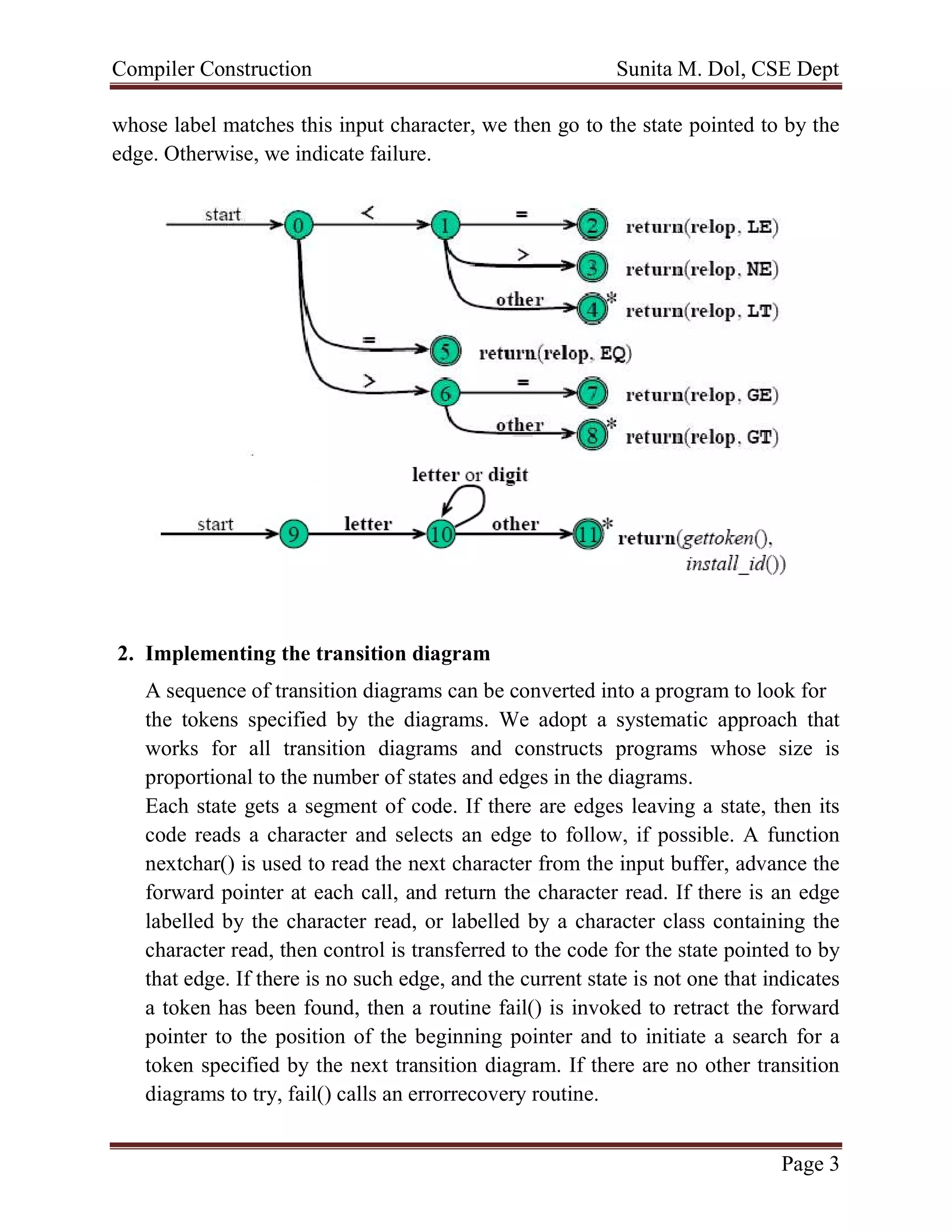
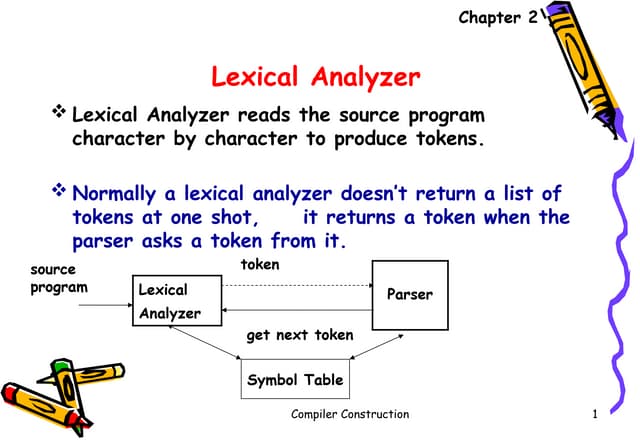
1) The document describes implementing a lexical analyzer to recognize tokens based on a given transition diagram.
2) A transition diagram depicts the states and transitions between states based on input characters. Each state is implemented as a code segment.
3) The lexical analyzer uses functions like nextchar() to read input and follow transitions between states based on the character. It returns tokens by assigning values to a global variable.