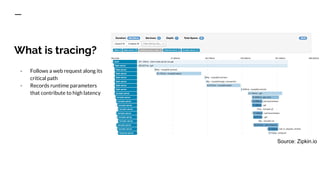
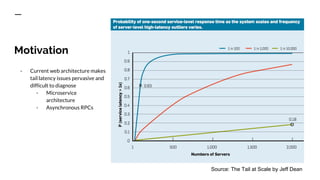
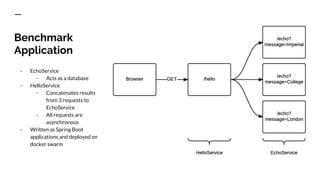
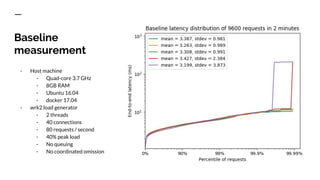
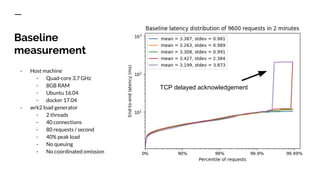
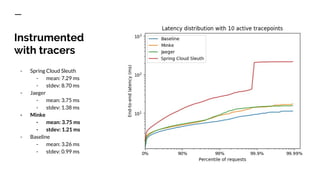
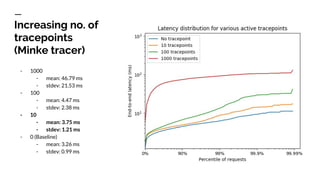
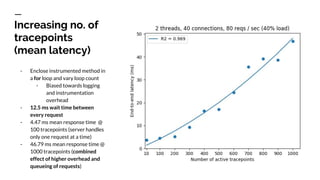
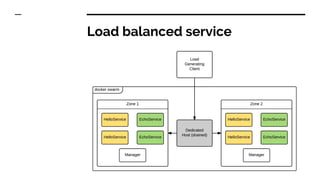
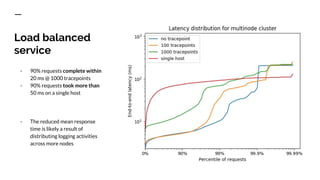
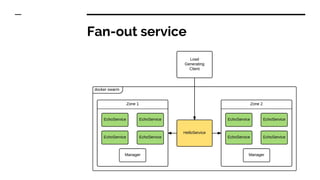
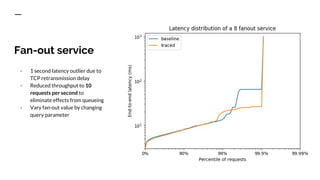
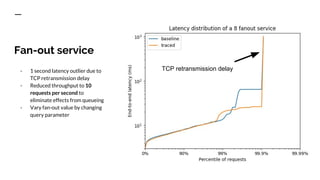
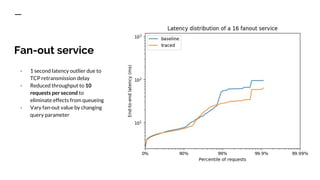
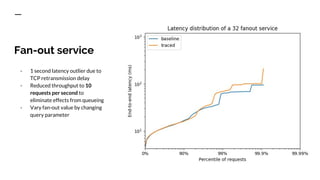
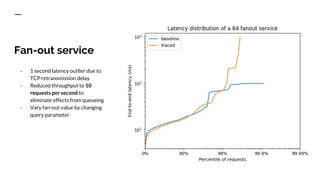
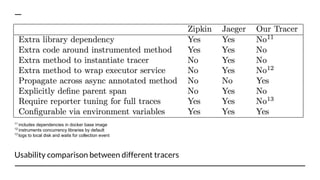
The document discusses benchmarking distributed tracers in the context of web request tracing and latency challenges faced in microservice architectures. It details the methodology for measuring instrumentation overhead and compares different tracers (Spring Cloud Sleuth, Jaeger, Minke) with varying numbers of tracepoints in performance metrics. The results indicate that the choice of tracer and configuration significantly impacts latency and throughput, with specific conditions noted for load balanced and fan-out services.