 17 2 2
T3 0 0 0 0 0
T4 0 0 0 0 0](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-46-320.jpg)
![Page | 48
BREAST CANCER DETECTION USING PROTEOMES
cm_dt_gini = confusion_matrix(y_test, knn.predict(X_test))
cm_df = pd.DataFrame(cm_dt_gini.T, index=clf.classes_, columns=clf.classes_)
cm_df.index.name = 'Predicted'
cm_df.columns.name = 'True'
print(cm_df)
#Confusion matrix _ KNN visualization
cm_knn = confusion_matrix(y_test, y_pred_knn)
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(cm_knn)
plt.title('Confusion matrix of the classifier KNN')
fig.colorbar(cax)
labels = ['Healthy','T1','T2','T3','T4']
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
True Healthy T1 T2 T3 T4
Predicted
Healthy 0 0 0 0 0
T1 0 2 0 0 0
T2 1 0 19 2 2
T3 0 1 0 0 0
T4 0 0 0 0 0](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-48-320.jpg)

![Page | 50
BREAST CANCER DETECTION USING PROTEOMES
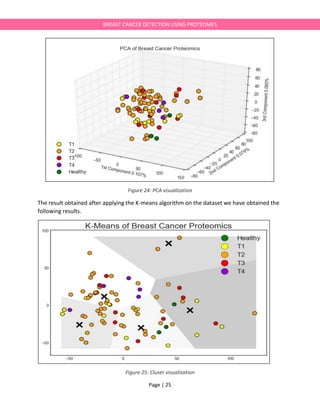
#confusion matrix Gini
cm_dt_gini = confusion_matrix(y_test, model_gini.predict(X_test))
cm_df = pd.DataFrame(cm_dt_gini.T, index=clf.classes_, columns=clf.classes_)
cm_df.index.name = 'Predicted'
cm_df.columns.name = 'True'
print(cm_df)
#confusion matrix Gini visualization.
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(cm_dt_gini)
plt.title('Confusion matrix of the decision tree classifier (gini)')
fig.colorbar(cax)
labels = ['Healthy','T1','T2','T3','T4']
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
True Healthy T1 T2 T3 T4
Predicted
Healthy 0 0 0 0 0
T1 0 2 6 0 0
T2 1 0 10 2 1
T3 0 1 2 0 1
T4 0 0 1 0 0](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-50-320.jpg)

![Page | 52
BREAST CANCER DETECTION USING PROTEOMES
labels = ['Healthy','T1','T2','T3','T4']
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
#Gradient boosting.
from sklearn.ensemble import GradientBoostingClassifier
gbf = GradientBoostingClassifier(n_estimators=100, learning_rate=1, max_depth=3)
gbf.fit(X_train, y_train)
#getting accuracy of gradient boosting.](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-52-320.jpg)
![Page | 53
BREAST CANCER DETECTION USING PROTEOMES
predicted_train_gbf = gbf.predict(X_train)
#print ("Accuracy score for Gradient boosting classifier with train data set is:",
(accuracy_score(y_train,predicted_train_gbf))*100,"%")
predicted_test_gbf = gbf.predict(X_test)
print ("Accuracy score for Gradient boosting classifier with test data set is:",
((accuracy_score(y_test,predicted_test_gbf))*100),"%")
#confusion matrix gradient boosting.
cm_gb = confusion_matrix(y_test, gbf.predict(X_test))
cm_df = pd.DataFrame(cm_gb.T, index=clf.classes_, columns=clf.classes_)
cm_df.index.name = 'Predicted'
cm_df.columns.name = 'True'
print(cm_df)
#confusion matrix gradient boosting visualization
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(cm_gb)
plt.title('Confusion matrix of the gradient boosting)')
fig.colorbar(cax)
labels = ['Healthy','T1','T2','T3','T4']
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
True Healthy T1 T2 T3 T4
Predicted
Healthy 0 0 0 0 0
T1 0 2 1 0 0
T2 1 0 17 2 2
T3 0 1 1 0 0
T4 0 0 0 0 0](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-53-320.jpg)

![Page | 55
BREAST CANCER DETECTION USING PROTEOMES
cm_df = pd.DataFrame(cm_rf, index=clf.classes_, columns=clf.classes_)
cm_df.index.name = 'Predicted'
cm_df.columns.name = 'True'
print(cm_df)
#confusion matrix for random forest visualization.
