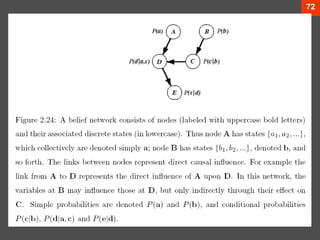
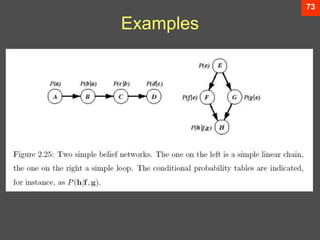
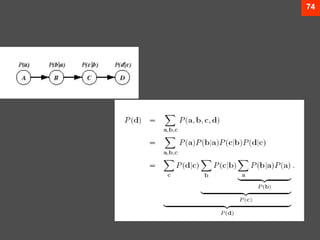
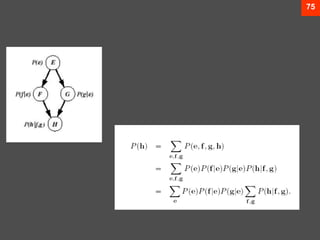
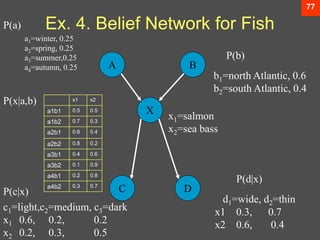
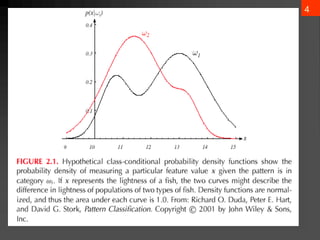
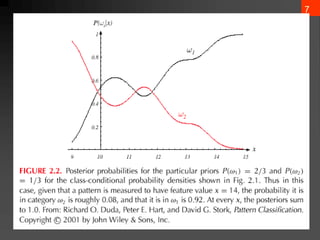
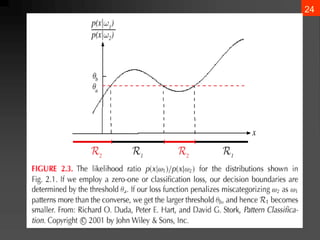
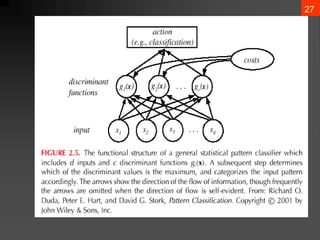
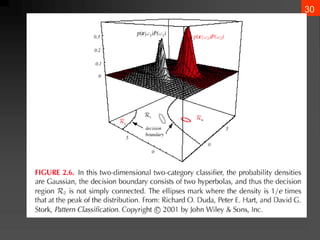
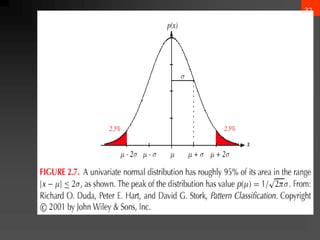
The document discusses Bayesian decision theory, focusing on its application in machine learning for classification tasks. It covers concepts such as minimum-error-rate classification, decision rules based on posterior probabilities, and the use of loss functions to guide decision-making under uncertainty. Additionally, it explores the mathematical formulations for discriminant functions and the properties of normal density in relation to classification problems.






![8
• Decision given the posterior probabilities
X is an observation for which:
if P(1 | x) > P(2 | x) True state of nature = 1
if P(1 | x) < P(2 | x) True state of nature = 2
This rule minimizes average probability of error:
𝑃 ⅇ𝑟𝑟𝑜𝑟 =
−∞
∞
𝑝 ⅇ𝑟𝑟𝑜𝑟, 𝑥 ⅆ𝑥 =
−∞
∞
𝑝 ⅇ𝑟𝑟𝑜𝑟 𝑥 𝑝 𝑥 𝑑𝑥
p ⅇ𝑟𝑟𝑜𝑟 𝑥 = min[P(1 | x), P(2 | x) ]
Decide 1 if P(x | 1) P (1) > P(x | 2) P (2)](https://image.slidesharecdn.com/bayesiandecisiontheory1-240611161444-ca74f061/85/Bayesian-Decision-Theory-details-ML-pptx-9-320.jpg)







