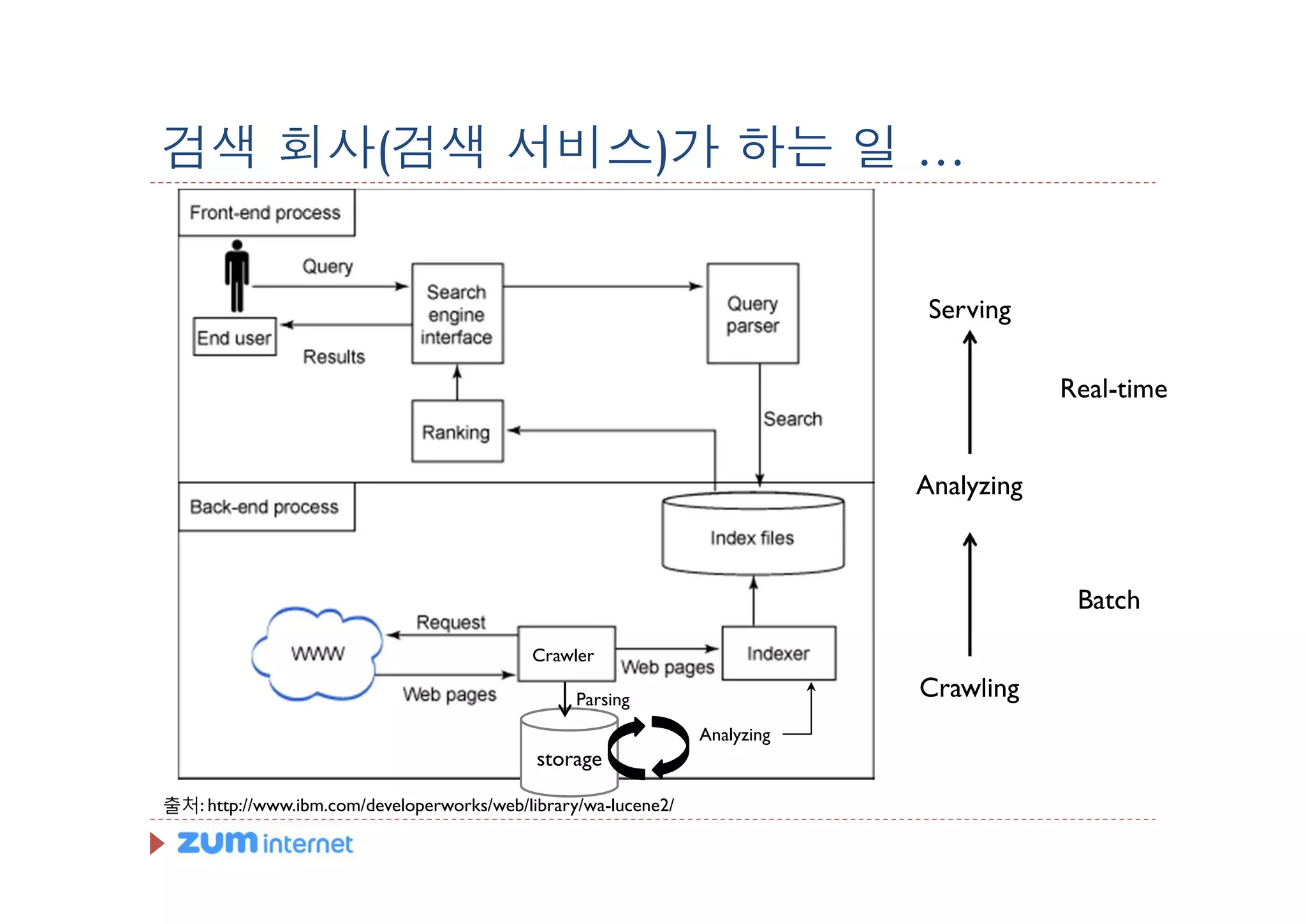
검색 회사(검색 서비스)가하는 일 …
Serving
Real-time
Analyzing
Batch
Crawler
Parsing Crawling
Analyzing
storage
출처: http://www.ibm.com/developerworks/web/library/wa-lucene2/
5.
