Downloaded 28 times


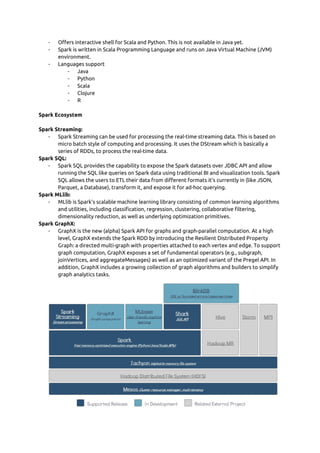




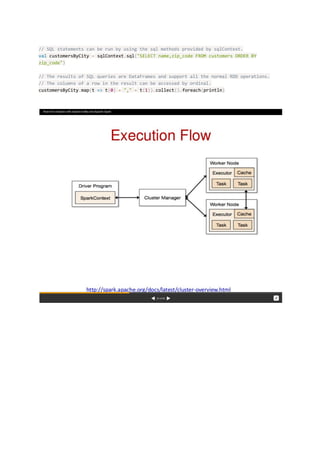






Spark is an open source cluster computing framework that allows processing of large datasets across clusters of computers using a simple programming model. It provides high-level APIs in Scala, Java, Python and R for building parallel applications. Spark features include in-memory computing, lazy evaluation, and support for streaming, SQL, machine learning and graph processing. The core of Spark is the Resilient Distributed Dataset (RDD) which allows data to be partitioned across nodes in a cluster and supports parallel operations.









































































