Download to read offline


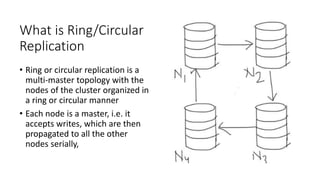








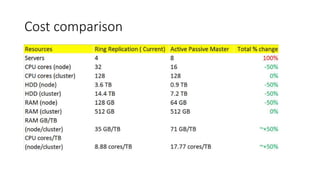




Ring or circular replication is not recommended for high availability and scalability in MySQL. It can cause multiple points of failure if a node goes down, negatively impacting the whole system. It also does not actually provide high write or read scalability as the load is spread across all nodes. The solution proposed is to use an active-passive multi-master setup with sharding to split the data across nodes, providing independent backups for portions of the system while avoiding the issues of the ring topology.



































































