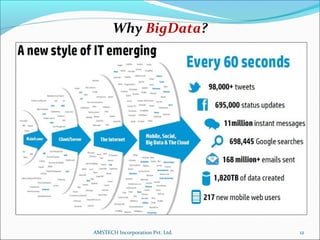
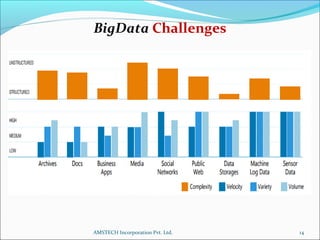
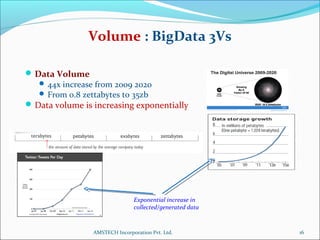
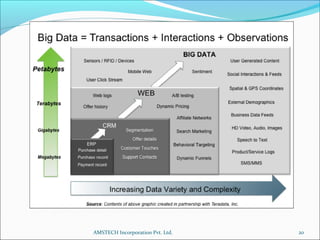
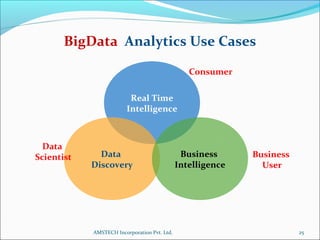
1. The document discusses Big Data analytics using Hadoop. It defines Big Data and explains the characteristics of volume, velocity, and variety.
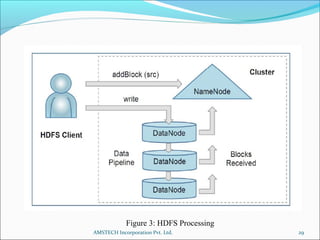
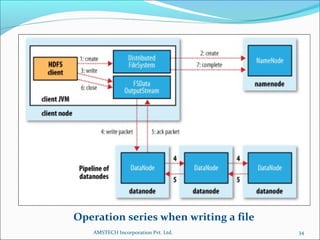
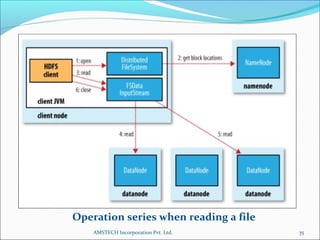
2. Hadoop is introduced as a framework for distributed storage and processing of large data sets across clusters of commodity hardware. It uses HDFS for reliable storage and streaming of large data sets.
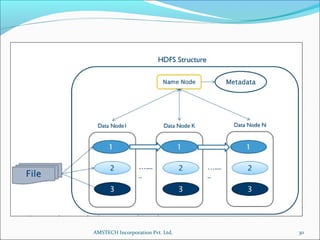
3. Key Hadoop components are the NameNode, which manages file system metadata, and DataNodes, which store and retrieve data blocks. Hadoop provides scalability, fault tolerance, and high performance on large data sets.










![Why BigData?
To Manage Data Better.
[Abstraction has enabled numerous use cases where
data in a wide variety of formats]
Benefit From Speed, Capacity and Scalability of Cloud
Storage.
[Utilize substantially large data sets provide both the storage and
the computing power necessary crunch data for a specific period.]
End Users Can Visualize Data
[Data in easy-to-read charts, graphs and slideshows]
10AMSTECH Incorporation Pvt. Ltd.](https://image.slidesharecdn.com/l1-nmims-170728140247-180425112702/85/big-data-10-320.jpg)
![Why BigData?
Find New Business Opportunities.
[Social media, Business Intelligence]
Data Analysis Methods, Capabilities Will Evolve
[Utilize substantially large data sets provide both the storage and
the computing power necessary crunch data for a specific period.]
11AMSTECH Incorporation Pvt. Ltd.](https://image.slidesharecdn.com/l1-nmims-170728140247-180425112702/85/big-data-11-320.jpg)