Best practices data management
•Download as PPTX, PDF•
5 likes•3,805 views

Presentation for the REU's, Mountain Lake Biological Station 5/28/2014.

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Similar to Best practices data management
Similar to Best practices data management (20)
More from Sherry Lake
More from Sherry Lake (20)
Recently uploaded
Recently uploaded (20)
Best practices data management
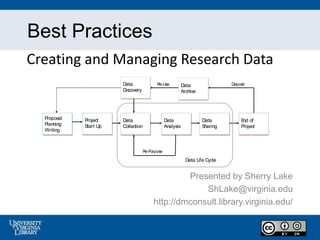
- 1. Best Practices Creating and Managing Research Data Presented by Sherry Lake ShLake@virginia.edu http://dmconsult.library.virginia.edu/ Data Life Cycle Re-Purpose Re-Use Deposit Data Collection Data Analysis Data Sharing Proposal Planning Writing Data Discovery End of Project Data Archive Project Start Up
- 2. Why Manage Your Data?
- 3. Best Practices for Creating Data 1. Use Consistent Data Organization 2. Use Standardized Naming, codes and formats 3. Assign Descriptive File Names 4. Perform Basic Quality Assurance / Quality Control 5. Preserve Information - Use Scripted Languages 6. Define Contents of Data Files; Create Documentation 7. Use Consistent, Stable and Open File Formats
- 5. Spreadsheets
- 6. Consistent Data Organization • Spreadsheets (such as those found in Excel) are sometimes a necessary evil – They allow “shortcuts” which will result in your data not being machine-readable • But there are some simple steps you can take to ensure that you are creating spreadsheets that are machine-readable and will withstand the test of time
- 7. Spreadsheets
- 9. Problems • Dates are not stored consistently • Values are labeled inconsistently • Data coding is inconsistent • Order of values are different
- 10. Problems • Confusion between numbers and text • Different types of data are stored in the same columns • The spreadsheet loses interpretability if it is sorted
- 11. How would you correct this file?
- 12. Spreadsheet Best Practices • Include a Header Line 1st line (or record) • Label each Column with a short but descriptive name Names should be unique Use letters, numbers, or “_” (underscore) Do not include blank spaces or symbols (+ - & ^ *)
- 13. • Columns of data should be consistent – Use the same naming convention for text data • Each line should be “complete” • Each line should have a unique identifier Spreadsheet Best Practices
- 14. Spreadsheet Best Practices • Columns should include only a single kind of data – Text or “string” data – Integer numbers – Floating point or real numbers
- 15. Use Naming Standards & Codes • Use commonly accepted label names that describe the contents (e.g., precip for precipitation) • Use consistent capitalization (e.g., not: temp, Temp, and TEMP in same file) • Standard codes – State Postal (VA, MA) – FIPS Codes for Counties and County Equivalent Entities (http://www.census.gov/geo/reference/codes/cou.html)
- 16. Use Standardized Formats • Use standardized formats for units International System of Units (SI) http://physics.nist.gov/Pubs/SP330/sp330.pdf • ISO 8601 Standard for Date and Time YYYYMMDDThh:mmss.sTZD 20091013T09:1234.9Z 20091013T09:1234.9+05:00 • Spatial Coordinates for Latitute/Longitude +/- DD.DDDDD -78.476 (longitude) +38.029 (latitude)
- 17. File Names
- 18. File Names • Use descriptive names • Not too long; CamelCase • Try to include time – Date using YYYYMMDD – Use version numbers • Don’t use spaces – May use “-” or “_” • Don’t change default extensions
- 19. Organize Files Logically Make sure your file system is logical and efficient Biodiversity Lake Grassland Experiments Field Work Biodiv_H20_heatExp_2005_2008.csv Biodiv_H20_predatorExp_2001_2003.csv Biodiv_H20_planktonCount_start2001_active.csv Biodiv_H20_chla_profiles_2003.csv Project Name Location Experiment Name Date File Format
- 20. • Check for missing, impossible, anomalous values – Plotting – Mapping • Examine summary statistics • Verify data transfers from notebooks to digital files • Verify data conversion from one file format to another Data Validation Hook, et al. 2010. Best Practices for Preparing Environmental Data Sets to Share and Archive. Available online: http://daac.ornl.gov/PI/BestPractices-2010.pdf.
