Download as PDF, PPTX






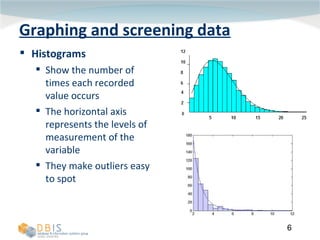

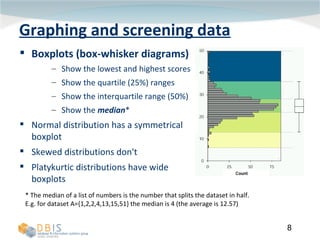
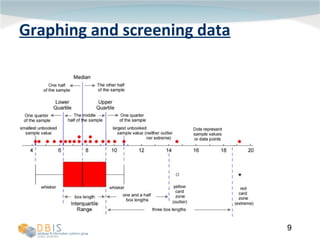

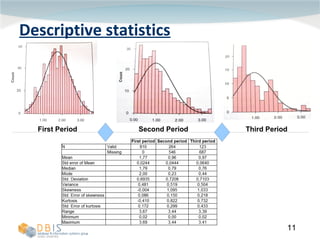



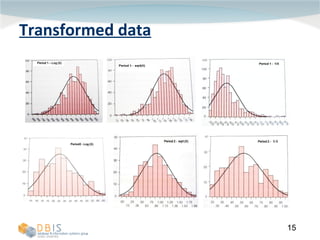

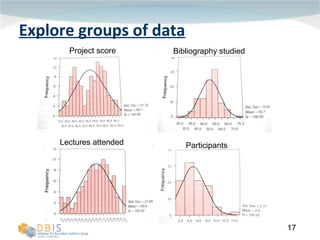
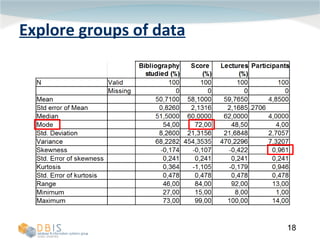

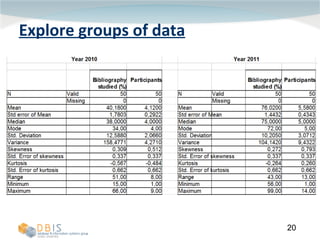






This document discusses exploring and representing data properties through statistical analysis techniques. It covers topics like descriptive statistics, graphical representations of data through histograms and boxplots, testing for normality and homogeneity of variance, and exploring differences between groups of data. The goal is to properly examine data distributions and assumptions before conducting further statistical tests and analysis.






























































































