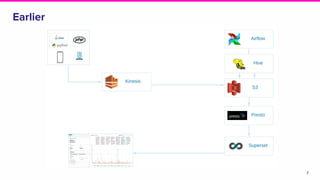
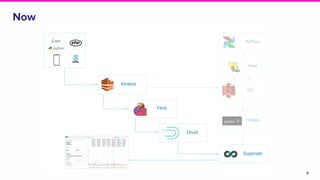
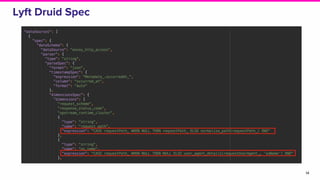
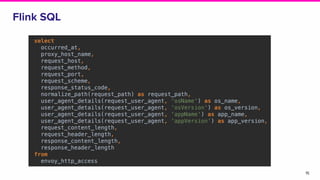
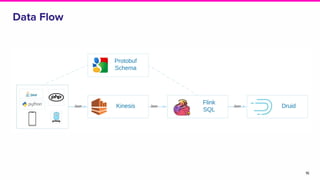
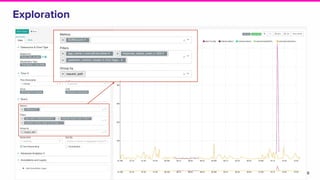
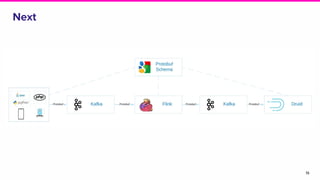
This document discusses the integration of streaming SQL and Druid architecture used at Lyft for real-time data processing and analysis. It highlights use cases, access methods, and the technical framework involving Apache Flink and Druid, while addressing the challenges and requirements for data freshness and query latency. The conclusion emphasizes the importance of an easy-to-use ingestion framework and the potential for augmented capabilities through Flink streaming SQL.





















![[WSO2Con USA 2018] Deploying Applications in K8S and Docker](https://cdn.slidesharecdn.com/ss_thumbnails/deployingapplicationsink8sanddocker-wso2conusa2018-180723073457-thumbnail.jpg?width=640&height=640&fit=bounds)























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)