- 21. Data Manipulation • You will need to repeat reduction and analysis procedures many times – You need to have a workflow that recognizes this – Scripted languages can help capture the workflow – You could just document all steps by hand – After the 20th iteration through your data set; however, you may feel more fondly towards scripted languages • Learn the analytical tools of your field – Talk to colleagues, etc. and choose at least one tool to master
- 22. Preserve Information Keep Original (Raw) File – Do not include transformations, interpolations, etc. – Consider making the raw data “read-only” Save as a new file Processing Script (R)
- 23. Preserving: Scripted Notes • Use a scripted language to process data – R Statistical package (free, powerful) – SAS – MATLAB • Processing scripts records processing – Steps are recorded in textual format – Can be easily revised and re-executed – Easy to document • GUI-based analysis may be easier, but harder to reproduce
- 24. Data Documentation (Metadata) • Informal or formal methods to describe your data • Important if you want to reuse your own data in the future • Also necessary when sharing your data
- 25. Define Contents of Data Files • Create a Project Document File (Lab Notebook) • Details such as: – Names of data & analysis files associated with study – Definitions for data and codes (include missing value codes, names) – Units of measure (accuracy and precision) – Standards or instrument calibrations
- 28. Data Documentation Project Documentation Dataset Documentation • Context of data collection • Data collection methods • Structure, organization of data files • Data sources used • Data validation, quality assurance • Transformations of data from the raw data through analysis • Information on confidentiality, access and use conditions • Variable names and descriptions • Explanation of codes and schemas used • Algorithms used to transform data • File format and software (including version) used
- 29. File Format Sustainability Types Examples Text ASCII, Word, PDF Numerical ASCII, SPSS, STATA, Excel, Access, MySQL Multimedia Jpeg, tiff, mpeg, quicktime Models 3D, statistical Software Java, C, Fortran Domain-specific FITS in astronomy, CIF in chemistry Instrument-specific Olympus Confocal Microscope Data Format
- 30. Choosing File Formats • Accessible Data (in the future) – Non-proprietary (software formats) – Open, documented standard – Common, used by the research community – Standard representation (ASCII, Unicode) – Unencrypted & Uncompressed
- 31. 1. Use Consistent Data Organization 2. Use Standardized Naming, Codes and Formats 3. Assign Descriptive File Names 4. Perform Basic Quality Assurance / Quality Control 5. Preserve Information - Use Scripted Languages 6. Define Contents of Data Files; Create Documentation 7. Use Consistent, Stable and Open File Formats Best Practices for Creating Data
- 32. • Will improve the usability of the data by you or by others • Your data will be “computer ready” • Save you time Following these Best Practices…….
- 33. Research Life Cycle Data Life Cycle Re- Purpose Re- Use Deposit Data Collection Data Analysis Data Sharing Proposal Planning Writing Data Discovery End of Project Data Archive Project Start Up
- 34. Managing Data in the Data Life Cycle • Choosing file formats • File naming conventions • Document all data details • Access control & security • Backup & storage
- 35. Data Security & Access Control • Network security – keep confidential or sensitive data off internet servers or computers on connected to the internet • Physical security – Access to buildings and rooms • Computer Systems & Files – Use passwords on files/system – Virus protection
- 36. Backup Your Data • Reduce the risk of damage or loss • Use multiple locations (here, near, far) • Create a backup schedule • Use reliable backup medium • Test your backup system (i.e., test file recovery)
- 37. Storage & Backup
- 38. Sustainable Storage Lifespan of Storage Media: http://www.crashplan.com/medialifespan/
- 39. Best Practices Bibliography Borer, E. T., Seabloom, E. W., Jones, M. B., & Schildhauer, M. (2009). Some simple guidelines for effective data management. Bulletin of the Ecological Society of America, 90(2), 205-214. http://dx.doi.org/10.1890/0012-9623-90.2.205 Graham, A., McNeill, K., Stout, A., & Sweeney, L. (2010). Data Management and Publishing. Retrieved 05/31/2012, from http://libraries.mit.edu/guides/subjects/data-management/. Hook, L. A., Santhana Vannan, S.K., Beaty, T. W., Cook, R. B. and Wilson, B.E. (2010). Best Practices for Preparing Environmental Data Sets to Share and Archive. Available online (http://daac.ornl.gov/PI/BestPractices-2010.pdf) from Oak Ridge National Laboratory Distributed Active Archive Center, Oak Ridge, Tennessee, U.S.A. http://dx.doi.org/10.3334/ORNLDAAC/BestPractices-2010.