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(cm_rf)
plt.title('Confusion matrix of the random forest)')
fig.colorbar(cax)
labels = ['Healthy','T1','T2','T3','T4']
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
True Healthy T1 T2 T3 T4
Predicted
Healthy 0 0 1 0 0
T1 0 2 0 1 0
T2 0 1 17 1 0
T3 0 0 2 0 0
T4 0 0 2 0 0](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-55-320.jpg)
![Page | 56
BREAST CANCER DETECTION USING PROTEOMES
#Tensor flow.
n_nodes_hl1 = 30
n_nodes_hl2 = 30
n_nodes_hl3 = 30
n_nodes_hl4 = 30
n_nodes_hl5 = 30
n_classes = 5
batch_size = 20
hm_epochs = 500
x = tf.placeholder('float')
y = tf.placeholder('float')
hidden_1_layer = {'f_fum':n_nodes_hl1,
'weight':tf.Variable(tf.random_normal([5, n_nodes_hl1])),
'bias':tf.Variable(tf.random_normal([n_nodes_hl1]))}
hidden_2_layer = {'f_fum':n_nodes_hl2,
'weight':tf.Variable(tf.random_normal([n_nodes_hl1, n_nodes_hl2])),
'bias':tf.Variable(tf.random_normal([n_nodes_hl2]))}
hidden_3_layer = {'f_fum':n_nodes_hl3,
'weight':tf.Variable(tf.random_normal([n_nodes_hl2, n_nodes_hl3])),
'bias':tf.Variable(tf.random_normal([n_nodes_hl3]))}
hidden_4_layer = {'f_fum':n_nodes_hl4,
'weight':tf.Variable(tf.random_normal([n_nodes_hl3, n_nodes_hl4])),
'bias':tf.Variable(tf.random_normal([n_nodes_hl4]))}
hidden_5_layer = {'f_fum':n_nodes_hl5,
'weight':tf.Variable(tf.random_normal([n_nodes_hl4, n_nodes_hl5])),
'bias':tf.Variable(tf.random_normal([n_nodes_hl5]))}
output_layer = {'f_fum':None,
'weight':tf.Variable(tf.random_normal([n_nodes_hl5, n_classes])),
'bias':tf.Variable(tf.random_normal([n_classes])),}
# Nothing changes](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-56-320.jpg)
![Page | 57
BREAST CANCER DETECTION USING PROTEOMES
def neural_network_model(data):
l1 = tf.add(tf.matmul(data,hidden_1_layer['weight']), hidden_1_layer['bias'])
l1 = tf.nn.relu(l1)
l2 = tf.add(tf.matmul(l1,hidden_2_layer['weight']), hidden_2_layer['bias'])
l2 = tf.nn.relu(l2)
l3 = tf.add(tf.matmul(l2,hidden_3_layer['weight']), hidden_3_layer['bias'])
l3 = tf.nn.relu(l3)
l4 = tf.add(tf.matmul(l3,hidden_4_layer['weight']), hidden_4_layer['bias'])
l4 = tf.nn.relu(l4)
l5 = tf.add(tf.matmul(l4,hidden_5_layer['weight']), hidden_5_layer['bias'])
l5 = tf.nn.relu(l5)
output = tf.matmul(l5,output_layer['weight']) + output_layer['bias']
return output
def train_neural_network(x):
prediction = neural_network_model(x)
cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(prediction,y) )
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(cost)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(hm_epochs):
epoch_loss = 0
i=0
while i < len(X_train):
start = i
end = i+batch_size
batch_x = np.array(X_train1[start:end])
batch_y = np.array(y_train1[start:end])
_, c = sess.run([optimizer, cost], feed_dict={x: batch_x, y: batch_y})
epoch_loss += c
i+=batch_size](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-57-320.jpg)

![Page | 59
BREAST CANCER DETECTION USING PROTEOMES
dtypes: float64(5)
memory usage: 3.6 KB
fig, (ax1, ax2) = plt.subplots(1,2, figsize=(15,6))
color_idx = pd.factorize(y.tumor)[0]
cmap = plt.cm.hsv
# Left plot
ax1.scatter(X.iloc[:,0], X.iloc[:,1], c=color_idx, cmap=cmap, alpha=0.5, s=50)
ax1.set_ylabel('Principal Component 2')
# Right plot
ax2.scatter(X.iloc[:,0], X.iloc[:,2], c=color_idx, cmap=cmap, alpha=0.5, s=50)
ax2.set_ylabel('Principal Component 3')
# Custom legend for the classes (y) since we do not create scatter plots per class (which could h
ave their own labels).
