Download as PDF, PPTX

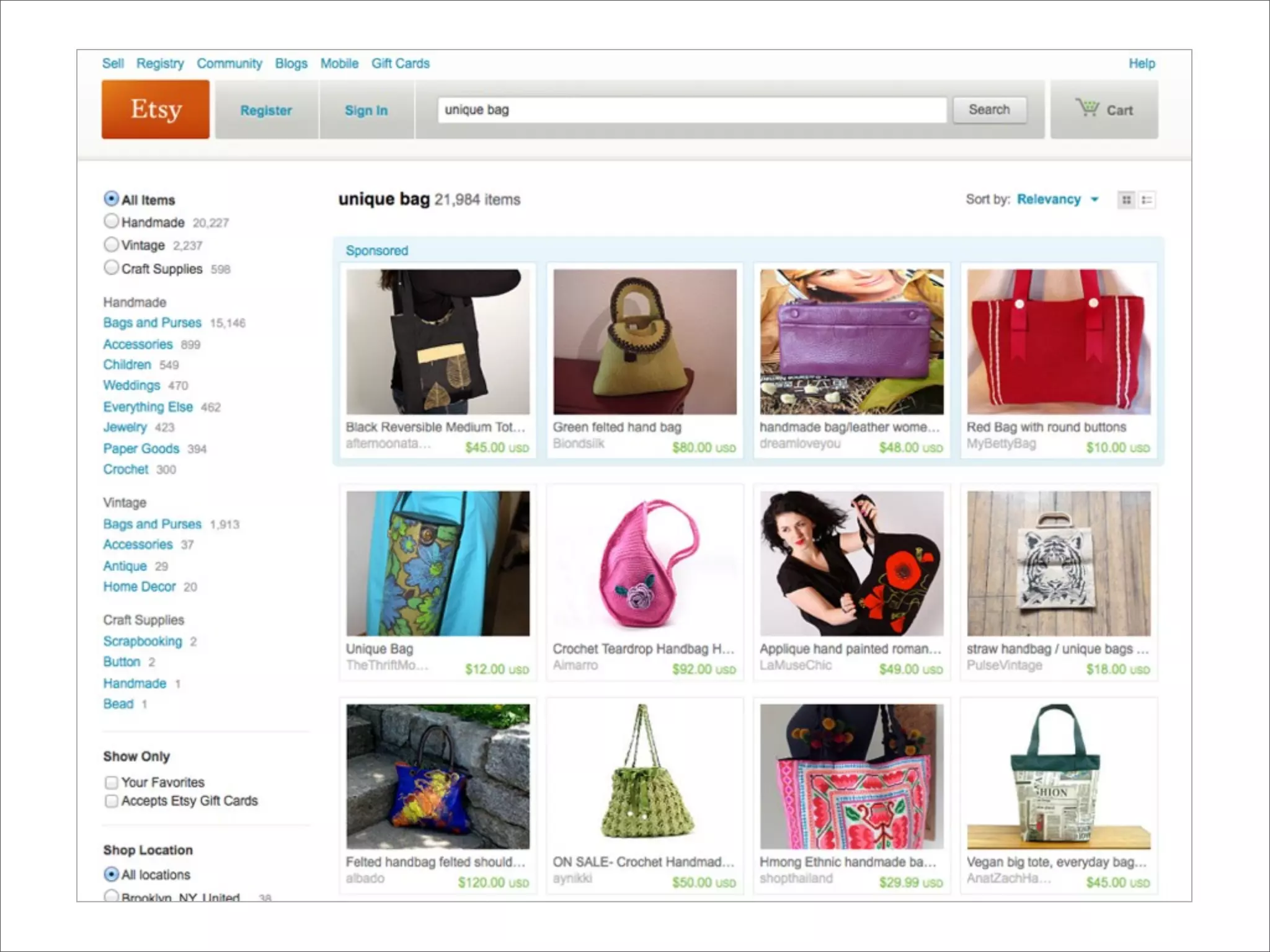


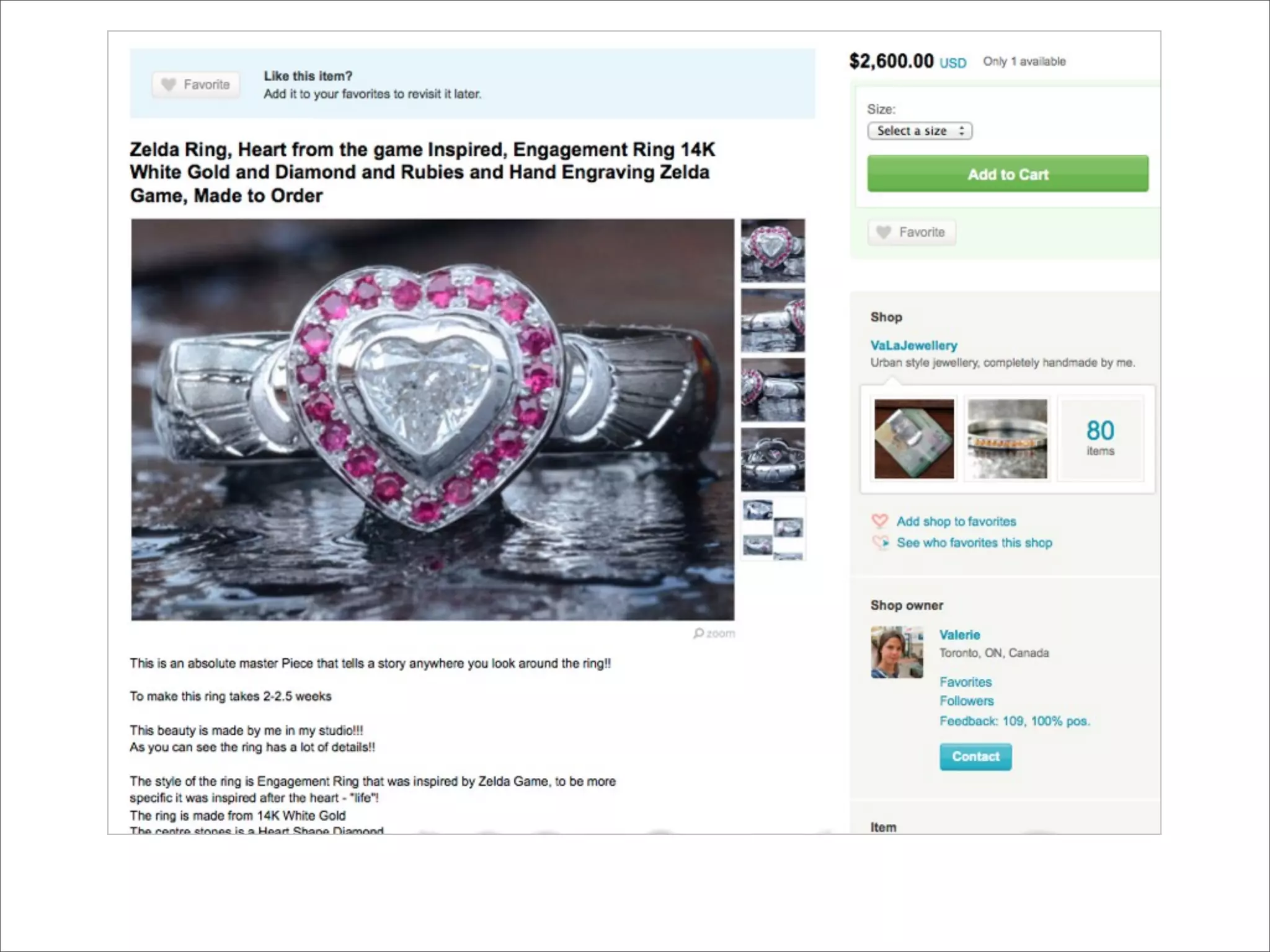




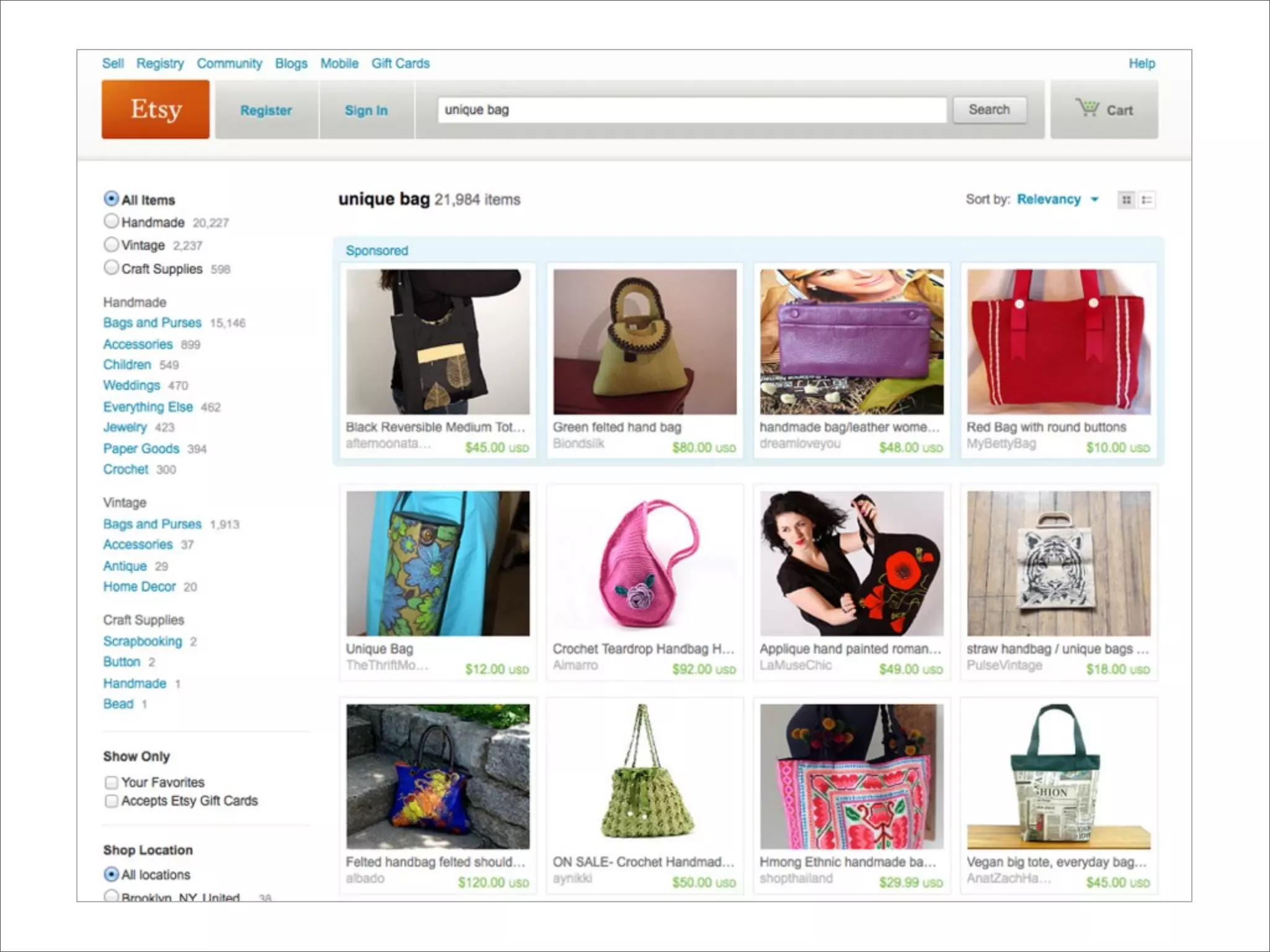