- 40. Best Practices Bibliography (Cont.) Inter-university Consortium for Political and Social Research (ICPSR). (2012). Guide to social science data preparation and archiving: Best practices throughout the data cycle (5th ed.). Ann Arbor, MI. Retrieved 05/31/2012, from http://www.icpsr.umich.edu/files/ICPSR/access/dataprep.pdf. Van den Eynden, V., Corti, L., Woollard, M. & Bishop, L. (2011). Managing and Sharing Data: A Best Practice Guide for Researchers (3rd ed.). Retrieved 05/31/2012, from http://www.data- archive.ac.uk/media/2894/managingsharing.pdf.
Editor's Notes
- The following are seven basic data habits that will help improve the information content of your data and make it easier to share data with others: Some have estimated that researchers can spend up to 80% of their time finding, accessing, understanding, and preparing data and only 20% of their time actually analyzing the data. The habits described in this module will help scientists spend more time doing research and less time doing data management.
- Spreadsheets are widely used for simple analyses They are easy to use BUT They allow (encourage) users to structure data in ways that are hard to use with other software You can use them like Word, with columns. These spreadsheets (in this format) are good for “human” interpretation, not computers – and since you probably will need either Write a program or use a software package, then the “human” format is not best. These formats are good for presenting your findings such as publishing…. But it will be harder to use with other software later on (if you need to do any analysis). It is better to store the data in ways that it can be used in automated ways, with minimal human intervention
- Example of Poor Data Practice for Collaboration and Sharing This illustration shows an example of poor practice for working in spreadsheets for data collection. At first glance, it may appear this data is well formulated, but a closer look reveals a number of practices that will make it difficult to re-use in its present state. For example, there are calculations in the far right columns that appear to have been made during a data analysis phase but that do not represent valid data entries. Notice in the upper right corner a comment stating “Don’t use – old data”, and “Peter’s lab”. These remarks leave the viewer wondering about who Peter is and which lab he was located in, as well as why this data may not be the most accurate data spreadsheet. One also may wonder what the “c” located in the far right column represents, and what the numbers at the bottom of the spreadsheet represent, since they are unaffiliated with a particular row of data in the spreadsheet. Notice there are numbers added in inconsistent places (two numbers at the bottom of the chart) and the letter “C” appears in an unlabeled column.
- Spreadsheets are widely used for simple analyses They are easy to use, however… They allow (encourage) users to structure data in ways that are hard to use with other software You can use them like you would a Word document, with columns and colors. These spreadsheets (in this format) are good for “human” interpretation, not computers – and since you probably will need to either write a program or use a software package, then the “human” format is not best. These formats are good for presenting your findings (publishing)…. But it will be harder to use with other software later on (if you need to do any further analysis). It is better to store the data in formats that it can be used in automated ways, with minimal human intervention
- This is some well data measurements, where a salinity meter was used to measure the salinity (top and bottom) and the conductivity (Top & bottom) Take a look at this spreadsheet… What’s wrong with it? Could this be easily automated? Sorted? Would you create a file like this?