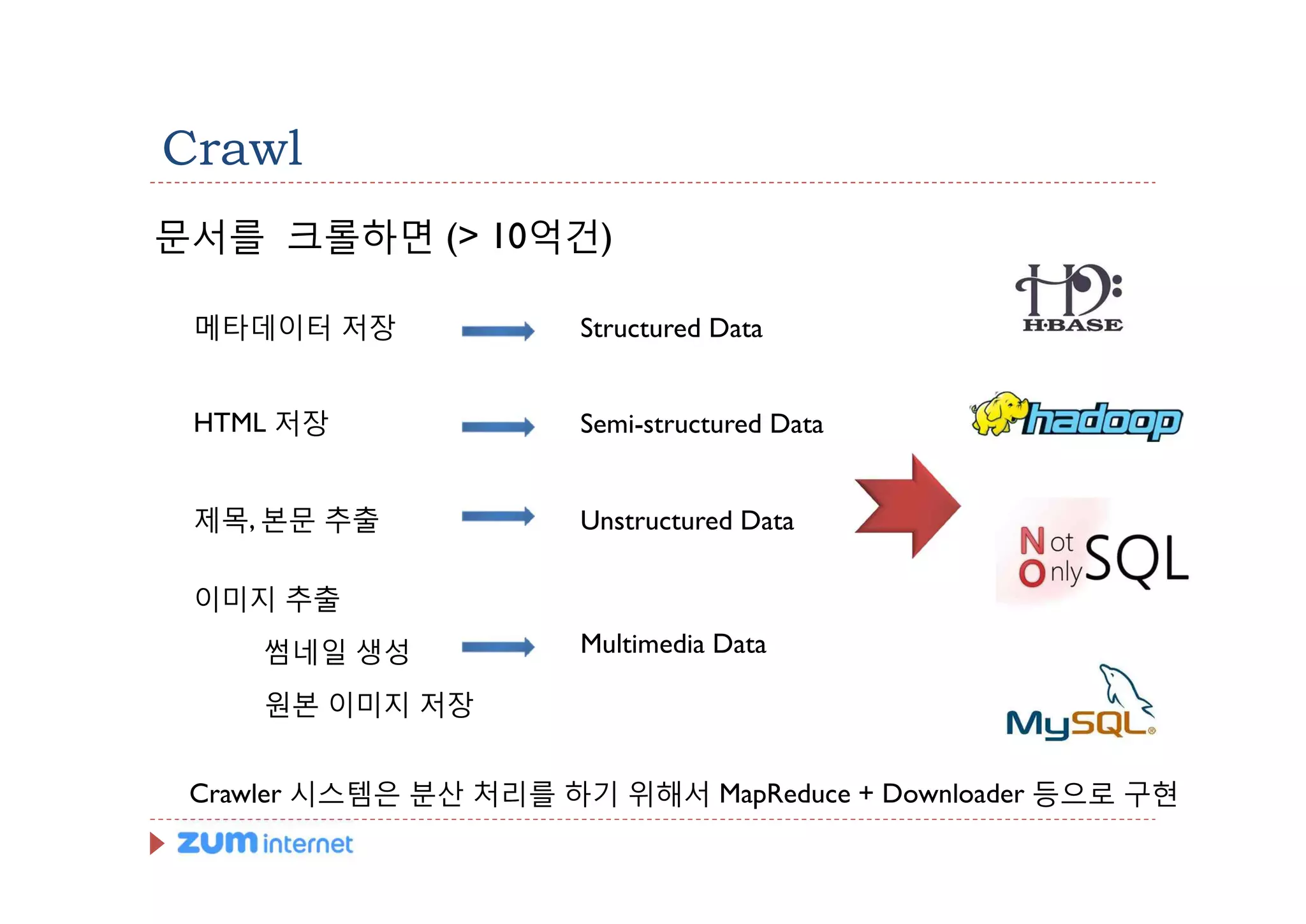
Crawl
문서를 크롤하면 (>10억건)
메타데이터 저장 Structured Data
HTML 저장 Semi-structured Data
제목, 본문 추출 Unstructured Data
이미지 추출
썸네일 생성 Multimedia Data
원본 이미지 저장
Crawler 시스템은 분산 처리를 하기 위해서 MapReduce + Downloader 등으로 구현
6.
