










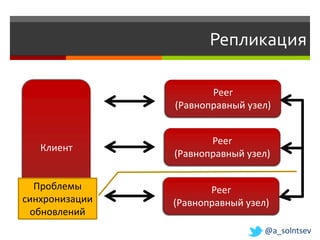





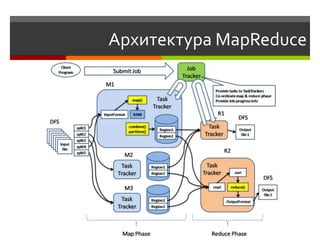
![Инкрементальная масштабируемость
W A
(T,W] (W,A]
Узлы объединены в кольцо
Все знают о всех
(L,T] (A, L]
T L
@a_solntsev](https://image.slidesharecdn.com/nosql-slideshare-120417072405-phpapp02/85/NoSQL-26-320.jpg)
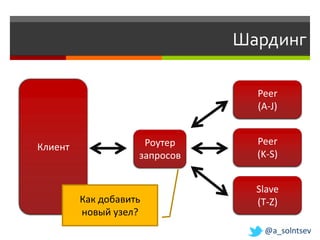
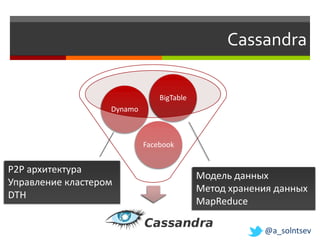
![Инкрементальная масштабируемость
W A
Пересчёт
(A, F]
k/n ключей F
(F L]
,
T L
@a_solntsev](https://image.slidesharecdn.com/nosql-slideshare-120417072405-phpapp02/85/NoSQL-27-320.jpg)



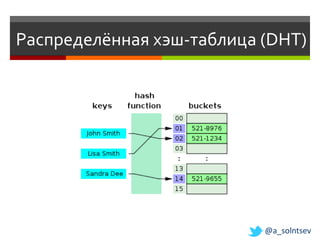
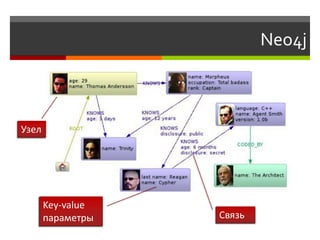
![Формат документов
{
"_id" : ObjectId("497ce96f395f2f052a494fd4"),
"title" : "Awesome Blog Post",
"body" : "Text text text text, text text text ...",
"created": "Tue, 3 Jan 2011 11:13:56 GMT",
"tags" : [ "css", "javascipt", "jquery" ],
"comments" : [
{
"name" : "Kelly Glover"
"created" : "Tue, 22 Jan 2011 2:22:32 GMT",
"text" : "This is a very good ..."
},
],
"shortUrl" : "awesome-blog-post"
}](https://image.slidesharecdn.com/nosql-slideshare-120417072405-phpapp02/85/NoSQL-37-320.jpg)






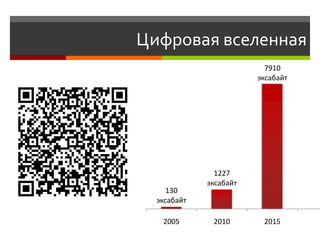
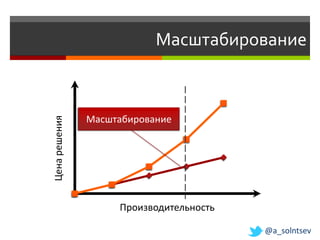
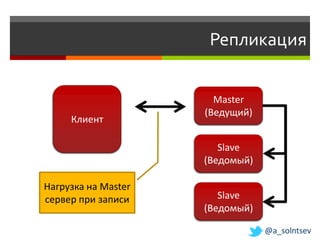
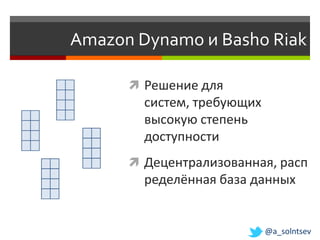
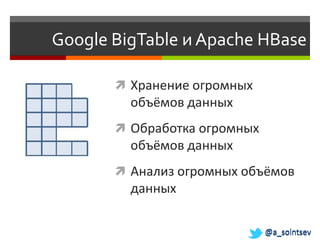
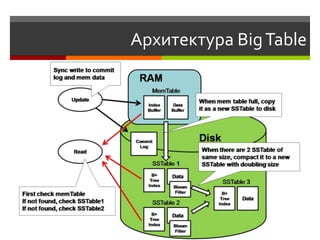
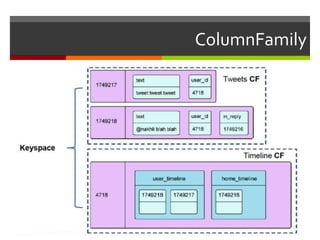
Документ обсуждает возможности и проблемы NoSQL баз данных, подчеркивая их развитие с 70-х и современные вызовы в связи с объемами и структурой данных. Автор, Алексей Солнцев, представляет различные типы NoSQL баз, такие как документ-ориентированные и граф-ориентированные, а также рассматривает вопросы масштабирования и согласованности. Он также подчеркивает важность сообществ и взаимодействия в мире IT при работе с новыми технологиями.



















































