- Dates are not stored consistently Sometimes date is stored with a label (e.g., “Date:5/23/2005”) sometimes in its own cell (10/2/2005) Values are labeled inconsistently Sometimes “Conductivity Top” others “conductivity_top” For Salinity sometimes two cells are used for top and bottom, in others they are combined in one cell Data coding is inconsistent Sometimes YSI_Model_30, sometimes “YSI Model 30”---- sort of can’t tell if it’s a “label” or a data value Tide State is sometimes a text description, sometimes a number The order of values in the “mini-table” for a given sampling date are different “Meter Type” comes first in the 5/23 table and second in the 10/2 table
- Confusion between numbers and text For most software 39% or <30 are considered TEXT not numbers (what is the average of 349 and <30?) Different types of data are stored in the same columns Many software products require that a single column contain either TEXT or NUMBERS (but not both!) The spreadsheet loses interpretability if it is sorted Dates are related to a set of attributes only by their position in the file. Once sorted that relationship is lost. Not sure why you would sort this.
- Hint – think about representing missing values and about sortability You want each row to be a complete record…. With no blank cells – think about a way to represent “missing values” Designed to be machine readable, not human readable The original spreadsheet loses interpretability if it is sorted Dates are related to a set of attributes only by their position in the file. Once sorted that relationship is lost
- -Sherry Standard convention for many software programs (usually a “check” yes,no) is for the 1st line (record) to be a header line… lists the names of variables in the file. Rest of records (lines) are data. Not too long some software programs may not work with long variable names
- Each line in the spreadsheet should have each cell filled. Otherwise, it isn’t machine-readable, and it won’t even survive a “sort” operation. Note we’ve changed the format of the date to an ISO YYYYMMDD format.
- Format the columns so they contain a single type of data… One problem with Excel is that it doesn’t like to show trailing zeros. So “33.0” in F2 is shown as “33” unless you change the formatting, as we have done here.
- (am/pm NOT allowed) T appears literally in the string. Min. for date is YYYY. YYYY = four-digit year MM = two-digit month (01=January, etc.) DD = two-digit day of month (01 through 31) hh = two digits of hour (00 through 23) mm = two digits of minute (00 through 59) ss = two digits of second (00 through 59) s = one or more digits representing a decimal fraction of a second TZD = time zone designator (Z or +hh:mm or -hh:mm) 38.029N. The longitude is -78.476W
- File names should reflect the contents of the file and uniquely identify the data file. File names may contain information such as project acronym, study title, location, investigator, year(s) of study, data type, version number, and file type. Think about how the name will look in a directory with lots of other files, want to be able to “pick it out”. Having trouble finding files, telling the most recent one?
- File names are the easiest way to indicate the contents of the file. Use terse names but indicative of their content. Want to uniquely id the data file. Be unique but reflect the file content. Think about the organizing principle, don’t just make up a system as you go along. Don’t’ make them too long, some scripting programs have a filename limit for file importing (reading) Don’t use blanks/spaces in file names, some software may not be able to read file names with blanks. Think about how the name will look in a directory with lots of other files, want to be able to “pick it out”.
- As with naming files…. Similar logic is useful when designing file directory structures and names, which you should ensure is logical and efficient in design
- Perform basic quality assurance Doing quality control will help you in your project but it will also help those who want to use your data. Would you want to use data that you were not sure of the quality?
- You don’t want to change something (or delete something) that could be important later (and you don’t know now what that may be). Make corrections/deletions in a derivative file, never in the original file. Things to think about: Operationally, you want to keep the raw data until you are “finished” Whether you preserve the raw data after the project is over depends on various factors. Most importantly, can the data be easily regenerated? If this is experimental data, it often is. However, observational, or survey data usually isn’t reproducible, and needs to be preserved after the end of the project. How would you name the new file? If use a scripted language you could re-run analyses It is important to take good notes of what changes you make to the data (file).
- To preserve your data and its integrity, save a "read-only" copy of your raw data files with no transformations, interpolation, or analyses. Use a scripted language such as “R”, “SAS” or “MATLAB” to process data in a separate file, located in a separate directory. In this example, an “R” to call is made on the data set to plot the data and perform a log transform – this way, changes are not retained in the original, raw data file.
- Analysis “scripted” software: R, SAS, SPSS, Matlab Analysis scripts are written records of the various steps involved in processing and analyzing data (sort of “analytical metadata”). Easily revised and re-executed at any time if needs to modify analysis VS. GUI (easier) but does not leave a clear accounting of exactly what you have done Document scripted code with comments on why data is being changed. The scripts you have written are an excellent record of data processing, they can also easily and quickly be revised and rerun in the event of data loss or requests for edits, and have the added benefit of allowing a future worker to follow-up or reproduce your processing. Keep in mind that while GUI-based programs are easy on the front end, they do not keep a record of changes to your data and make reproducing results difficult.