handles = []
labels = pd.factorize(y.tumor.unique())
norm = mpl.colors.Normalize(vmin=0.0, vmax=14.0)
for i, v in zip(labels[0], labels[1]):
handles.append(mpl.patches.Patch(color=cmap(norm(i)), label=v, alpha=0.5))
ax2.legend(handles=handles, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
# xlabel for both plots
for ax in fig.axes:
ax.set_xlabel('Principal Component 1')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-59-320.jpg)
![Page | 60
BREAST CANCER DETECTION USING PROTEOMES
pd.DataFrame([X.iloc[:,:5].std(axis=0, ddof=0).as_matrix(),
pca.explained_variance_ratio_[:5],
np.cumsum(pca.explained_variance_ratio_[:5])],
index=['Standard Deviation', 'Proportion of Variance', 'Cumulative Proportion'],
columns=['PC1', 'PC2', 'PC3', 'PC4', 'PC5'])
# Hierarchical Clustering
import seaborn as sns
from sklearn.preprocessing import scale
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from scipy.cluster import hierarchy
%matplotlib inline
plt.style.use('seaborn-white')
df2 = pd.DataFrame(ProteomicsX_pca2)
df2.columns = np.arange(df2.columns.size)
df2.info()](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-60-320.jpg)
![Page | 61
BREAST CANCER DETECTION USING PROTEOMES
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 89 entries, 0 to 88
Data columns (total 5 columns):
0 89 non-null float64
1 89 non-null float64
2 89 non-null float64
3 89 non-null float64
4 89 non-null float64
dtypes: float64(5)
memory usage: 3.6 KB
fig, (ax1, ax2) = plt.subplots(1,2, figsize=(15,6))
color_idx = pd.factorize(y.tumor)[0]
cmap = plt.cm.hsv
# Left plot
ax1.scatter(X.iloc[:,0], X.iloc[:,1], c=color_idx, cmap=cmap, alpha=0.5, s=50)
ax1.set_ylabel('Principal Component 2')
# Right plot
ax2.scatter(X.iloc[:,0], X.iloc[:,2], c=color_idx, cmap=cmap, alpha=0.5, s=50)
ax2.set_ylabel('Principal Component 3')
# Custom legend for the classes (y) since we do not create scatter plots per class (which could h
ave their own labels).