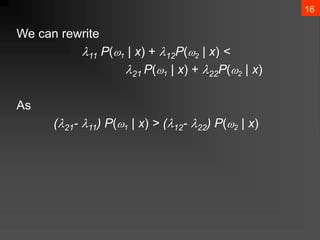













![34
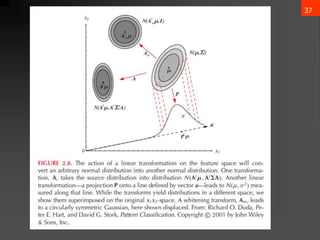
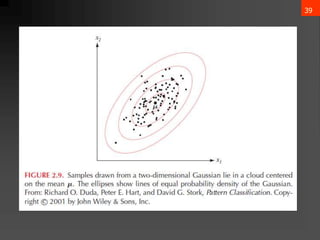
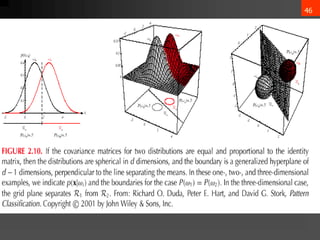
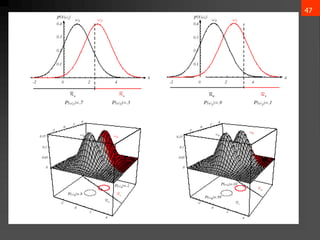
𝜇 = 𝜀[x] = x𝑝(x)𝑑x
∑ = 𝜀[(x−𝜇)(x−𝜇)t] = (x−𝜇)(x−𝜇)t𝑝(x)𝑑x
𝜇𝑖 = 𝜀[𝑥𝑖]
𝜎𝑖𝑗 = 𝜀[(𝑥𝑖 − 𝜇𝑖)(𝑥𝑗 − 𝜇𝑗)]](https://image.slidesharecdn.com/bayesiandecisiontheory1-240611161444-ca74f061/85/Bayesian-Decision-Theory-details-ML-pptx-35-320.jpg)









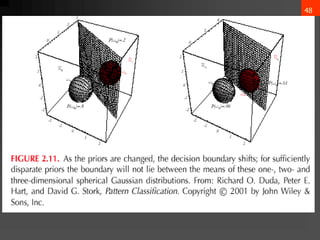



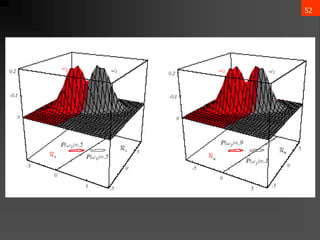
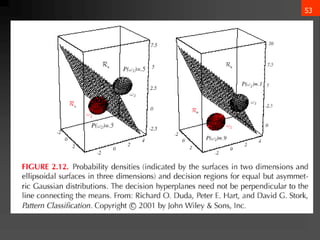
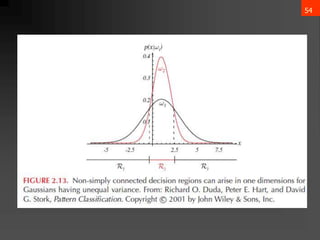

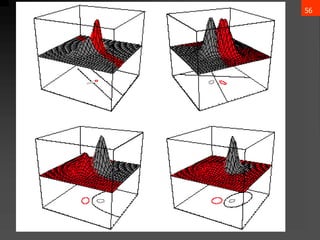
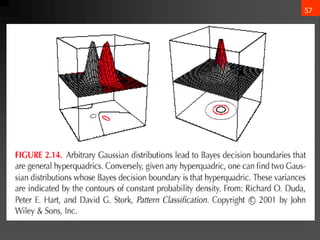
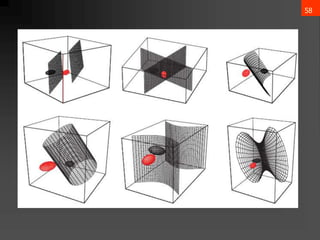
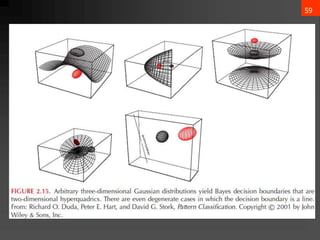




![65
Bayes Decision Theory – Discrete
Features
• Case of independent binary features in 2
category problem
Let x = [x1, x2, …, xd ]t where each xi is either 0
or 1, with probabilities:
pi = P(xi = 1 | 1)
qi = P(xi = 1 | 2)](https://image.slidesharecdn.com/bayesiandecisiontheory1-240611161444-ca74f061/85/Bayesian-Decision-Theory-details-ML-pptx-66-320.jpg)