- Metadata and associated documentation is absolutely crucial for any potential use or reuse of data; no one can responsibly re-use or interpret data without accompanying compliant and standardized metadata or documentation. Metadata describe your data so that others can understand what your data set represents; they are thought of as "data about the data" or the "who, what, where, when, and why" of the data. Metadata should be written from the standpoint of someone reading it who is unfamiliar with your project, methods, or observations. What does a user, 20 years into the future, need to know to use your data properly? Informal something like a ReadMe file. Formal is use of a structured like a data dictionary, codebook, or metadata. Different disciplines may have format standards. Informal is better than nothing
- More documentation: Documentation can also be called metadata Description of the data file names (especially if using acronyms and abbreviations). Record why you are collecting data, Details of methods of analysis Names of all data and analysis files Definitions for data (include coding keys) Missing value codes Unit of measures. Structured metadata (XML) format standards for discipline (Ecological Metadata language – EML)
- Here the data dictionary specifies units for each field (parameter)
- In fact, you probably already have metadata in some form. You just may not recognize it as such. For instance, among your work records, you certainly have notebooks stuffed with color-coded pages or assorted keys to your data stored on your computer. Perhaps the most common form of metadata that you may already have is a file folder filled with notes on your data sources and the procedures that you used to build your data. However, unless you’ve been unusually diligent, your information is probably not organized so that a stranger could stroll into your office at any time, and read and understand it easily. Start at the beginning of the project and continue throughout data collection & analysis Why you are collecting data Exact details of methods of collecting & analyzing Good for reproducability. Some of the issues include reproducibility of science that you can go back when questioned or when updating your results, and reproduce the algorithms. There’s also efficiencies in how the science is done. If you have to spend a lot of time figuring out what was done last time you are losing some efficiencies in reproducing those results or updating analysis. Along the line of those efficiencies is sharing across groups. Much of the work we do nowadays is collaborative, involves more than one agency or university or partner and if you can document the data and the analysis it helps to share the information and have everyone in that collaborative team understand what’s being done. We also, like documenting the data and the analysis create a provenance that gives a full history of when the project was started how the analysis was done and how the final results were completed.
- Collection/Analysis format does not have to be the same as Preservation format, but if not, then it will need to be converted (interchangeable format – will talk about this later) for archiving Want to choose a file format that can be read well into the future and is independent of software changes. Fundamental Practice #3: Use stable file formats Data re-use depends on the ability to return to a dataset, perhaps long after the proprietary software you used to develop it, is available. Remember floppy disks? It is difficult to find a computer that will read a floppy disk today. We must think of digital data in a similar way. Select a consistent format that can be read well into the future and is independent of changes in applications. If your data collection process used proprietary file formats, converting those files into a stable, well-documented, and non-proprietary format to maximize others' abilities to use and build upon your data is a best practice. When possible, convert your tabular dataset into ASCII text format. To be accessible in the future: Non-proprietary Open, documented standard Common, used by the research community Standard representation (ASCII, Unicode) Unencrypted Uncompressed
- Storing data in recommended formats with detailed documentation will allow your data to be easily read many years into the future. Spreadsheets are widely used for simple analyses But they have poor archival qualities Different versions over time are not compatible Formulas are hard to capture or display Plan what type of data you will be collecting. Want to choose a file format that can be read well into the future and is independent of software changes. These are formats more likely to be accessible in the future. to replace old media, maintaining devices that can still read the proprietary formats or media type Format of the file is a major factor in the ability to use the data in the future. As technology changes, plan for software and hardware obsolescence. System files (SAS, SPSS) are compact and efficient, but not very portable. Use software to “export” data to a portable (or transport) file. Convert proprietary formats to non-proprietary. Check for data errors in conversion.
