Download as PDF, PPTX





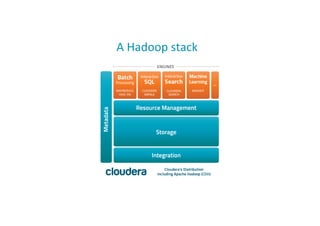











![A
peek
at
the
Avro
schema
$ hive -e "DESCRIBE EXTENDED events"!
...!
{!
"type" : "record",!
"name" : "Event",!
"namespace" : "com.example",!
"fields" : [!
{ "name" : "id", "type" : "long" },!
{ "name" : "timestamp", "type" : "long" },!
{ "name" : "source", "type" : "string" }!
]!
}!
20](https://image.slidesharecdn.com/buildinghadoopdataapplicationswithkite-140625073911-phpapp02/85/Building-Hadoop-Data-Applications-with-Kite-20-320.jpg)




















![Applica;ons
• [Batch]
Analyze
an
archive
of
songs1
• [Interac;ve
SQL]
Ad
hoc
queries
on
recommenda;ons
from
social
media
applica;ons2
• [Search]
Searching
email
traffic
in
near-‐real;me3
• [ML]
Detec;ng
fraudulent
transac;ons
using
clustering4
43
[1]
hMp://blog.cloudera.com/blog/2012/08/process-‐a-‐million-‐songs-‐with-‐apache-‐pig/
[2]
hMp://blog.cloudera.com/blog/2014/01/how-‐wajam-‐answers-‐business-‐ques;ons-‐faster-‐with-‐hadoop/
[3]
hMp://blog.cloudera.com/blog/2013/09/email-‐indexing-‐using-‐cloudera-‐search/
[4]
hMp://blog.cloudera.com/blog/2013/03/cloudera_ml_data_science_tools/](https://image.slidesharecdn.com/buildinghadoopdataapplicationswithkite-140625073911-phpapp02/85/Building-Hadoop-Data-Applications-with-Kite-43-320.jpg)


![Morphlines
Example
46
morphlines
:
[
{
id
:
morphline1
importCommands
:
["com.cloudera.**",
"org.apache.solr.**"]
commands
:
[
{
readLine
{}
}
{
grok
{
dic;onaryFiles
:
[/tmp/grok-‐dic;onaries]
expressions
:
{
message
:
"""<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_;mestamp}
%
{SYSLOGHOST:syslog_hostname}
%{DATA:syslog_program}(?:[%{POSINT:syslog_pid}])?:
%
{GREEDYDATA:syslog_message}"""
}
}
}
{
loadSolr
{}
}
]
}
]
Example Input
<164>Feb 4 10:46:14 syslog sshd[607]: listening on 0.0.0.0 port 22
Output Record
syslog_pri:164
syslog_timestamp:Feb 4 10:46:14
syslog_hostname:syslog
syslog_program:sshd
syslog_pid:607
syslog_message:listening on 0.0.0.0 port 22.](https://image.slidesharecdn.com/buildinghadoopdataapplicationswithkite-140625073911-phpapp02/85/Building-Hadoop-Data-Applications-with-Kite-46-320.jpg)

The document discusses the development of Hadoop data applications using the Kite SDK, highlighting its features, components, and example use cases. It outlines the advantages of Kite for simplifying data input into Hadoop with flexible schema models and modular storage options. The presentation also covers various Apache Hadoop tools and their integration with Kite, providing an overview of batch processing, interactive SQL querying, and data management techniques.


































