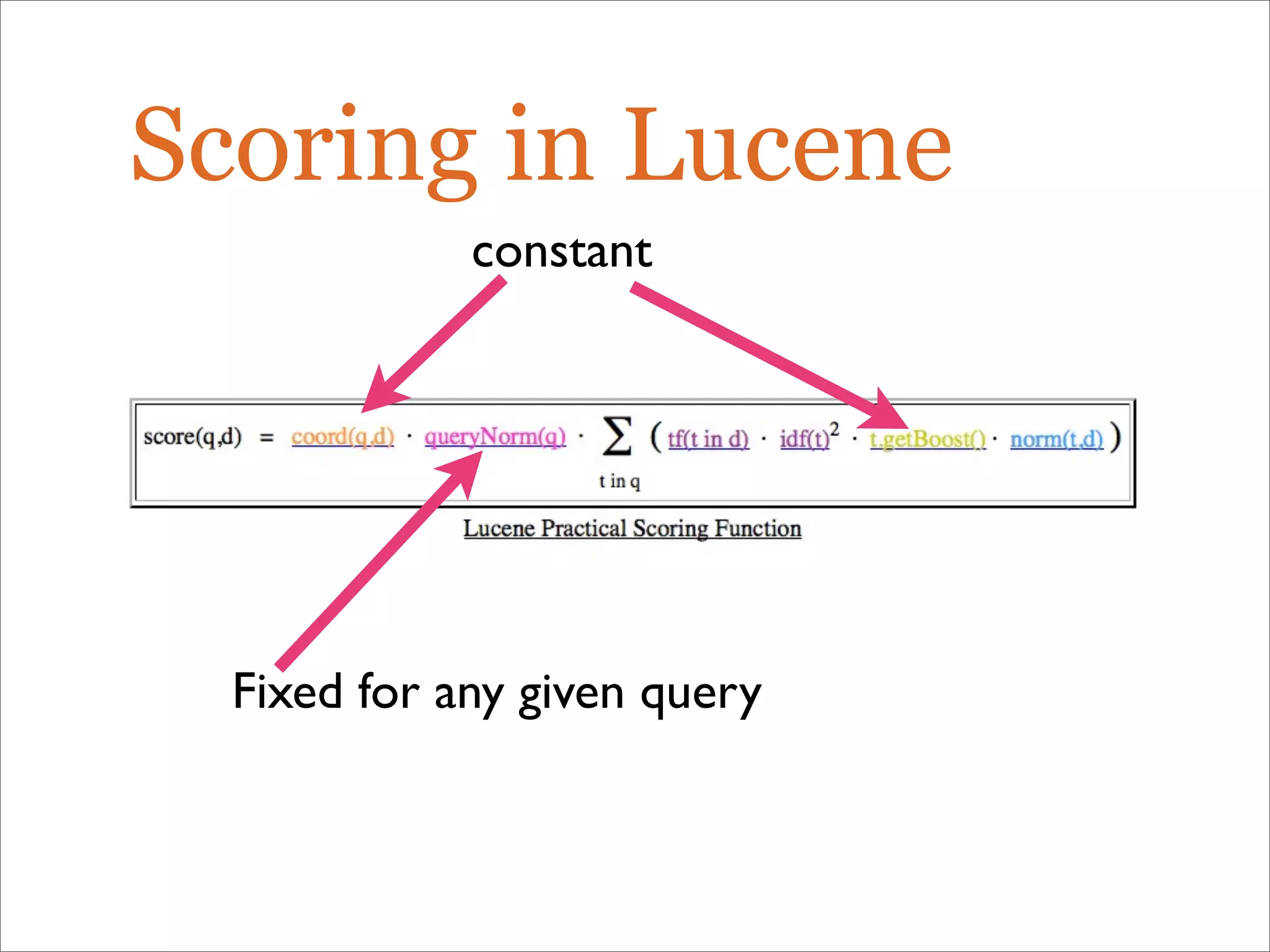
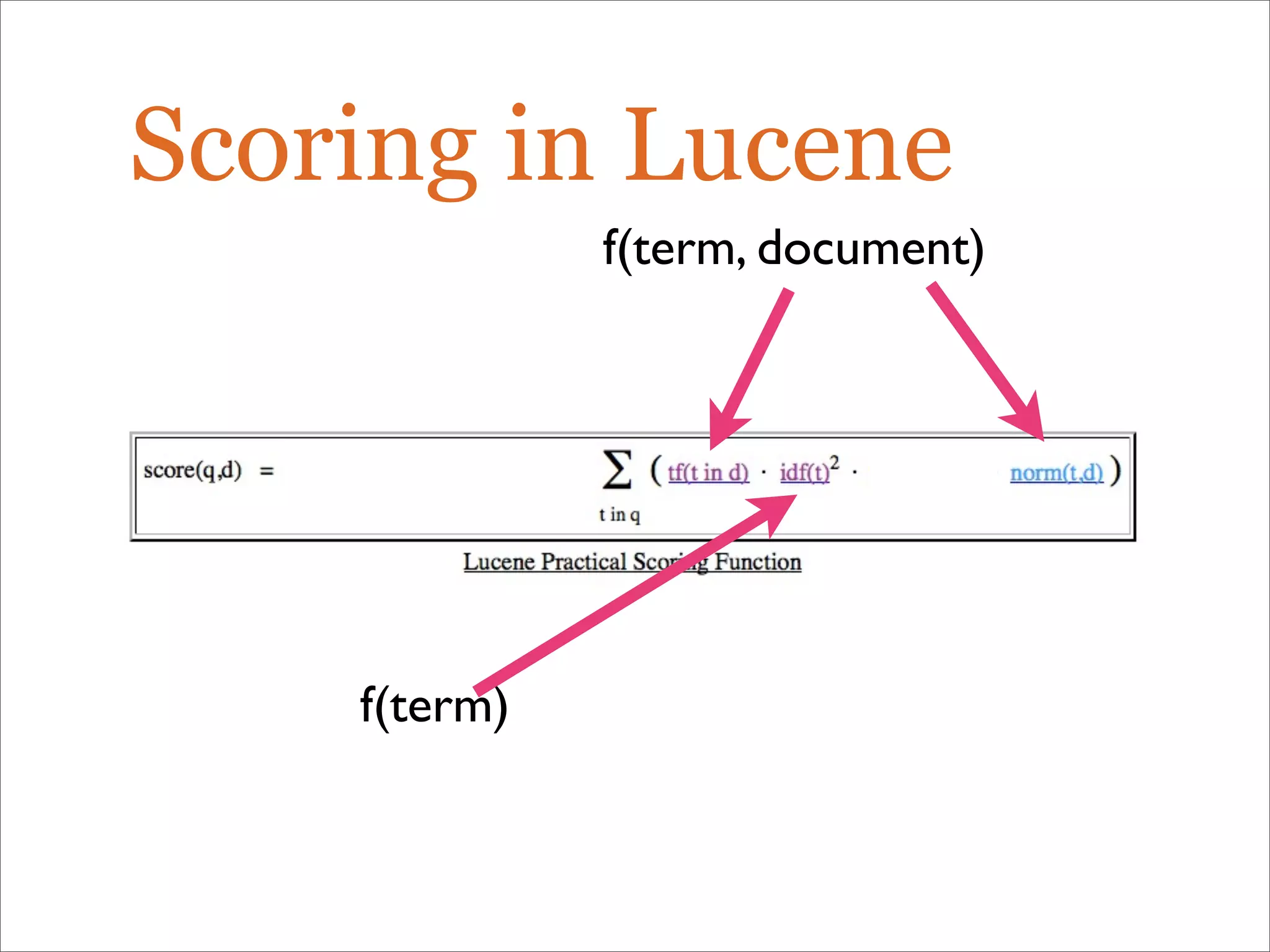
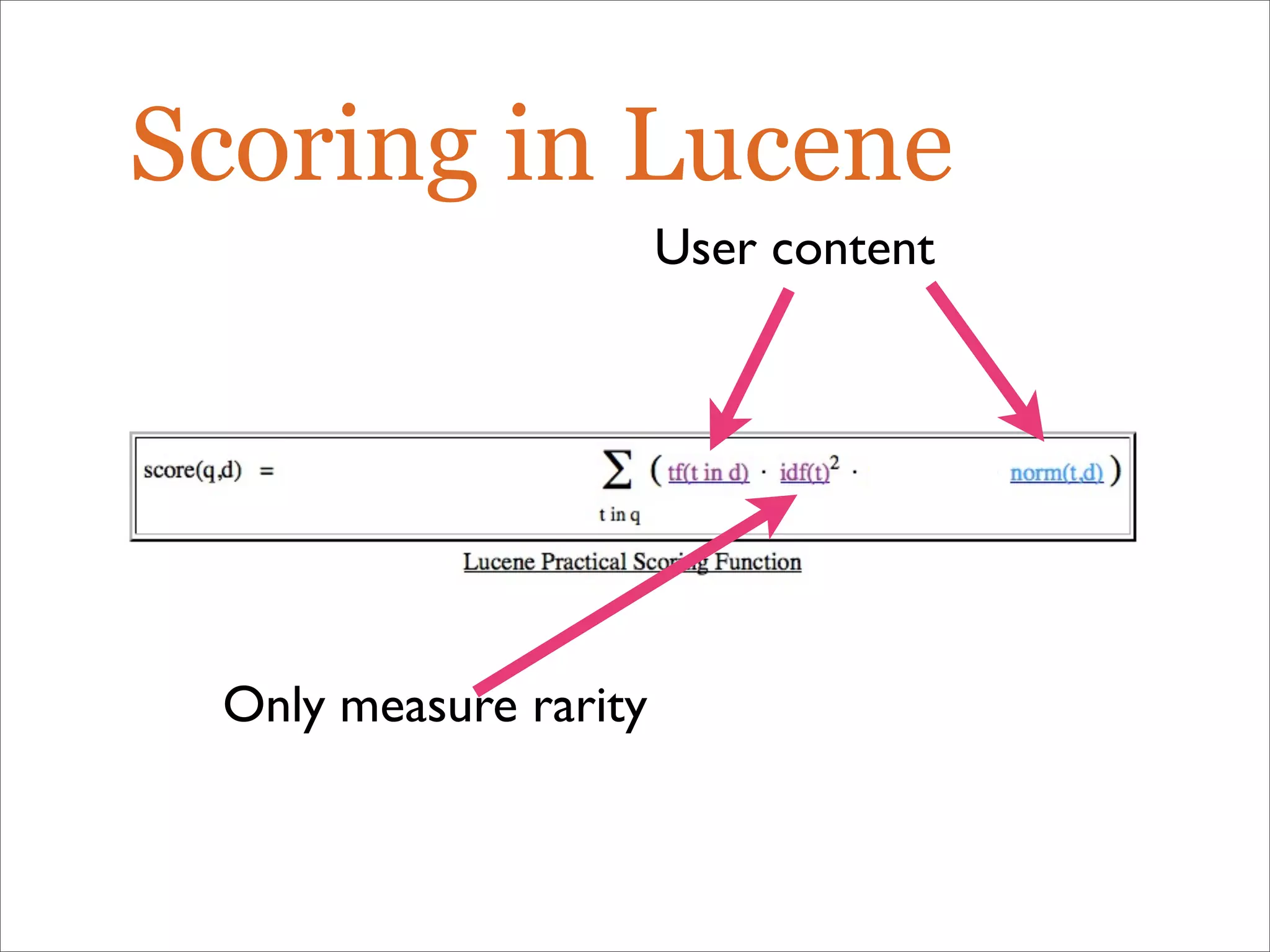











