Download to read offline
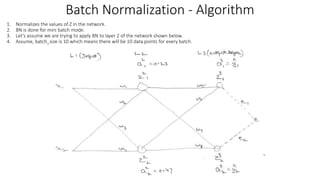
![1. Training - Batch 1:
1. z_vector –
1. For sample 1 in batch 1, the z vector is [z_2_1,
z_2_2………..z_2_5]
2. Same z vector is computed for all sample ranging
from sample 1 till 10 in batch 1.
2. z_normalized_vector – znorm
1. The z values of across all samples in batch are
standardized to make z_normalized_vector.
2. Even though we say normalization, we are doing
standardization of z values. Normalization is done to
restrict the values of data in range 0 – 1.
Standardization converts data into distribution with
mean 0 and S.D of 1.
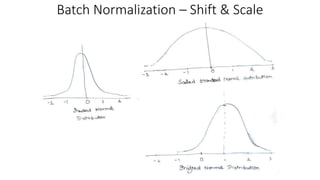
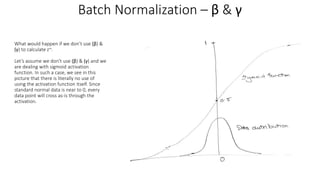
3. z_tilda – z~ = ((gamma* z_normalized_vector) + beta)
1. gamma is the scale and beta is the shift.
2. The concept behind gamma and beta – While
converting z_vector into a z_normalized_vector, we
assume that z follows standard normal distribution.
It may not be the case always. To account for other
scenarios, we scale (γ) the data which essentially
means distribute the data and then shift (β) the data
which essentially means move the data across scale.
Batch Normalization – Normalizing z](https://image.slidesharecdn.com/batchnormalization-230207113554-b7ce383e/85/Batch-Normalization-2-320.jpg)




1. Batch normalization normalizes the activations in a network on a mini-batch basis. It standardizes the inputs to each layer by subtracting the batch mean and dividing by the batch standard deviation. 2. During training, the batch mean and variance are used to normalize the activations for each batch. Additionally, a scale gamma and shift beta are learned to scale and shift the normalized values. 3. At test time, the mean and variance of the entire training dataset are used for normalization instead of the batch statistics. This prevents dependency on batch size at test time.


































