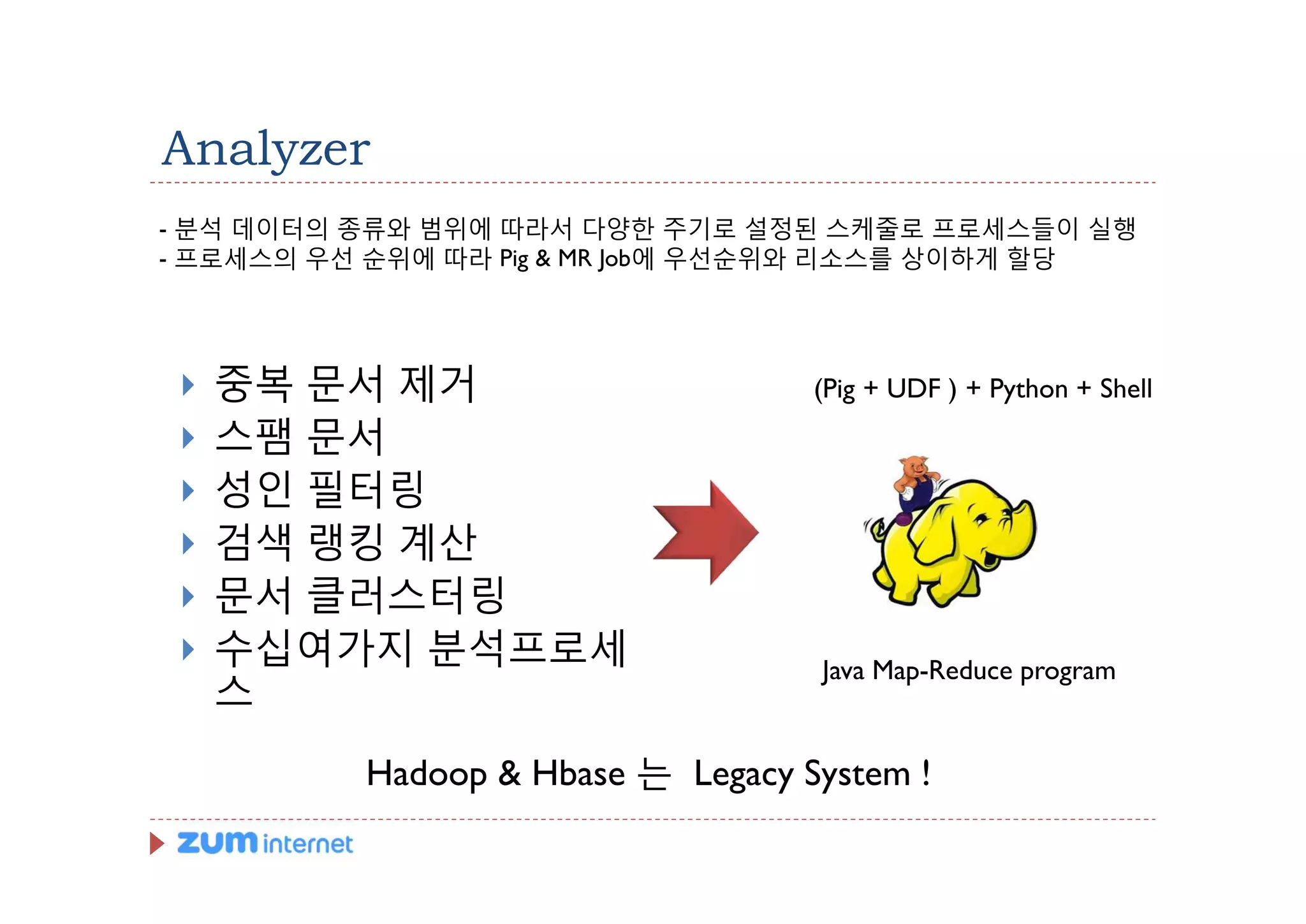
Analyzer
- 분석 데이터의종류와 범위에 따라서 다양한 주기로 설정된 스케줄로 프로세스들이 실행
- 프로세스의 우선 순위에 따라 Pig & MR Job에 우선순위와 리소스를 상이하게 할당
} 중복 문서 제거 (Pig + UDF ) + Python + Shell
} 스팸 문서
} 성인 필터링
} 검색 랭킹 계산
} 문서 클러스터링
} 수십여가지 분석프로세 Java Map-Reduce program
스
Hadoop & Hbase 는 Legacy System !
