목차
• Spring Data
• Maven Artifacts
• NoSQL
• HADOOP
• Map Reduce
• Hadoop 구성
• Spring + Hadoop
• Start
• DBaaS
12년 5월 8일 화요일
3.
1. Spring Data Relation dB
- JPA
- JDBC Extensions
Big Data
- Apache Hadoop
Data-grid
- GemFire
Key value Stroes
- Redis
- Riak
Document Stores
- MongoDB
Graph DB
- Neo4j
Column Stores
- HBase
Blob -stores
- Blob
Common infrastrusture
- Commons
- Griails Mapping
12년 5월 8일 화요일
3. NoSQL
소셜 웹 시대로 접어들면서 DB read와
Update가 많이 일어남.
관계형 DB로는 한계가 있음
카산드라와 hadoop 기반의 HBase 가 인기
있다.
분산 스토리지와 RESTful API를 통한 데이
터 접근은 복잡성으로 인한 개발비용 줄
임
아무때나 사용하는 것 보다는 Update가
빈번히 일어날때 효과적
RDB에 익숙한 사람은 MongoDB가 M/R 작
업이 익숙한 사람은 Hadoop
scalability가 걱정인 사람은 카산드라 사
용이 좋음
참고 : Channy’s Blog(http://blog.creation.net/459)
12년 5월 8일 화요일
6.
4. HADOOP
분산처리
구글의 맵 리듀스
야후의 더그 거팅 제작
병렬처리 방식
12년 5월 8일 화요일
7.
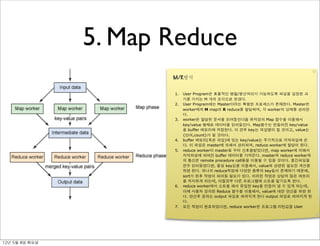
5. Map Reduce
M/R방식
1. User Program은 효율적인 병렬/분산처리가 가능하도록 파일을 일정한 크
기를 가지는 M 개의 조각으로 쪼갠다.
2. User Program에는 Master이라는 특별한 프로세스가 존재한다. Master은
worker에게 M map과 R reduce를 할당하며, 각 worker의 상태를 관리한
다.
3. worker은 할당된 문서를 읽어들인다음 유저정의 Map 함수를 이용해서
key/value 형태로 데이터를 읽어들인다. Map함수는 만들어진 key/value
를 buffer 메모리에 저장한다. 이 경우 key는 파일명이 될 것이고, value는
{단어,count}가 될 것이다.
4. buffer 메모리(혹은 파일)에 있는 key/value는 주기적으로 지역파일에 쓴
다. 이 파일은 master에 의해서 관리되며, reduce worker에 할당이 된다.
5. reduce worker이 master로 부터 신호를받았다면, map worker에 의해서
지역파일에 씌여진 buffer 데이터를 가져온다. master와 reduce worker와
의 통신은 remote procedure call등을 이용할 수 있을 것이다. 중간파일을
전부 읽어들였다면, 동일 key값을 이용해서, value와 관련된 필요한 계산을
하면 된다. 하나의 reduce작업에 다양한 종류의 key들이 존재하기 때문에,
sort가 된후 작업이 되어질 필요가 있다. 이러한 작업은 상당히 많은 메모리
를 차지하게 되는데, 이럴경우 다른 프로그램에 소트를 맡기도록 한다.
6. reduce worker에서 소트를 해서 유일한 key를 만들어 낼 수 있게 되는데,
이때 사용자 정의된 Reduce 함수를 이용해서, value에 대한 연산을 하면 된
다. 연산후 결과는 output 파일로 씌여지게 된다 output 파일로 씌여지게 된
다.
7. 모든 작업이 완료되었다면, reduce worker은 프로그램 리턴값을 User
12년 5월 8일 화요일






























![[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























![[246] foursquare데이터라이프사이클 설현준](https://cdn.slidesharecdn.com/ss_thumbnails/246foursquare-161025031706-thumbnail.jpg?width=640&height=640&fit=bounds)

![[H3 2012] Cloud Database Service - Hulahoop를 소개합니다.](https://cdn.slidesharecdn.com/ss_thumbnails/c1-hulahoop-121105214317-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















