Download to read offline

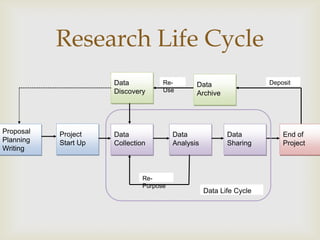
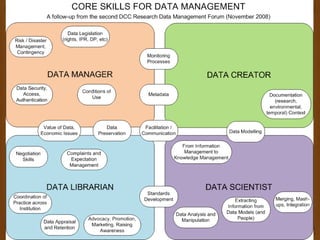
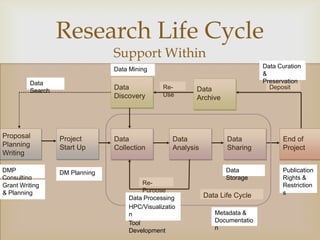






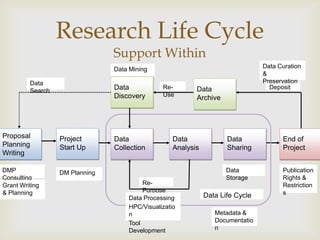


This document summarizes a workshop on data management. It outlines the typical research lifecycle including proposal planning, project start up, data collection, analysis, sharing, and end of project. It discusses support for researchers within areas like data mining, curation, and preservation. It also discusses support from outside through infrastructure, policy, and best practices. Finally, it identifies 9 key skills gaps for librarians in advising researchers on data management tasks.



































