handles = []
labels = pd.factorize(y.tumor.unique())
norm = mpl.colors.Normalize(vmin=0.0, vmax=14.0)
for i, v in zip(labels[0], labels[1]):
handles.append(mpl.patches.Patch(color=cmap(norm(i)), label=v, alpha=0.5))
ax2.legend(handles=handles, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
# xlabel for both plots
for ax in fig.axes:
ax.set_xlabel('Principal Component 1')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-61-320.jpg)
![Page | 62
BREAST CANCER DETECTION USING PROTEOMES
pd.DataFrame([X.iloc[:,:5].std(axis=0, ddof=0).as_matrix(),
pca.explained_variance_ratio_[:5],
np.cumsum(pca.explained_variance_ratio_[:5])],
index=['Standard Deviation', 'Proportion of Variance', 'Cumulative Proportion'],
columns=['PC1', 'PC2', 'PC3', 'PC4', 'PC5'])
X.iloc[:,:10].var(axis=0, ddof=0).plot(kind='bar', rot=0)
plt.ylabel('Variances');](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-62-320.jpg)
![Page | 63
BREAST CANCER DETECTION USING PROTEOMES
fig, (ax1,ax2,ax3) = plt.subplots(1,3, figsize=(20,20))
for linkage, cluster, ax in zip([hierarchy.complete(X), hierarchy.average(X), hierarchy.single(X)],
['c1','c2','c3'],
[ax1,ax2,ax3]):
cluster = hierarchy.dendrogram(linkage, labels=X.index, orientation='right',
color_threshold=0, leaf_font_size=10, ax=ax)
ax1.set_title('Complete Linkage')
ax2.set_title('Average Linkage')
ax3.set_title('Single Linkage');](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-63-320.jpg)
![Page | 64
BREAST CANCER DETECTION USING PROTEOMES
plt.figure(figsize=(10,20))
cut4 = hierarchy.dendrogram(hierarchy.complete(X),
labels=X.index, orientation='right', color_threshold=140, leaf_font_size=10)
plt.vlines(140,0,plt.gca().yaxis.get_data_interval()[1], colors='r', linestyles='dashed');](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-64-320.jpg)
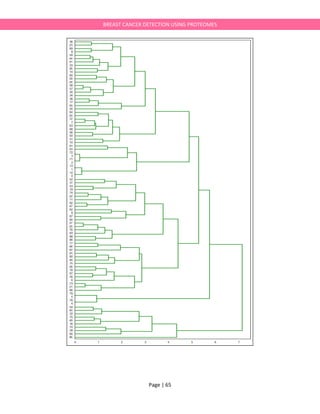
![Page | 66
BREAST CANCER DETECTION USING PROTEOMES
K-Means Clustering
list(ProteomicsXRaw.index)#Plotting the first 3 components
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(1,figsize=(9,6))
ax = fig.gca(projection='3d')
from collections import OrderedDict
TumorCode={'Healthy':'green','T1':'yellow','T2':'orange','T3':'red','T4':'darkviolet'}
IntermedSet=[IDDict[x] for x in list(ProteomicsXRaw.index)]
ColorSet=[TumorCode[x] for x in IntermedSet]
for i,c,ID in zip(range(len(ProteomicsX_pca2)),ColorSet,IntermedSet):
ax.scatter3D(xs=ProteomicsX_pca2[:,0][i],
ys=ProteomicsX_pca2[:,1][i],
zs=ProteomicsX_pca2[:,2][i],
c=c,
label=ID,
s=90,zorder=1)
ax.set_xlabel(str.format('1st Component'+'
'+str(ProteomicsX_pca.explained_variance_ratio_[0])[0:5])+'%')
ax.set_ylabel(str.format('2nd Component'+'
