데이터의 규모에 맞춘단순한 정의
기존 데이터 관리 도구로는 감당할 수 없을 정도 규모의 데이터
13년 10월 21일 월요일
5.
TDWI에서 정의한
BIG Data의3대요소
• Volume
✓ 수십 TB or 수십 PB 이상
✓ 기존의 솔루션으로 처리하기 힘든 정도의 크기
• Velocity
✓ 대용량의 데이터에 대해 서비스의 요구사항에 맞게
실시간/배치 처리 가능
• Variety
✓ 정형, 반정형 뿐만 아니라 비정형 데이터를 핸들링
이 중 2가지 이상을 만족하면 Big data
이미지 출처: What is Big Data?, Datameer, <http://www.datameer.com/product/big-data.html>
13년 10월 21일 월요일
대용량 파일을 안전하게저장하고, 처리하기 위한
하둡 분산 파일 시스템
(Hadoop Distributed File System)
13년 10월 21일 월요일
22.
HDFS의 설계의 특징
•대용량 파일을 주로 저장
✓ FAT32: 4G, NTFS: 4~64G, EXT3: 2TB ~ 64TB
• 랜덤 접근 보다는 스트리밍 접근 방식을 선호
✓ 순차적인 파일 연산
• 고가의 장비보다는 여러대의 저가의 장비에서 실행됨
✓ 장비의 고장이 일반적인 상황으로 고려되어야 함
• 한번 쓰여진 파일은 내용이 변경되기 보다는 추가됨
✓ 제공되는 파일 연산: create/delete/append/modify(x)
13년 10월 21일 월요일
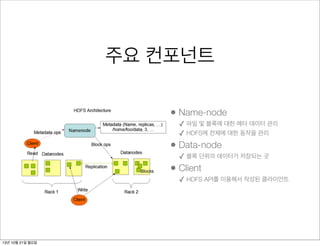
주요 컨포넌트
• Name-node
✓파일 및 블록에 대한 메타 데이터 관리
✓ HDFS에 전체에 대한 동작을 관리
• Data-node
✓ 블록 단위의 데이터가 저장되는 곳
• Client
✓ HDFS API를 이용해서 작성된 클라이언트
13년 10월 21일 월요일
25.
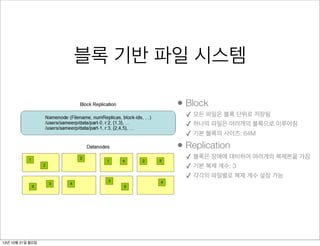
블록 기반 파일시스템
• Block
✓ 모든 파일은 블록 단위로 저장됨
✓ 하나의 파일은 여러개의 블록으로 이루어짐
✓ 기본 블록의 사이즈: 64M
• Replication
✓ 블록은 장애에 대비하여 여러개의 복제본을 가짐
✓ 기본 복제 계수: 3
✓ 각각의 파일별로 복제 계수 설정 가능
13년 10월 21일 월요일
26.
Metadata 관리
• 모든Metadata는 Name-node의 메모리에 저장
• Name-node는 3가지 주요 데이터를 저장
✓ 파일에 대한 네임스페이스 정보
✓ 파일과 블록의 맵핑 정보
✓ 각 블록에 대한 데이터 노드 위치 정보
• 파일에 대한 네임스페이스 정보와 파일과 블록의 맵핑 정보는
Name-node에서 영구적으로 관리
✓ 파일 시스템에 대한 이미지 및 변경 로그(FSImage, Edit log)
• 각 블록에 대한 위치 정보는 Name-node에서 임시적으로 관리
✓ 데이터 노드 시작시 Name-node로 전송, Name-node는 해당 정보를 메모리에 유지
13년 10월 21일 월요일
27.
FSImage & EditLog
•Name-node는 FSImage와 EditLog를 사용해서 파일 시스템 이미지를 구성
✓ EditLog가 클수록 파일 시스템 갱신시 시간이 오래 걸림.