7.
Service
} Daily 수천만 PV 이상을 처리하기 위해서 …
LVS
Web & Application & DB Clustering 필수
Tomcat
각 Layer 별로 Caching System 적용
Squid
Memcached
인덱싱 & 검색 처리
수십/수백대로 구성된 서버팜
시스템 장애 감지와 통합 모니터링 시스템 역시 필수
100% Linux Server
오픈 소스 및 자체 개발 시스템을 통합해서 활용
장애 대응을 위한 HA 구성
8.
그 밖에 오픈소스들
서비스와 데이터 요구사항에 맞게 코어가 되는
검색엔진, 미디어 서버, KeyValue 시스템등을 자체 개발
9.
ZUM Data Platform
} 로그 수집 체계
} 로그 포맷 표준화
} 중앙 데이터 저장소 구축
} 로그 데이터 수집 프레임워크 개발 (Flume-ng, Fluentd)
} Access log
} ZUM service log
} Application log
} 분석시스템 개발
} Hive 가 메인 도구
} Pig 는 Hive Table 을 생성하는 전처리(ETL) 용 스크립트
} Job Scheduler
10.
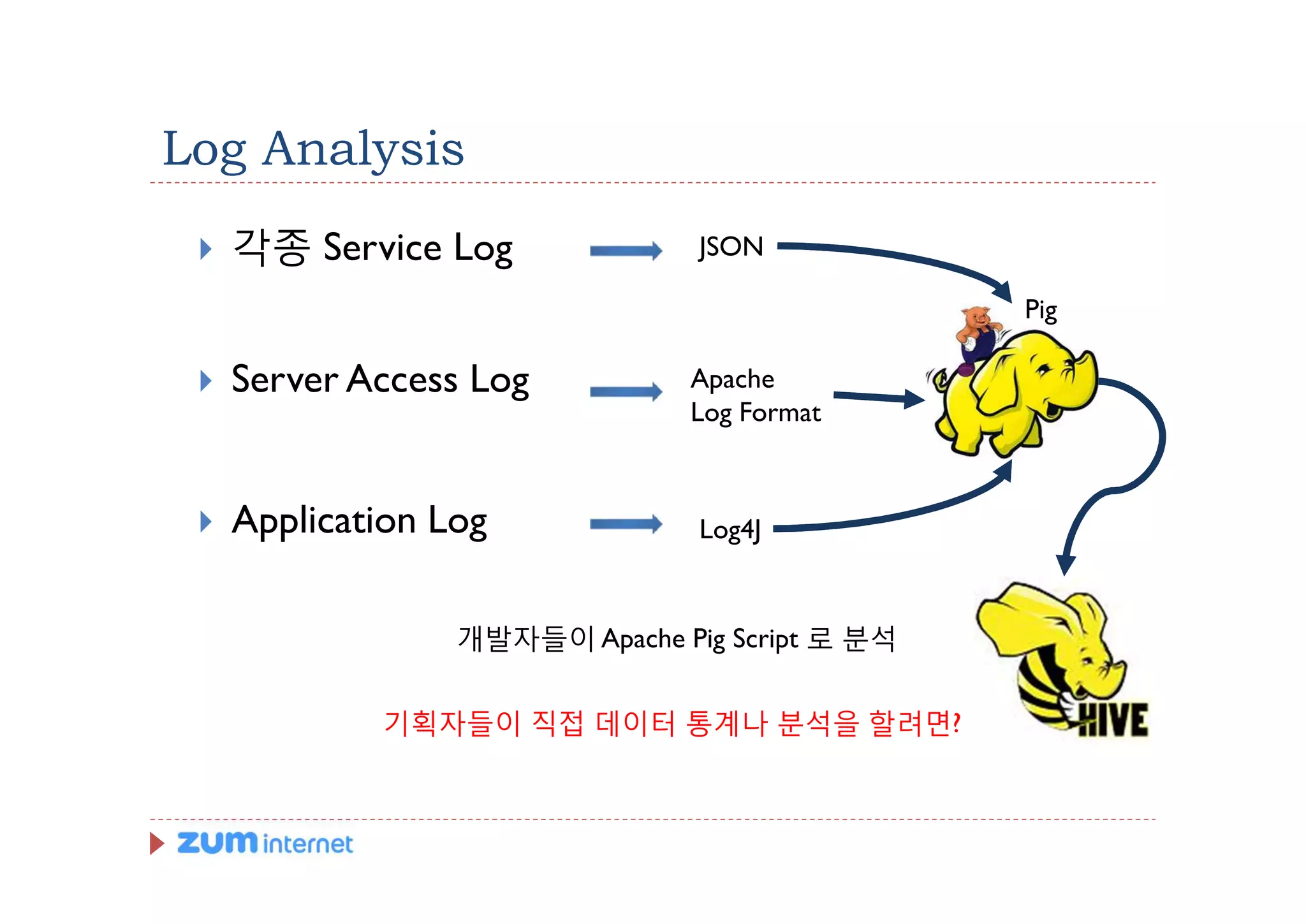
Log Analysis
} 각종 Service Log JSON
Pig
} Server Access Log Apache
Log Format
} Application Log Log4J
개발자들이 Apache Pig Script 로 분석
기획자들이 직접 데이터 통계나 분석을 할려면?
11.
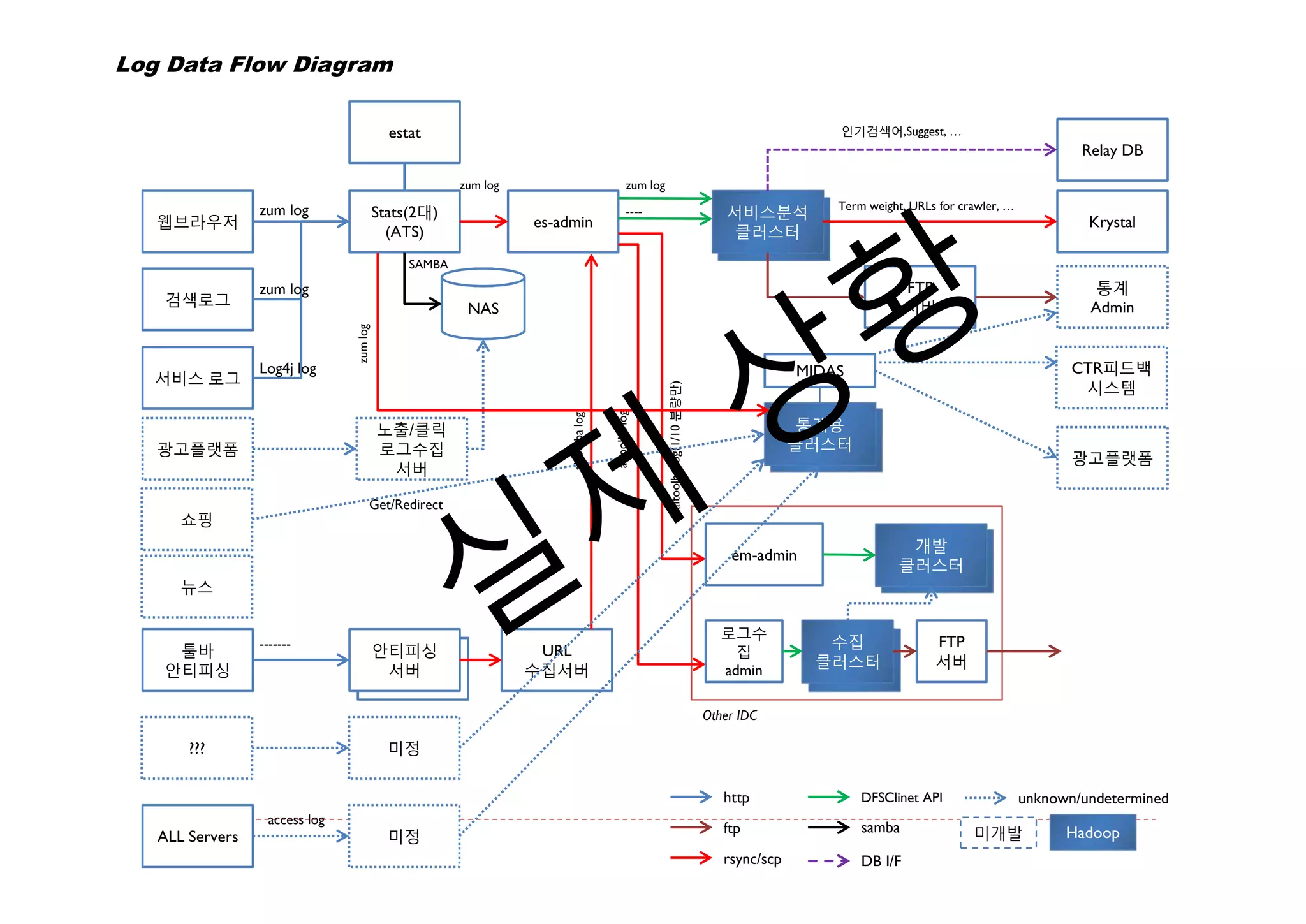
Log Data FlowDiagram
estat 인기검색어,Suggest, …
Relay DB
zum log zum log
zum log Term weight, URLs for crawler, …
Stats(2대) ---- 서비스분석
웹브라우저 es-admin ES-LOG Krystal
(ATS) 클러스터
SAMBA
zum log FTP 통계
검색로그 서버 Admin
NAS
zum log
Log4j log MIDAS CTR피드백
서비스 로그
시스템
altoolba log(1/10 분량만)
