Download to read offline






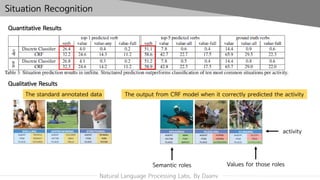


The document discusses a method for summarizing situations depicted in images using natural language processing, focusing on main activities, participating objects, and their roles. It outlines a formal task definition with examples and mentions the use of a dataset called imsitu for training models, achieving high accuracy in verb and semantic role predictions. The techniques involve using systems like CRF with features from Imagenet and Wordnet to enhance performance in recognizing activities and objects.
























