✓ 이러한 이슈를 해결하기 위하여, 보조 네임노드는 주기적으로 파일 시스템 이미지를 갱신
Secondary Name-node
Name-node
Memory FileSystem
Storage
Edit Log
/
저장
/user
A
B
/etc
C
/var
D
E
병합
Edit Log
1. Add File
2. Delete File
3. Append File
:
다운
로드
:
+
FS
Image
FS
Image
전송
13년 10월 21일 월요일
New
FS Image
28.
FSDataOutputStream
DFSOutput
Flow - WriteOperation
Stream
DFSOutputStream
Data
Streamer
DataStreamer
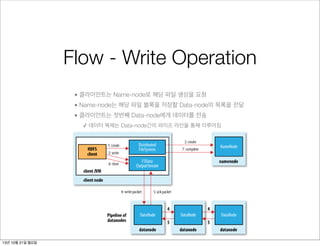
• 클라이언트는 Name-node로 해당 파일 생성을 요청
• Name-node는 해당 파일 블록을 저장할 Data-node의 목록을 전달
• 클라이언트는 첫번째 Data-node에게 데이터를 전송
✓ 데이터 복제는 Data-node간의 파이프 라인을 통해 이루어짐
13년 10월 21일 월요일
29.
Flow - ReadOperation
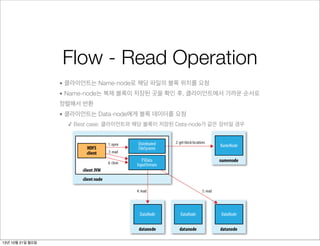
• 클라이언트는 Name-node로 해당 파일의 블록 위치를 요청
• Name-node는 복제 블록이 저장된 곳을 확인 후, 클라이언트에서 가까운 순서로
정렬해서 반환
• 클라이언트는 Data-node에게 블록 데이터를 요청
✓ Best case: 클라이언트와 해당 블록이 저장된 Data-node가 같은 장비일 경우
13년 10월 21일 월요일
30.
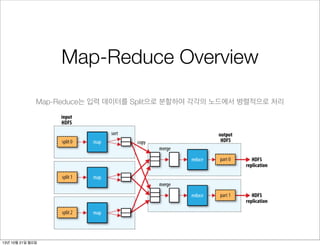
일반적인 하드웨어로 구성된클러스터 상에서
많은 양의 데이터를 병렬로 처리하는 어플리케이션을
쉽게 작성할 수 있도록 하는 소프트웨어 프레임워크
13년 10월 21일 월요일
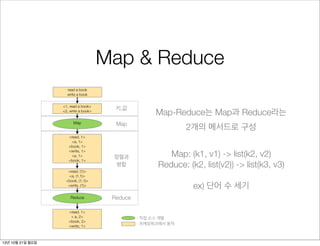
Map & Reduce
reada book
write a book
<1, read a book>
<2, write a book>
키,값
Map-Reduce는 Map과 Reduce라는
Map
Map
2개의 메서드로 구성
<read, 1>
<a, 1>
<book, 1>
<write, 1>
<a, 1>
<book, 1>
정렬과
병합
<read, (1)>
<a, (1,1)>
<book, (1,1)>
<write, (1)>
Reduce
<read, 1>
< a, 2>
<book, 2>
<write, 1>
13년 10월 21일 월요일
Map: (k1, v1) -> list(k2, v2)
Reduce: (k2, list(v2)) -> list(k3, v3)
ex) 단어 수 세기
Reduce
: 직접 소스 개발
: 프레임워크에서 동작
33.
Example
WordCount-Mapper
Map: (k1, v1)-> list(k2, v2)
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
}
13년 10월 21일 월요일
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
34.
Example
WordCount-Reducer
Reduce: (k2, list(v2))-> list(k3, v3)
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
}
13년 10월 21일 월요일
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
35.