altoolba log
altoolba log
노출/클릭 통계용
ES-LOG
클러스터
광고플랫폼 로그수집
광고플랫폼
서버
Get/Redirect
쇼핑
개발
em-admin ES-LOG
클러스터
뉴스
로그수
------- 수집 FTP
툴바 안티피싱 URL 집 DAUM용
안티피싱 클러스터 서버
안티피싱 서버 수집서버 admin 클러스터
서버
Other IDC
??? 미정
http DFSClinet API unknown/undetermined
access log
ftp samba 미개발 Hadoop
ALL Servers 미정
rsync/scp DB I/F
12.
통계 지표 관리
} 고정 지표
} 상시 분석해서 결과를 파악해야 하는 지표
} 공통 지표 정의
} 서비스별 지표 정의 자동화의 대상
} 배치성 지표
} 실시간성 지표
} 유동 지표
} 서비스별로 필요한 경우에 따라서 파악할 지표 Ad-hoc 업무
} 중요도에 따라 고정지표로 전환
데이터 분석 업무가 기존 개발자에서
기획자, 데이터 분석가의 손에서 다루어질 수 있도록
13.
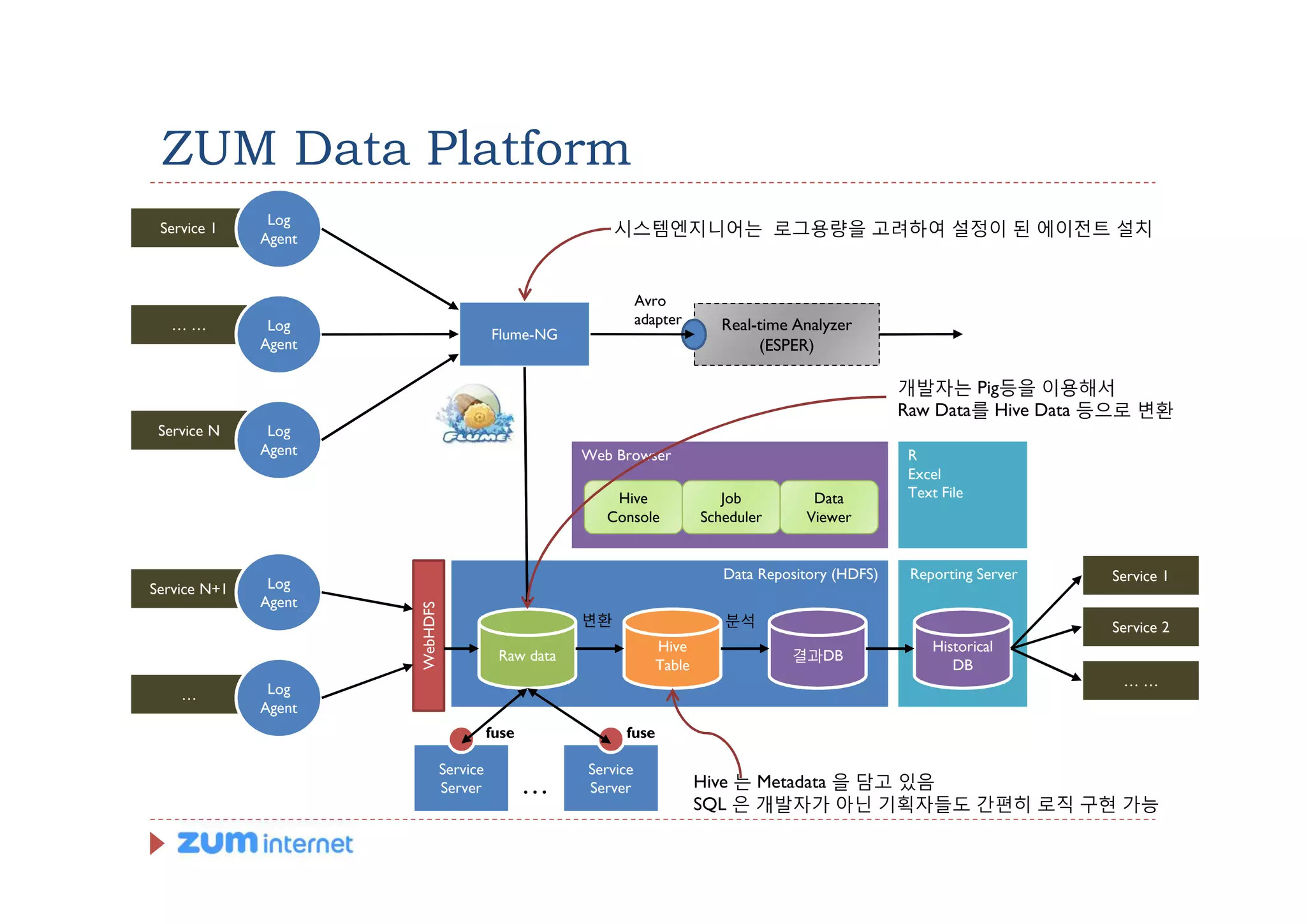
ZUM Data Platform
Log
Service 1
Agent
시스템엔지니어는 로그용량을 고려하여 설정이 된 에이전트 설치
Avro
…… Log adapter Real-time Analyzer
Flume-NG
Agent (ESPER)
개발자는 Pig등을 이용해서
Raw Data를 Hive Data 등으로 변환
Service N Log
Agent Web Browser R
Excel
Hive Job Data Text File
Console Scheduler Viewer
Data Repository (HDFS) Reporting Server Service 1
Service N+1 Log
Agent
WebHDFS
변환 분석 Service 2
Hive Historical
Raw data 결과DB
Table DB
……
… Log
Agent
fuse fuse
Service Service
Server … Server Hive 는 Metadata 을 담고 있음
SQL 은 개발자가 아닌 기획자들도 간편히 로직 구현 가능
14.
