Downloaded 210 times







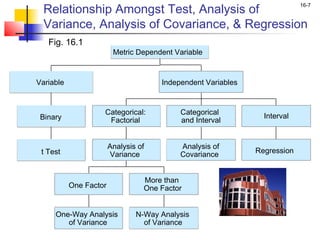












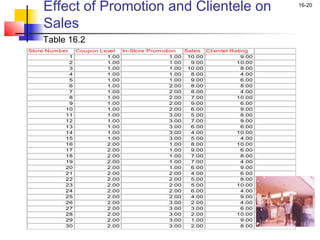
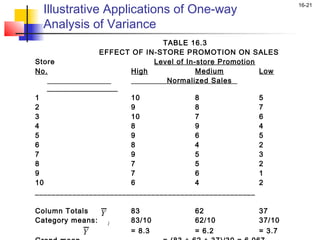




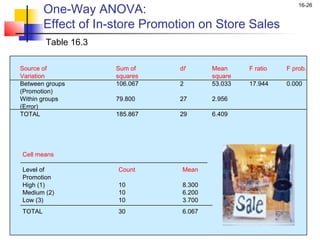






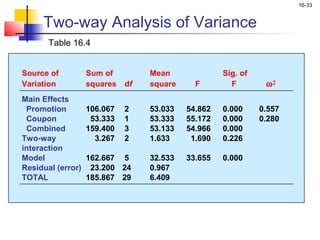
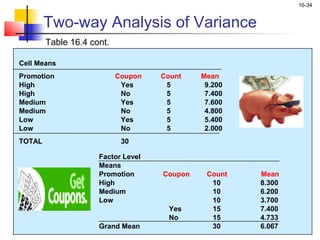

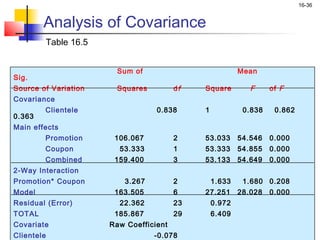

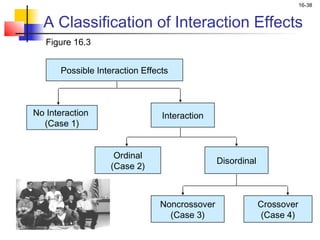
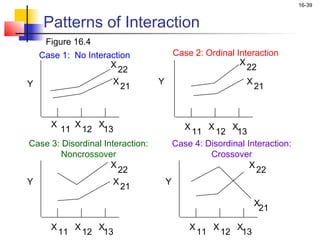













This chapter outline describes one-way analysis of variance (ANOVA). It introduces key concepts like decomposing total variation into between- and within-group components to test if group means are equal. The chapter will cover conducting a one-way ANOVA, including identifying variables, decomposing variation, measuring effects with statistics like η2, testing significance with the F-ratio, and interpreting results. Examples and assumptions of one-way ANOVA will also be discussed.





































