Example
WordCount-Driver
main함수가 있는 구동Class
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
13년 10월 21일 월요일
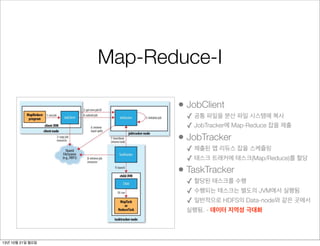
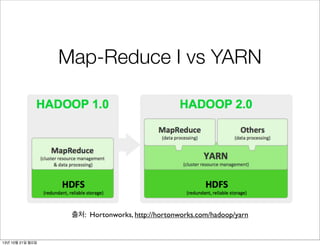
Map-Reduce-I
• JobClient
✓ 공통파일을 분산 파일 시스템에 복사
✓ JobTracker에 Map-Reduce 잡을 제출
• JobTracker
✓ 제출된 맵 리듀스 잡을 스케쥴링
✓ 태스크 트래커에 태스크(Map/Reduce)를 할당
• TaskTracker
✓ 할당된 태스크를 수행
✓ 수행되는 태스크는 별도의 JVM에서 실행됨
✓ 일반적으로 HDFS의 Data-node와 같은 곳에서
실행됨. - 데이터 지역성 극대화
13년 10월 21일 월요일
JobClient submitJob()
38.
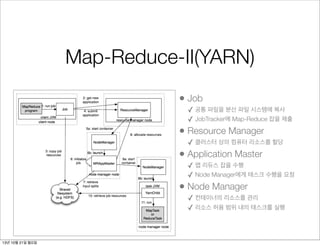
Map-Reduce-II(YARN)
• Job
✓ 공통파일을 분산 파일 시스템에 복사
✓ JobTracker에 Map-Reduce 잡을 제출
• Resource Manager
✓ 클러스터 상의 컴퓨터 리소스를 할당
• Application Master
✓ 맵 리듀스 잡을 수행
✓ Node Manager에게 태스크 수행을 요청
• Node Manager
✓ 컨테이너의 리소스를 관리
✓ 리소스 허용 범위 내의 태스크를 실행
13년 10월 21일 월요일
39.
Map-Reduce-II(YARN)
• Job
✓ 공통파일을 분산 파일 시스템에 복사
✓ JobTracker에 Map-Reduce 잡을 제출
• Resource Manager
✓ 클러스터 상의 컴퓨터 리소스를 할당
• Application Master
✓ 맵 리듀스 잡을 수행
✓ Node Manager에게 태스크 수행을 요청
• Node Manager
✓ 컨테이너의 리소스를 관리
✓ 리소스 허용 범위 내의 태스크를 실행
확장성 문제를 해결하기 위해
잡트래커의 책임을 분리
13년 10월 21일 월요일
40.
이전 버전과의 차이(2/2)
Map-Reduce I vs YARN
출처: Hortonworks, http://hortonworks.com/hadoop/yarn
13년 10월 21일 월요일
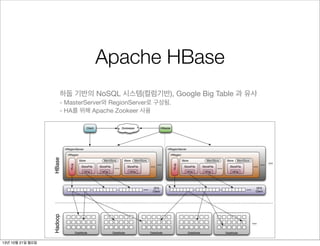
Apache HBase
하둡 기반의NoSQL 시스템(컬럼기반), Google Big Table 과 유사
- MasterServer와 RegionServer로 구성됨.
- HA를 위해 Apache Zookeer 사용
13년 10월 21일 월요일
43.
Apache PIG
• 대규모의데이터를 쉽게 분석할 수 있도록 스크립트
수준의 언어를 제공하는 분석 플랫폼
✓ Hadoop 상에서 구동시 스크립트가 내부적으로 맵리듀스
잡으로 수행 됨
<WordCount Example>
A = load './input.txt';
B = foreach A generate flatten(TOKENIZE((chararray)$0)) as word;
C = group B by word;
D = foreach C generate COUNT(B), group;
store D into './wordcount';
13년 10월 21일 월요일
44.
