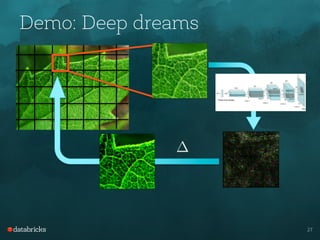
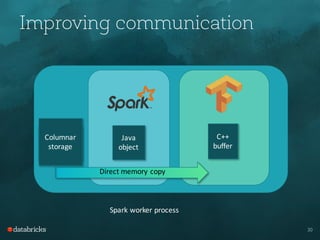
Tim Hunter presented on TensorFrames, which allows users to run TensorFlow models on Apache Spark. Some key points:
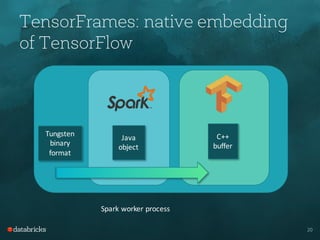
- TensorFrames embeds TensorFlow computations into Spark's execution engine to enable distributed deep learning across a Spark cluster.
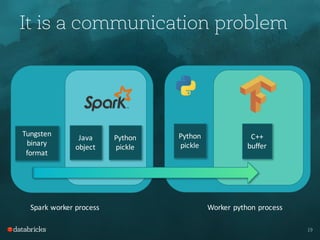
- It offers performance improvements over other options like Scala UDFs by avoiding serialization and using direct memory copies between processes.
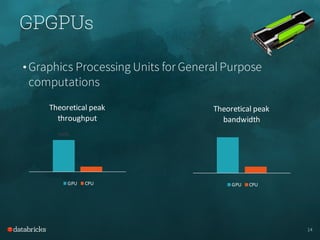
- The demo showed how TensorFrames can leverage GPUs both on Databricks clusters and locally to accelerate numerical workloads like kernel density estimation and deep dream generation.
- Future work includes better integration with Tungsten and MLlib data types as well as official GPU support on Databricks clusters. TensorFrames aims to provide a simple API for













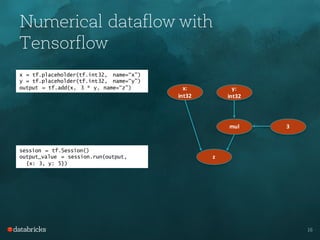
![Numerical dataflow with Spark
df = sqlContext.createDataFrame(…)
x = tf.placeholder(tf.int32, name=“x”)
y = tf.placeholder(tf.int32, name=“y”)
output = tf.add(x, 3 * y, name=“z”)
output_df = tfs.map_rows(output, df)
output_df.collect()
df: DataFrame[x: int, y: int]
output_df:
DataFrame[x: int, y: int, z: int]
x:
int32
y:
int32
mul 3
z](https://image.slidesharecdn.com/2016-06-03sparkmeetuptensorframes-160608003223/85/Spark-Meetup-TensorFrames-17-320.jpg)



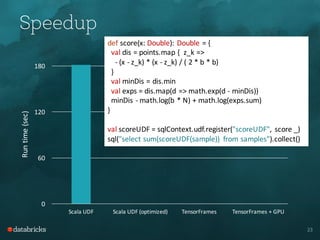

varidx = 0
while(idx < N) {
val z_k = points(idx)
dis(idx) = - (x - z_k) * (x - z_k) / ( 2 * b * b)
idx += 1
}
val minDis = dis.min
varexpSum = 0.0
idx = 0
while(idx < N) {
expSum += math.exp(dis(idx) - minDis)
idx += 1
}
minDis - math.log(b * N) + math.log(expSum)
}
val scoreUDF = sqlContext.udf.register("scoreUDF", score _)
sql("select sum(scoreUDF(sample)) from samples").collect()](https://image.slidesharecdn.com/2016-06-03sparkmeetuptensorframes-160608003223/85/Spark-Meetup-TensorFrames-24-320.jpg)