Download to read offline





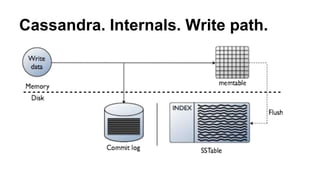
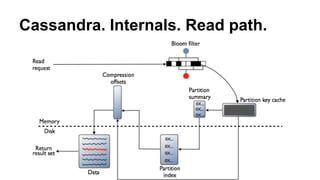


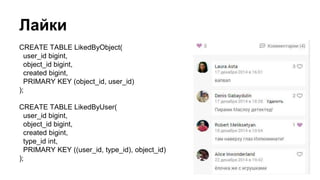


















Доклад о Cassandra предназначен для разработчиков, знакомых с системой, и охватывает ее внутреннее устройство, включая механизмы записи и чтения, а также сильные и слабые стороны. Обсуждаются ключевые вопросы проектирования, включая выбор partition key и влияние на производительность, а также способы работы с лайками и уведомлениями. Особое внимание уделяется стратегиям удаления данных и рекомендациям по оптимизации запросов.












