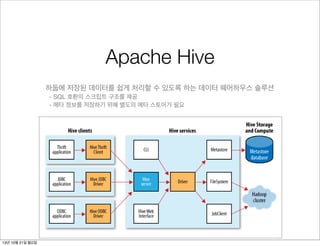
Apache Hive
Hive clients
하둡에저장된 데이터를 쉽게 처리할 수 있도록 하는 데이터 웨어하우스 솔루션
hive --service hiveserver
- SQL 호환의 스크립트 구조를 제공
- 메타 정보를 저장하기 위해 별도의 메타 스토어가 필요
13년 10월 21일 월요일
45.
Apache Sqoop
하둡과 RDBMS사이에서 데이터를 전송하기 위한 Tool
Import
Export
이미지 출처: siliconweek, <http://www.siliconweek.es/noticias/apache-sqoop-se-convierte-en-proyecto-prioritario-para-big-data-21558>
13년 10월 21일 월요일
46.
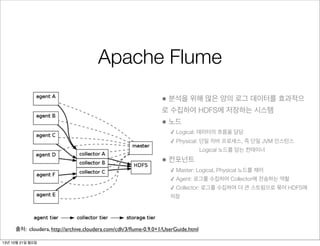
Apache Flume
• 분석을위해 많은 양의 로그 데이터를 효과적으
로 수집하여 HDFS에 저장하는 시스템
• 노드
✓ Logical: 데이터의 흐름을 담당
✓ Physical: 단일 자바 프로세스, 즉 단일 JVM 인스턴스
Logical 노드를 담는 컨테이너
• 컨포넌트
✓ Master: Logical, Physical 노드를 제어
✓ Agent: 로그를 수집하여 Collector에 전송하는 역할
✓ Collector: 로그를 수집하여 더 큰 스트림으로 묶어 HDFS에
저장
출처: cloudera, http://archive.cloudera.com/cdh/3/flume-0.9.0+1/UserGuide.html
13년 10월 21일 월요일
47.
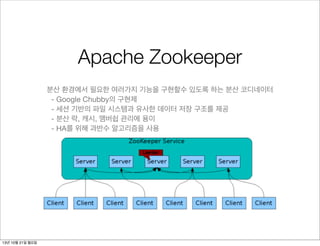
Apache Zookeeper
분산 환경에서필요한 여러가지 기능을 구현할수 있도록 하는 분산 코디네이터
- Google Chubby의 구현제
- 세션 기반의 파일 시스템과 유사한 데이터 저장 구조를 제공
- 분산 락, 캐시, 맴버쉽 관리에 용이
- HA를 위해 과반수 알고리즘을 사용
13년 10월 21일 월요일
48.
References
• 정재화. 시작하세요!하둡 프로그래밍. 경기도 파주: 위키북스, 2012
• 위키피디아. 빅데이터. http://ko.wikipedia.org/wiki/%EB%B9%85_%EB%8D%B0%EC%9D
%B4%ED%84%B0 .
• Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google le system. In 19th
Symposium on Operating Systems Principles, pages 2943, Lake George, New York, 2003.
• 아파치. 하둡. http://hadoop.apache.org/
• Hadoop YARN “A next-generation framework for Hadoop data processing”, Hortonworks,
http://hortonworks.com/hadoop/yarn
• Flume User Guide, Cloudera, http://archive.cloudera.com/cdh/3/flume-0.9.0+1/
UserGuide.html
13년 10월 21일 월요일























![Example
WordCount-Driver
main함수가 있는 구동 Class
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
13년 10월 21일 월요일](https://image.slidesharecdn.com/hadoopoverview-131020210254-phpapp01/85/Hadoop-overview-35-320.jpg)



































































![[246] foursquare데이터라이프사이클 설현준](https://cdn.slidesharecdn.com/ss_thumbnails/246foursquare-161025031706-thumbnail.jpg?width=640&height=640&fit=bounds)























