Download to read offline






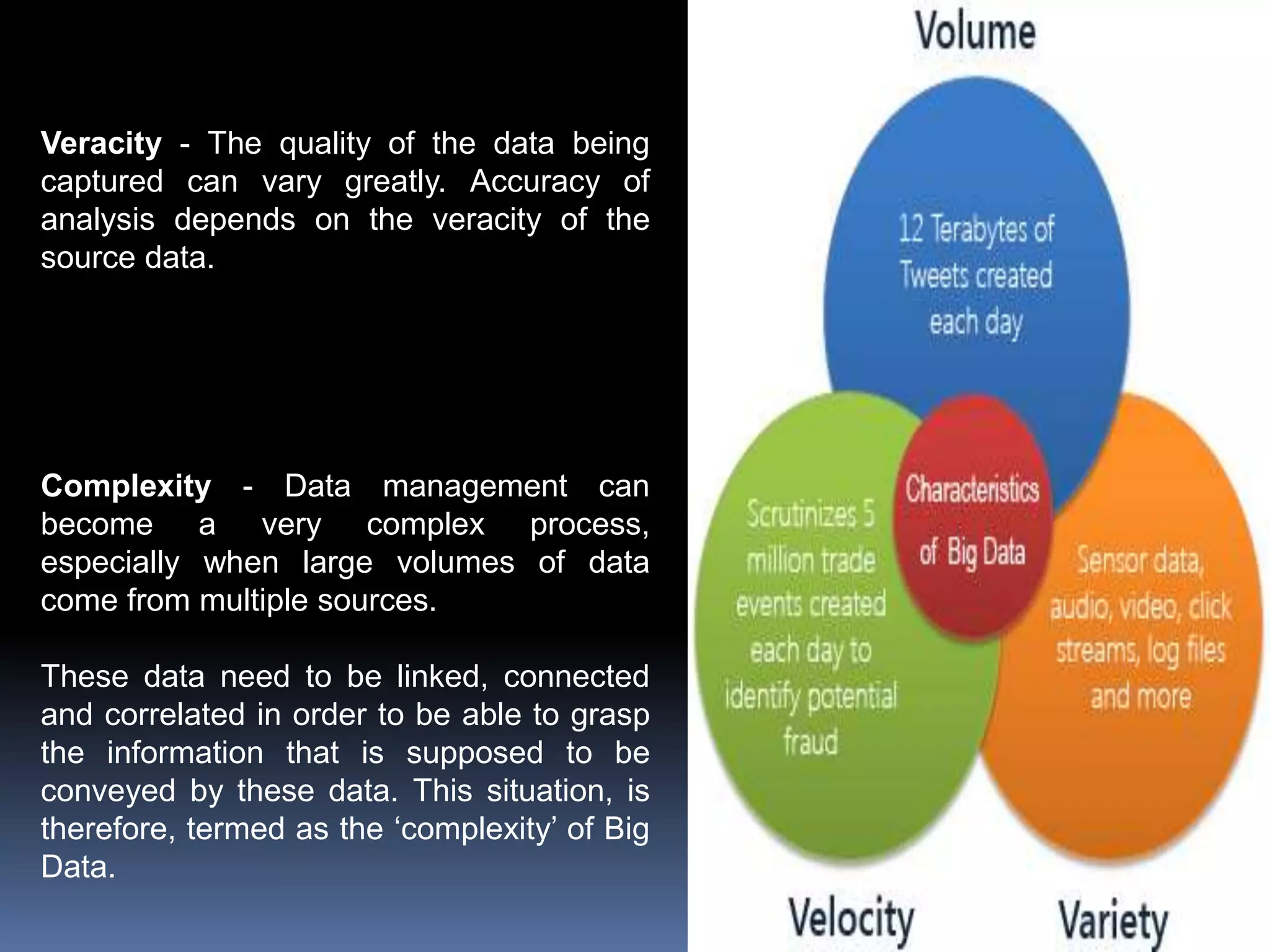

















Big data refers to data that exceeds the capabilities of traditional database systems, characterized by its volume, variety, velocity, variability, veracity, and complexity. The document outlines the historical development of data processing and the emergence of big data tools and technologies, including early data projects and the invention of the World Wide Web. It highlights the significance of big data in modern society and the growing need for skilled data professionals.










































































