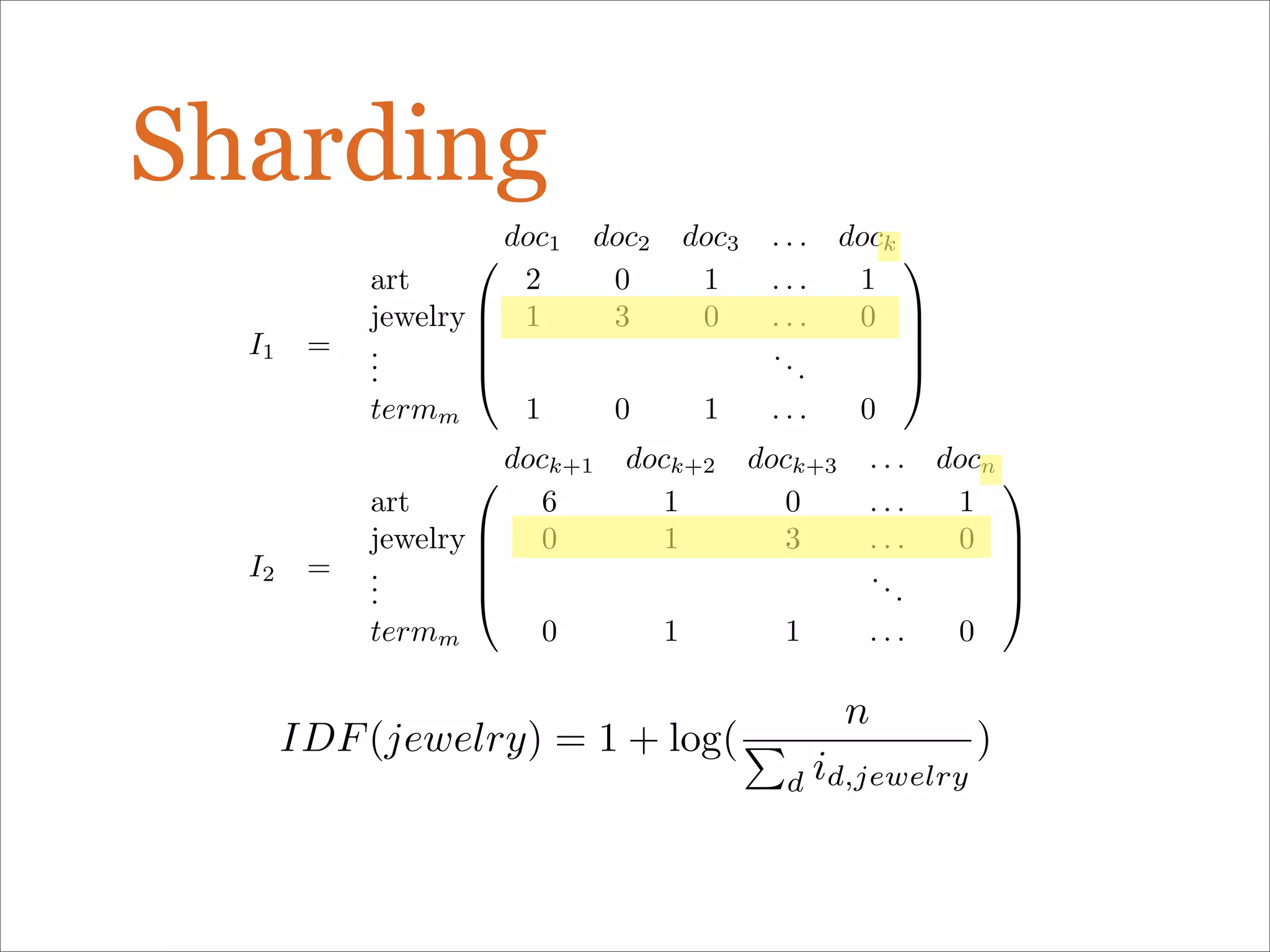
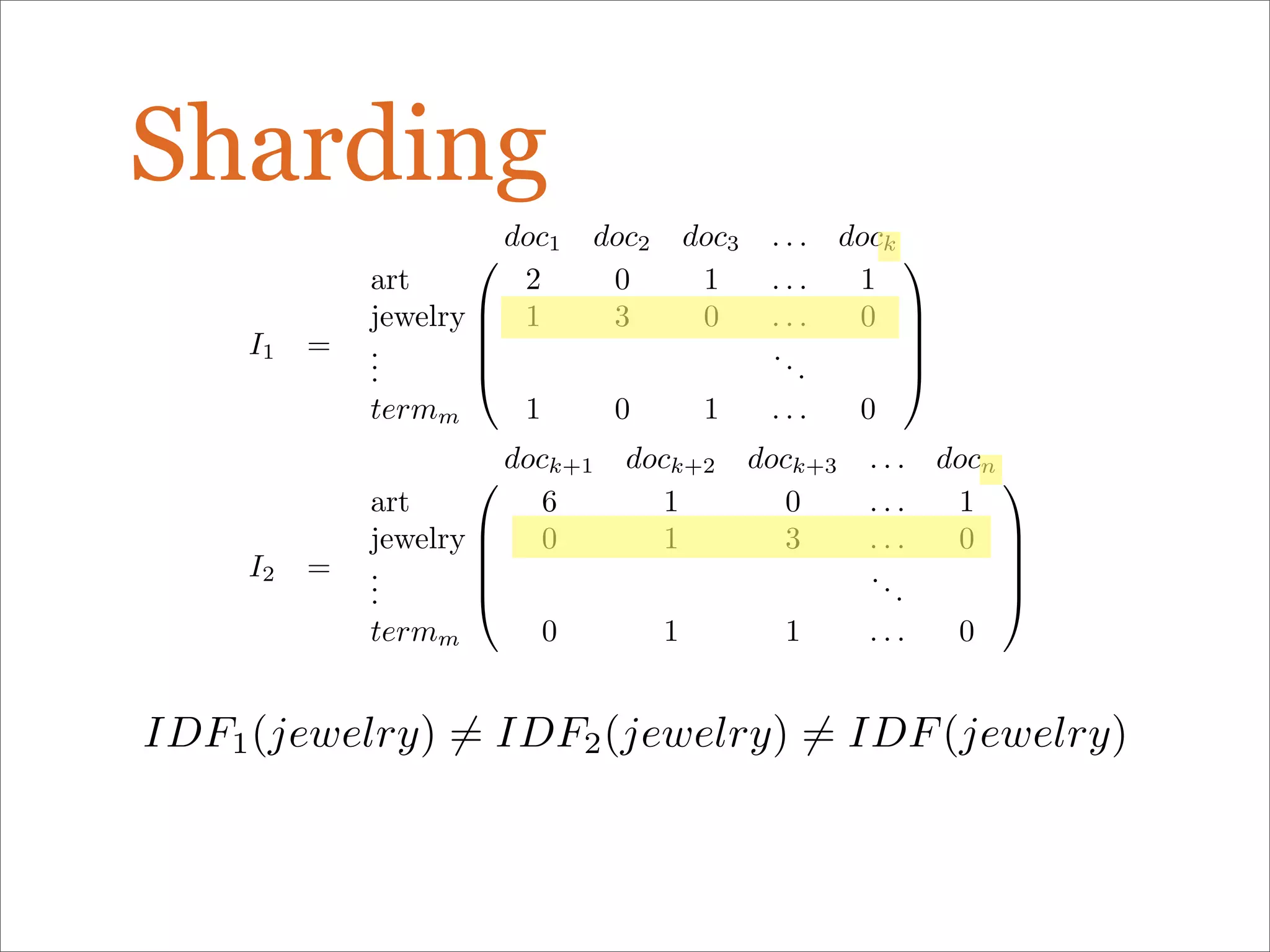
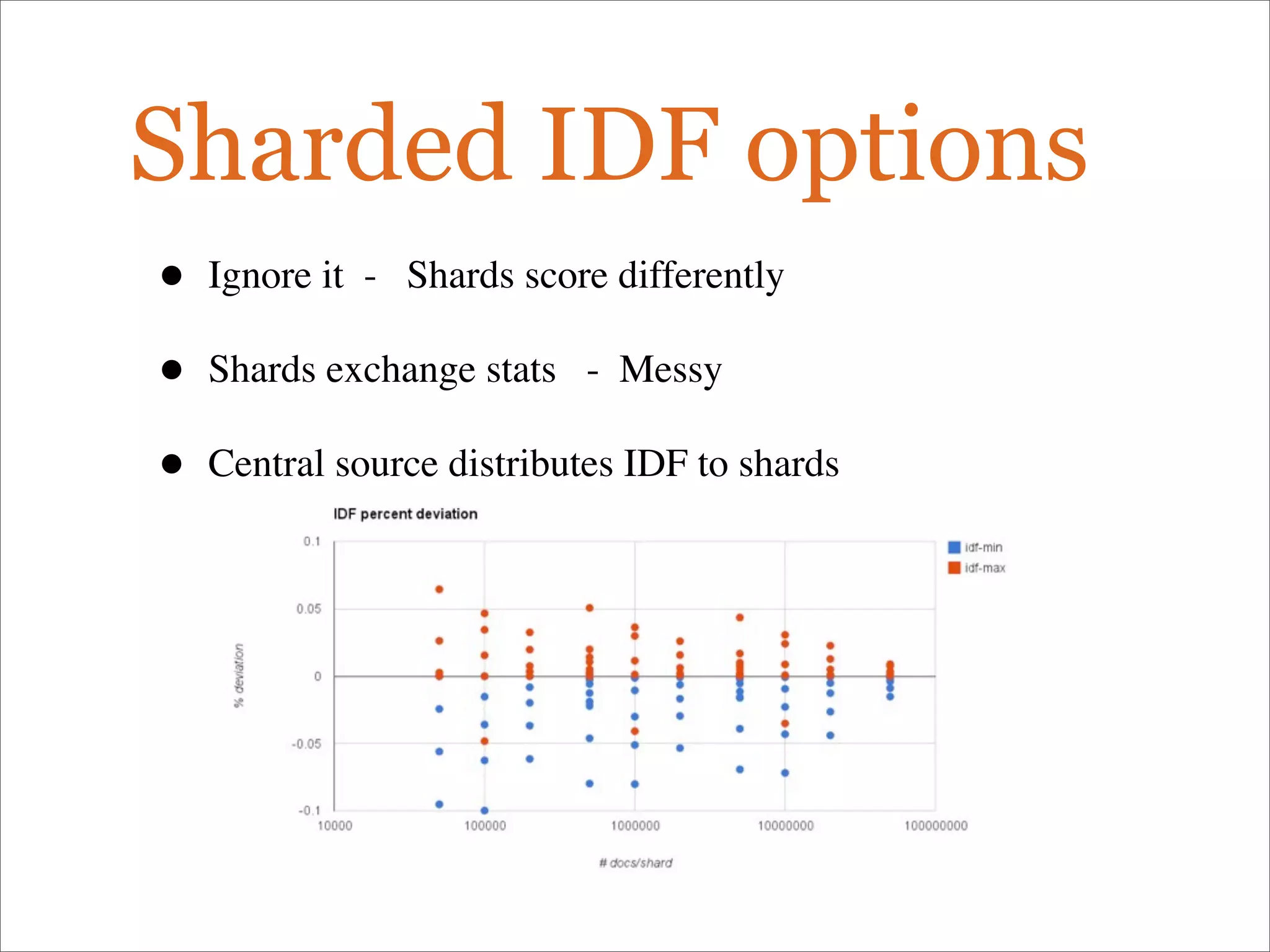

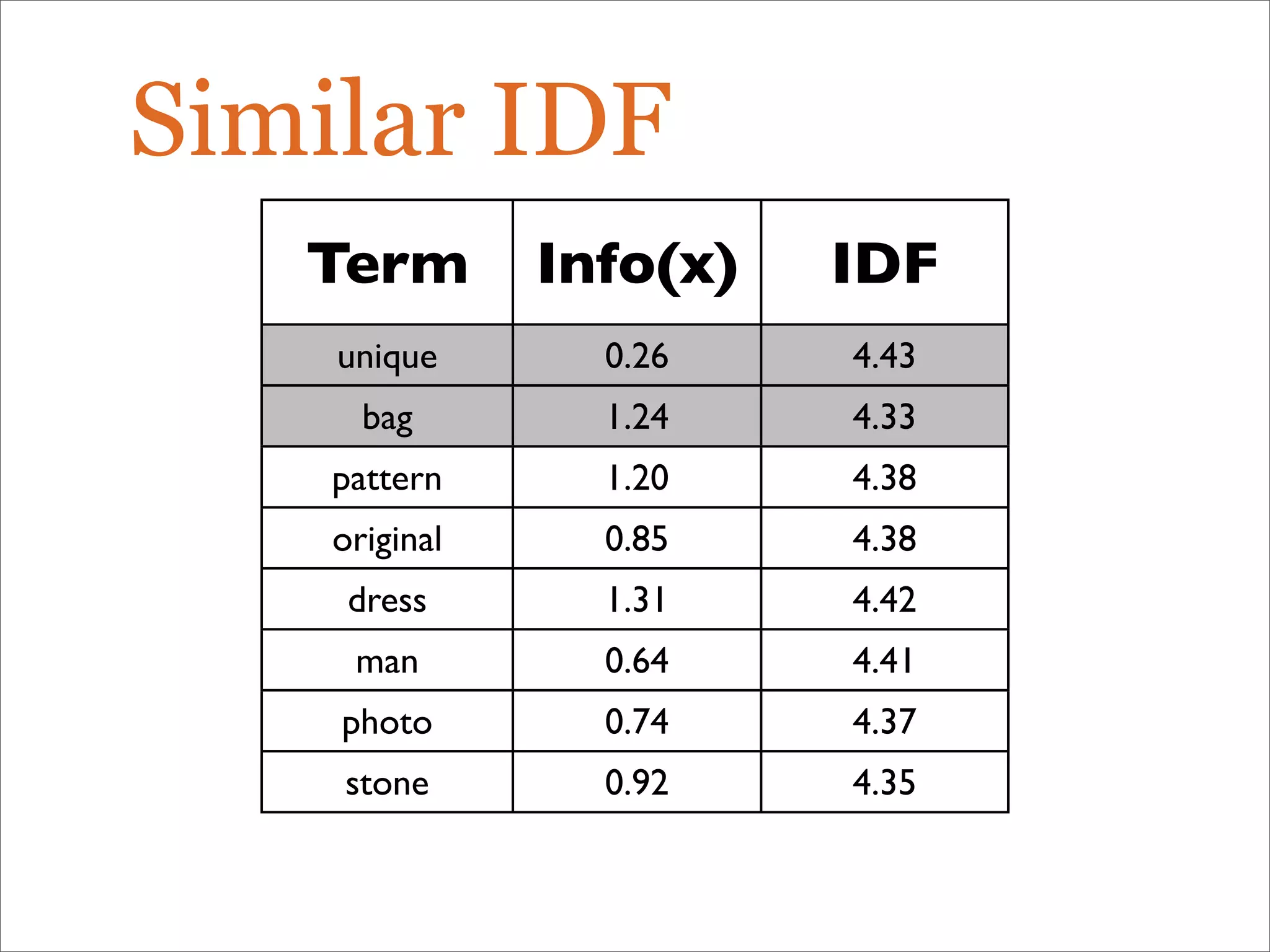
