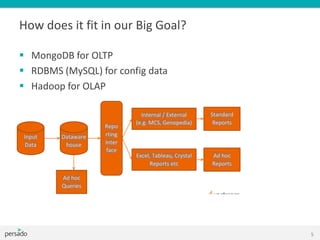
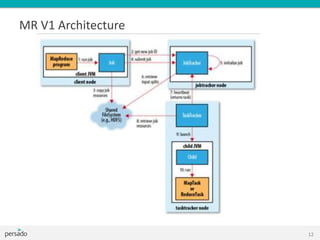
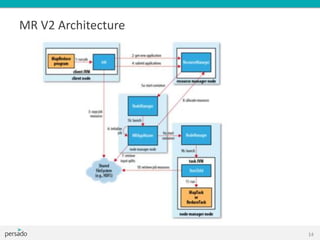
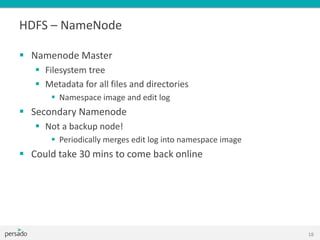
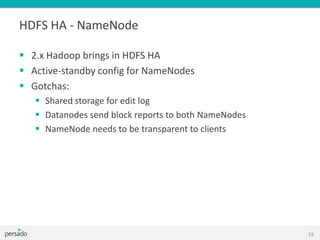
This document provides an overview of Hadoop and big data training. It introduces Cloudera as a leading Hadoop distribution company. It describes why Hadoop training is useful when large amounts of data need advanced analysis beyond the capabilities of MongoDB. The intended audience is software engineers. The document then explains what Hadoop is, how it fits with other technologies like MongoDB and MySQL, and how MapReduce works in Hadoop. It covers Hadoop architecture, HDFS, data locality, and the Hadoop ecosystem including tools like Pig, Hive, and Mahout.








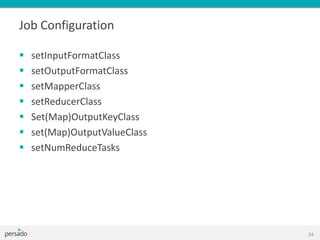
![Job Configuration
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
OR job.submit();
25](https://image.slidesharecdn.com/hadoopandbigdatatraining-130615235142-phpapp01/85/Hadoop-and-big-data-training-26-320.jpg)
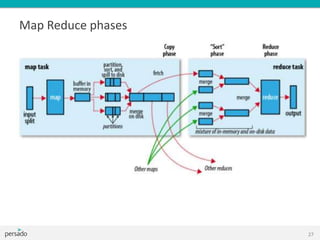
![Shuffle and Sort
All same keys are guaranteed to end up in the same reducer,
sorted by key
Mapper output <K2,V2><‘the’,1>, <‘the’,2>, <‘cat’,1>
Reducer input <K2,[V2]><‘cat’,*1+>, <‘the’,*1,2+>
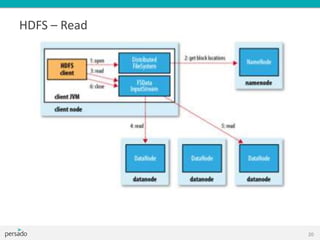
29](https://image.slidesharecdn.com/hadoopandbigdatatraining-130615235142-phpapp01/85/Hadoop-and-big-data-training-30-320.jpg)
![Reducer – Life cycle
Reducer inputs <K2, [V2]> outputs <K3, V3>
30](https://image.slidesharecdn.com/hadoopandbigdatatraining-130615235142-phpapp01/85/Hadoop-and-big-data-training-31-320.jpg)

































































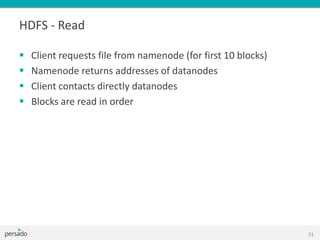
![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