'+str(ProteomicsX_pca.explained_variance_ratio_[1])[0:5])+'%')
ax.set_zlabel(str.format('3rd Component'+'
'+str(ProteomicsX_pca.explained_variance_ratio_[2])[0:5])+'%')
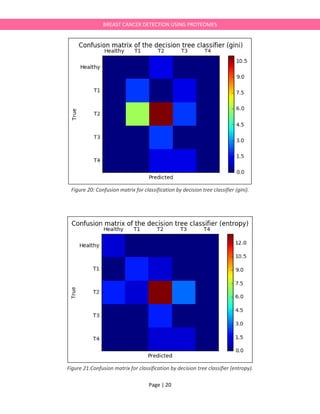
plt.title('PCA of Breast Cancer Proteomics')](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-66-320.jpg)
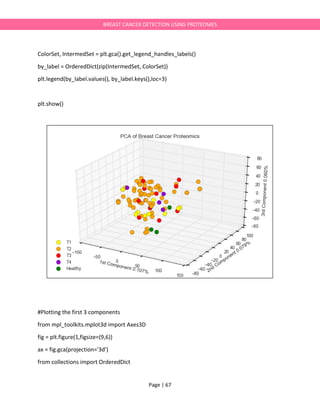
![Page | 68
BREAST CANCER DETECTION USING PROTEOMES
TumorCode={'Healthy':'green','T1':'yellow','T2':'orange','T3':'red','T4':'darkviolet'}
IntermedSet=[IDDict[x] for x in list(ProteomicsXRaw.index)]
ColorSet=[TumorCode[x] for x in IntermedSet]
for i,c,ID in zip(range(len(ProteomicsX_pca2)),ColorSet,IntermedSet):
ax.scatter3D(xs=ProteomicsX_pca2[:,0][i],
ys=ProteomicsX_pca2[:,1][i],
zs=ProteomicsX_pca2[:,2][i],
c=c,
label=ID,
s=90,zorder=1)
ax.set_xlabel(str.format('1st Component'+'
'+str(ProteomicsX_pca.explained_variance_ratio_[0])[0:5])+'%')
ax.set_ylabel(str.format('2nd Component'+'
'+str(ProteomicsX_pca.explained_variance_ratio_[1])[0:5])+'%')
ax.set_zlabel(str.format('3rd Component'+'
'+str(ProteomicsX_pca.explained_variance_ratio_[2])[0:5])+'%')
ax.view_init(azim=30)
plt.title('PCA of Breast Cancer Proteomics')
ColorSet, IntermedSet = plt.gca().get_legend_handles_labels()
by_label = OrderedDict(zip(IntermedSet, ColorSet))
plt.legend(by_label.values(), by_label.keys(),loc=3)
plt.show()](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-68-320.jpg)
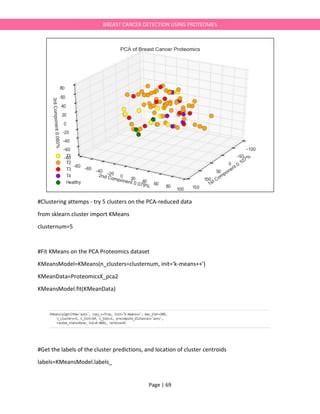
![Page | 70
BREAST CANCER DETECTION USING PROTEOMES
centroids=KMeansModel.cluster_centers_
##############################################################################
#Plot the clusters and the observations with respect to the cluster boundaries
#Some of these commands are adapted from the scikit-learn example for KMeans
#... which is found at http://scikit-
learn.org/stable/auto_examples/cluster/plot_kmeans_digits.html#sphx-glr-auto-examples-
cluster-plot-kmeans-digits-py (thanks!)
##############################################################################
fig = plt.figure(1,figsize=(9,6))
from collections import OrderedDict
#Further reduce to 2 components for the decision boundary plot
TwoCompReduced = PCA(n_components=2).fit_transform(ProteomicsX)
KMeansSub=KMeans(n_clusters=clusternum, init='k-means++')
KMeansSub.fit(TwoCompReduced)
# Step size - adjusted for speed here
h = .05
# Plot the decision boundary. For that, we will assign a color to each
x_min, x_max = TwoCompReduced[:, 0].min() - 1, TwoCompReduced[:, 0].max() + 1
y_min, y_max = TwoCompReduced[:, 1].min() - 1, TwoCompReduced[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Obtain labels for each point in mesh. Use last trained model.
