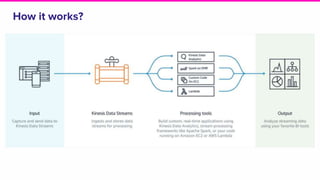
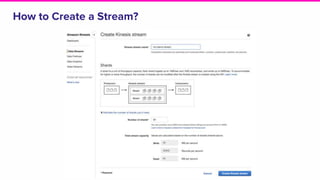
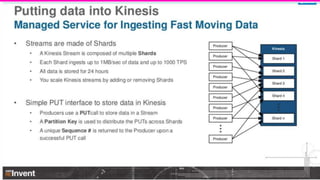
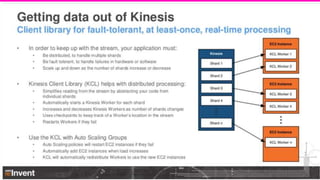
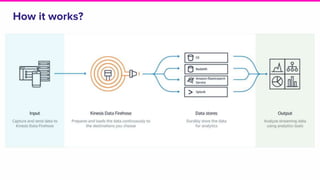
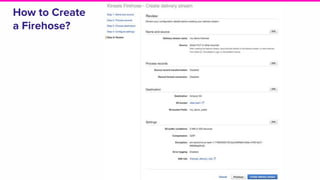
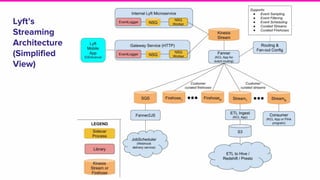
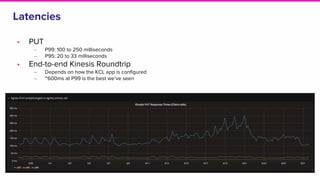
The document provides an overview of Lyft's use of Kinesis for event streaming, detailing its architecture and capabilities including real-time data ingestion and processing. It highlights use cases, strengths and weaknesses of Kinesis, key concepts, best practices for implementation, and the challenges faced by Lyft. Lastly, it suggests that Kinesis is suitable for scenarios requiring best-effort durability and rapid deployment without managing Kafka operations.