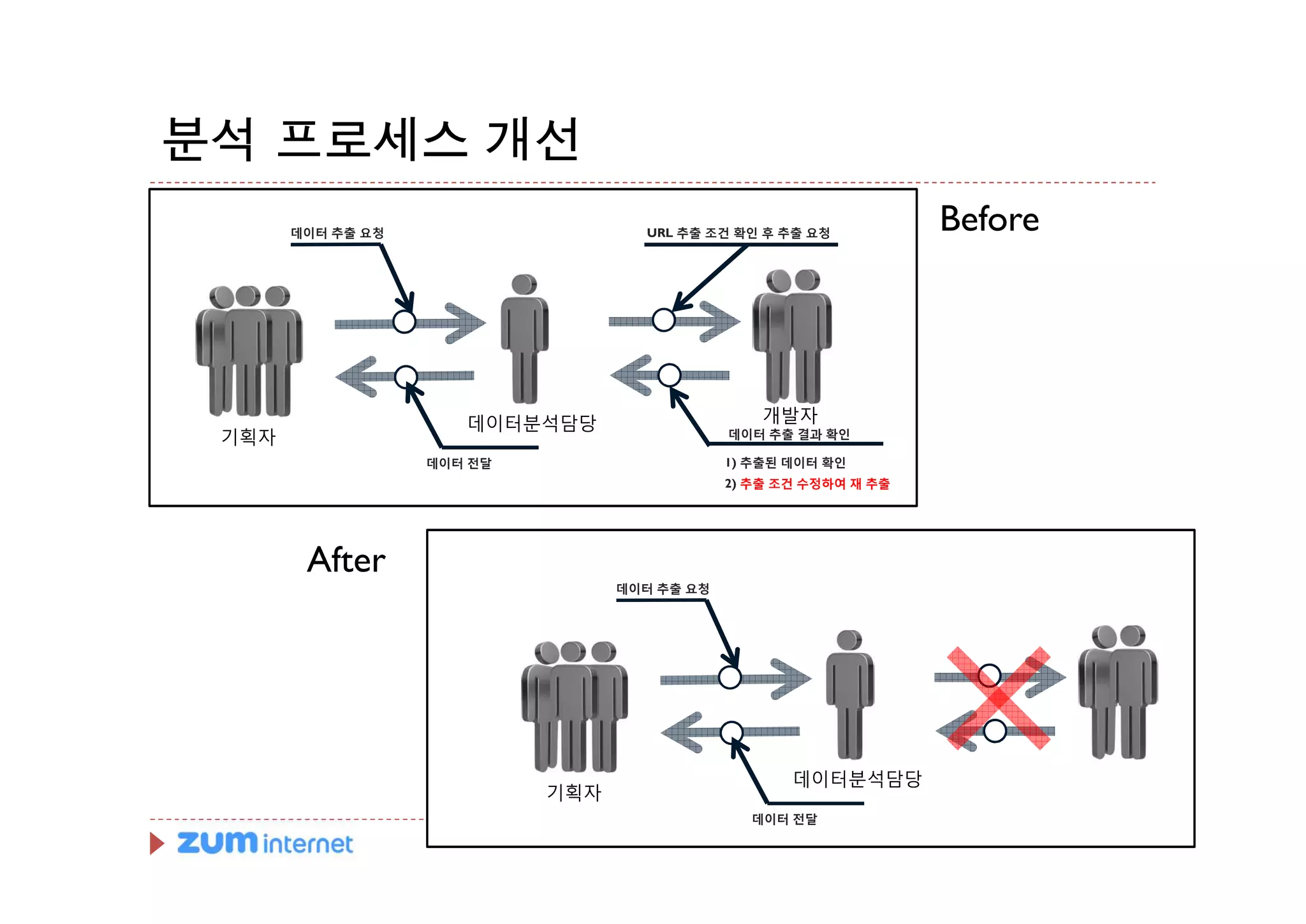
분석 프로세스 개선
데이터 추출 요청 URL 추출 조건 확인 후 추출 요청
Before
데이터분석담당 개발자
기획자 데이터 추출 결과 확인
데이터 전달 1) 추출된 데이터 확인
2) 추출 조건 수정하여 재 추출
After
데이터 추출 요청
데이터분석담당
기획자
데이터 전달
15.
마지막으로 요즘 드는생각 …
Apaceh Hadoop / HBase 가 이미 Legacy System 되어가고 있고
결국 점점 복잡해지고, 무거워지고, 이해하기 힘들어지고 …
다른 이가 만든 기술에 대한 의존은 여전하고
때론 한계에 부딛히기도 하다
Don’t reinvent the wheel? Core 에 대한 깊은 이해 없이
대충 이해하고 응용 어플리케이션 / 서비스 만
들기도 바쁘다
그래서?
직접 만들어 볼 필요도 있다!!!



































![[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[우리가 데이터를 쓰는 법] 모바일 게임 로그 데이터 분석 이야기 - 엔터메이트 공신배 팀장](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=640&height=640&fit=bounds)





![[H3 2012] 로그속 사용자 발자국 들여다보기](https://cdn.slidesharecdn.com/ss_thumbnails/b3-1030-121105213433-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




