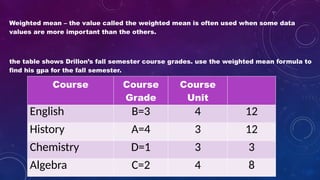
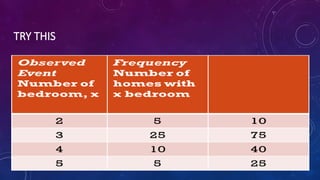
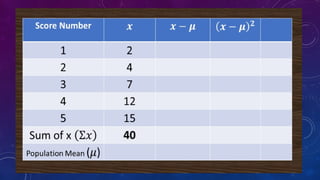
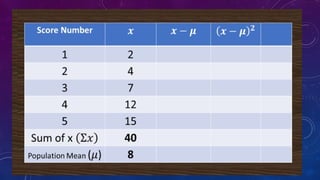
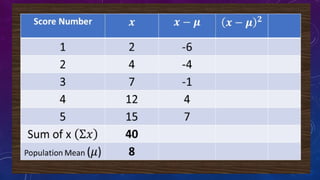
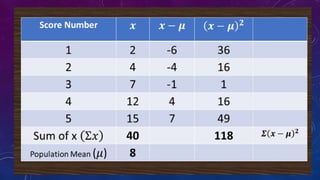
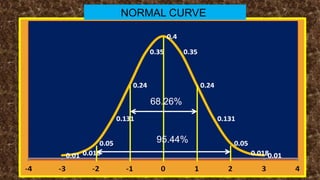
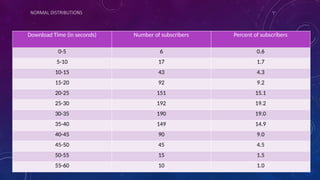
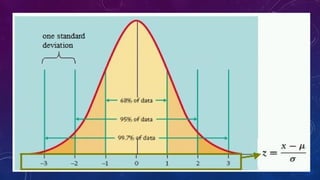
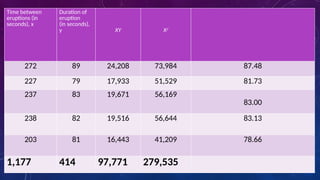
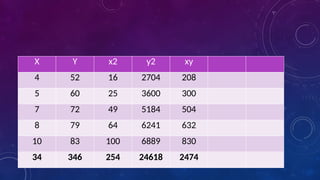
The document details measures of central tendency including mean, median, and mode, along with advanced topics such as weighted mean, z-scores, and percentiles. It also explains visual data representations like box-and-whisker plots and stem-and-leaf diagrams, and covers properties of normal distributions, probability calculations, and linear regression. Additionally, it discusses correlation coefficients to determine relationships between variables, emphasizing that correlation does not imply causation.