- Remember create spreadsheet so it can be automated Date/Time standards, Geospatial coords, Species, other standards from discipline Descriptive File Names – File names can help id what’ inside Quality Assurance – when planning on data entry can “program” data checks in forms (Access and Excel), create pick lists (codes), missing data values Make it easier to replicate data transformation, can be documented Document EVERYTHING, dataset details, database details, collection notes – conditions, You will not remember everything 20 years from now! What someone would need to know about your data to use it. Stable File Formats – easier if all files were same format, also knowing what formats are better in the long-term
- Planning the management of your data before you begin your research AND throughout its lifecycle is essential to ensure its current usability & long-term preservation and access. With a repository keeping your data, you can focus on your research rather than fielding requests or worrying about data on a web page. Your project may have lots of people working on it, you will need to know what each is doing and has done. Project may last years. Funding agencies now require a data management plan Having your data documented will allow future users understand your data and be able to use it. If follow plan then data should be ready for archiving (documenting the data throughout) insures proper description of the data are maintained.
- Collecting the data is just part of a research project. Here’s a view of the complete life cycle of research. The data you collect (all the files, notes) need to be managed throughout the project. Steps in the Research Life Cycle: Proposal Planning & Writing: Conduct a review of existing data sets Determine if project will produce a new dataset (or combing existing) Investigate archiving challenges, consent and confidentiality Id potential users of your data Determine costs related to archiving Contact Archives for advice (Look for archives) Project Start Up Create a data management plan Make decisions about document form and content Conduct pretest & tests of materials and methods Data Collection Follow Best Practice Organize files, backups & storage, QA for data collection Access Control and Security Data Analysis Manage file versions Document analysis and file manipulations Data Sharing Determine file formats Contact Archive for advice More documenting and cleaning up data End of Project Write Paper Submit Report Findings Deposit Data in Data Archive (Repository) Remember: Managing Data in a research project is a process that runs throughout the project. Good data management is the foundation for good research. Especially if you are going to share your data. Good management is essential to ensure that data can be preserved and remain accessible I the long-term, so it can be re-used and understood by other researchers. When managed and preserved properly research data can be successfully used for future scientific purposes.
- Here’s the details about what we are going to manage in the Data Life Cycle. Many of the criteria for managing data are the best practices that we already went over. The 2 highlighted we haven’t talked about yet.
- Keep master copy to an assigned team member Restrict write access to specific members Record changes with Version control Network: keep confidential data off internet servers (or behind firewalls), put sensitive materials on computers not connected to the internet Physical security… who has access to your office,. Allowing repairs by an outside company Computer: Keep virus protection up to date, does your computer have a login password, not sending personal or confidential data via e-mail or FTP, transmit via encrypted data, imposing confidentially agreements for data users
- Why backup data? Keeping reliable backups is an integral part of data management. Regular back-ups protect against data loss due to: Hardware failure, software of media faults, virus infection or hacking, power failure, human errors Recommendation, 3 backup copies original, external/local, external/remote Full-backups, incremental If using departmental server, check on backup/restore procedures (how quickly can you get files restored?) May want to have the backup procedures controlled by you. Test your backup system, test restoring files, don’t over re-use backup media
- There are a variety of alternative methods to store and share your data - from thumb drives to shared online environments. Personal Computer Departmental or University Server Home Directory or UVa Collab (Storage only) Tape Backups Subject Archive Each type of storage (can’t forget backups) has their strengths and weaknesses. You need to be able to evaluate them for your research.
- Point… to think about migrating information from obsolete media to new media. Using CD-Roms as data backups is popular. Blank CDs are inexpensive, and copying data onto CDs is easy. However, this is the most unreliable method of all the data backup methods listed here. Who hasn't had the experience of putting a CD into a drive only to find that the data is unreadable and the disk "doesn't work"? CDs, like the floppy disks they've replaced, have a limited shelf life. If you are writing your data backup files onto CDs, make sure that you make (and keep) multiple copies over time. external hard drive for data backups is recommended. External hard drives are relatively cheap. They’re also easy to use; in many cases, all you have to do is plug the hard drive into your computer’s USB port. And while hard drives do fail, their failure rate is much lower than that of backup media such as CDs. Cloud Storage for-fee or free for up to 10G (storage costs, data transfer)