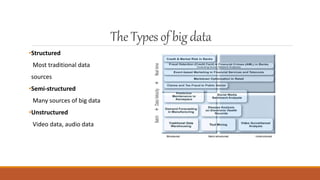
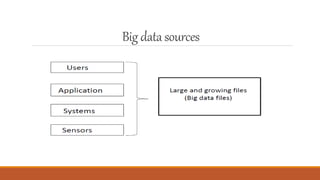
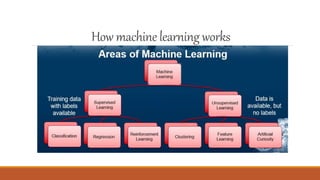
Big data and machine learning are growing fields. Big data involves capturing, storing, and analyzing very large amounts of data from various sources that cannot be handled with traditional methods. It faces challenges around capture, curation, storage, search, sharing, transfer, analysis and visualization. Machine learning is a type of artificial intelligence that allows systems to learn from data without being explicitly programmed. There are several types of machine learning including supervised learning, unsupervised learning, and reinforcement learning. Machine learning is being applied in many areas like personalized recommendations, fraud detection, and predictive maintenance.