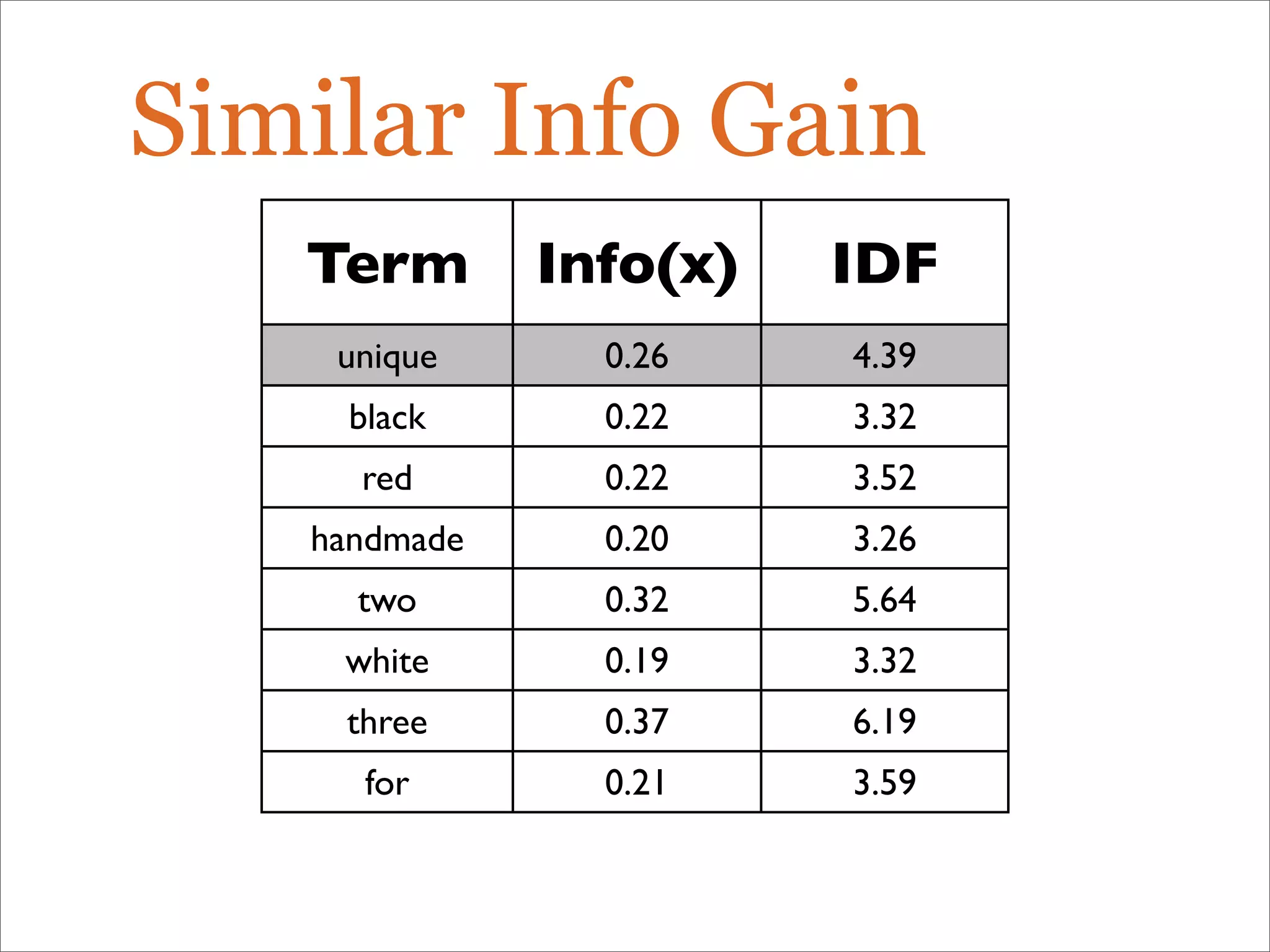





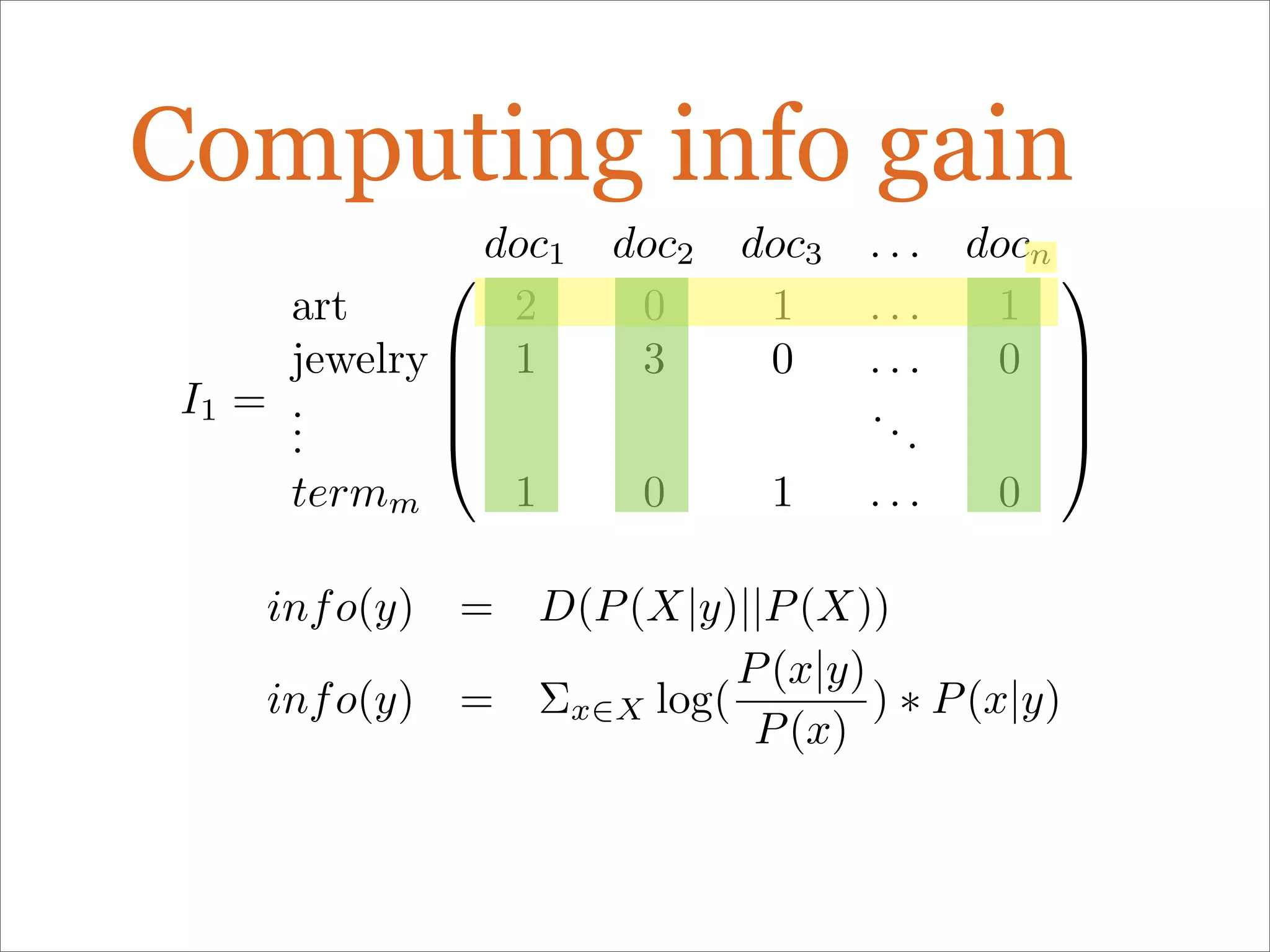


















The document discusses enhancements to the traditional tf-idf model used in search systems at Etsy, focusing on an experiment-driven culture that employs information gain to improve search relevance. It outlines the shortcomings of using idf, specifically its failure to measure term usefulness, and proposes a new approach that incorporates term quality. Additionally, the document details technical implementations involving Hadoop for computing term distributions and emphasizes future directions such as latent semantic indexing.























































