Z = KMeansSub.predict(np.c_[xx.ravel(), yy.ravel()])](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-70-320.jpg)
![Page | 71
BREAST CANCER DETECTION USING PROTEOMES
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure(1)
plt.clf()
plt.imshow(Z, interpolation='nearest',
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
aspect='auto', origin='lower',alpha=0.2)
#Get the colors of the tumor type as used in the PCA above
TumorCode=OrderedDict([('Healthy','green'),('T1','yellow'),('T2','orange'),('T3','red'),('T4','darkvi
olet')])
IntermedSet=[IDDict[x] for x in list(ProteomicsXRaw.index)]
ColorSet=[TumorCode[x] for x in IntermedSet]
for i in range(clusternum):
# select only data observations with cluster label == i
DataSubset = KMeanData[np.where(labels==i)]
#Get the matching list of colors by tumor type filtered by the cluster label
MatchList=[x for x in np.where(labels==i)[0]]
ColorList=[ColorSet[x] for x in MatchList]
#Cluster IDs
ClusterID=np.repeat(i,len(KMeanData[np.where(labels==i)]))
for i,c,ID in zip(range(len(DataSubset)),ColorList,ClusterID):
plt.scatter(x=DataSubset[:,0][i],](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-71-320.jpg)
![Page | 72
BREAST CANCER DETECTION USING PROTEOMES
y=DataSubset[:,1][i],
c=c,
label=ID,s=90)
#Plot positions of centroids
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='x', s=169, linewidths=3,
color='black', zorder=10)
markers = [plt.Line2D([0,0],[0,0],color=color, marker='o', linestyle='',markersize=16) for color in
TumorCode.values()]
plt.legend(markers, TumorCode.keys(), numpoints=1,fontsize=16)
plt.title('K-Means of Breast Cancer Proteomics',size=20)
plt.show()](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-72-320.jpg)

![Page | 74
BREAST CANCER DETECTION USING PROTEOMES
photo = ImageTk.PhotoImage(resized)
label = Label(root, image=photo)
label.image = photo # keep a reference!
label.grid(row = 20 , columnspan=4, sticky = W, padx = 10, pady = 10)
mb_var = StringVar()
#mb_var.set("Model Selection")
mb = OptionMenu(root, mb_var, ())
mb.configure(width=20)
mb.grid(row = 1,column = 1)
def reset_option_menu(options, index=None):
menu = mb["menu"]
menu.delete(0, "end")
for string in options:
menu.add_command(label=string, command=lambda value=string:mb_var.set(value))
if index is not None:
mb_var.set(options[index])
def a():
reset_option_menu(["Logistic Regression","KNN","Random Forest","Decision Tree-
Gini","Decision Tree-Entropy","SVM","Neural Network","Gradient Boosting"], 0)
def b():
reset_option_menu(["K-Clustering", "Hierarchial Clustering"], 0)](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-74-320.jpg)
![Page | 75
BREAST CANCER DETECTION USING PROTEOMES
def default():
reset_option_menu([""], 0)
def d():
var = "The Selected Model is " + mb_var.get()
var2.set(var)
def e():
var = mb_var.get()
if var == "SVM":
image1 = Image.open("SVM_Results.png")
resized =image1.resize((700, 500),Image.ANTIALIAS)
photo1 = ImageTk.PhotoImage(resized)
label.configure(image = photo1)
label.image = photo1
elif var == "KNN":
image2 = Image.open("KNN_Results.png")
resized =image2.resize((700, 500),Image.ANTIALIAS)
photo2 = ImageTk.PhotoImage(resized)
label.configure(image = photo2)
label.image = photo2](https://image.slidesharecdn.com/breastcancerdetectionie594project-170525015518/85/Breast-cancerdetection-IE594-Project-Report-75-320.jpg)




This report presents a comprehensive analysis of breast cancer detection using proteomic data, focusing on classification and clustering algorithms to categorize different breast cancer types. It utilizes a dataset of 105 tumor samples analyzed through various machine learning techniques, including support vector machines, logistic regression, and k-nearest neighbors. The study highlights the importance of data preprocessing and visualization steps in achieving accurate classification results, ultimately demonstrating an accuracy of 77.78% for the best-performing model.