Download to read offline



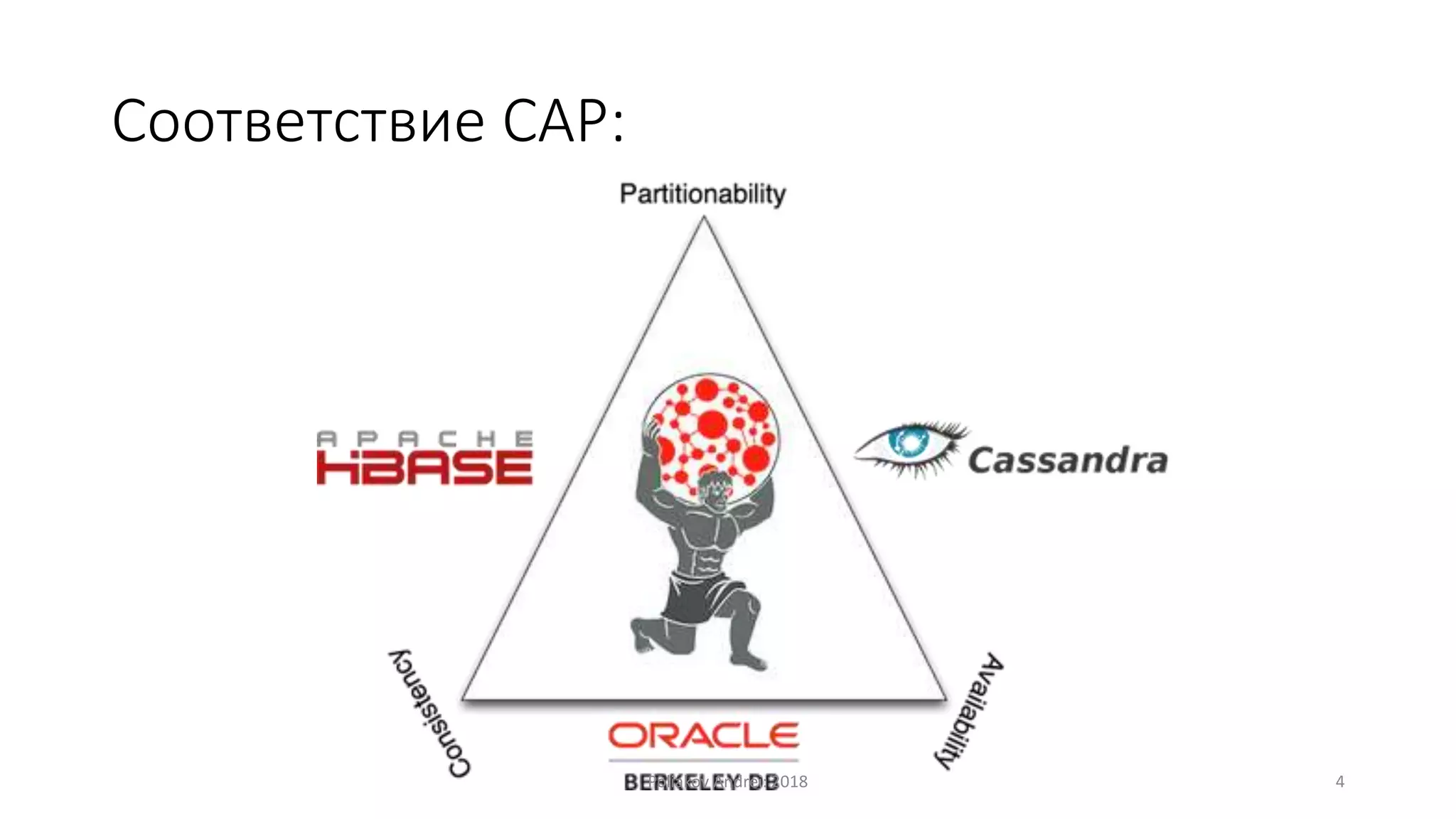




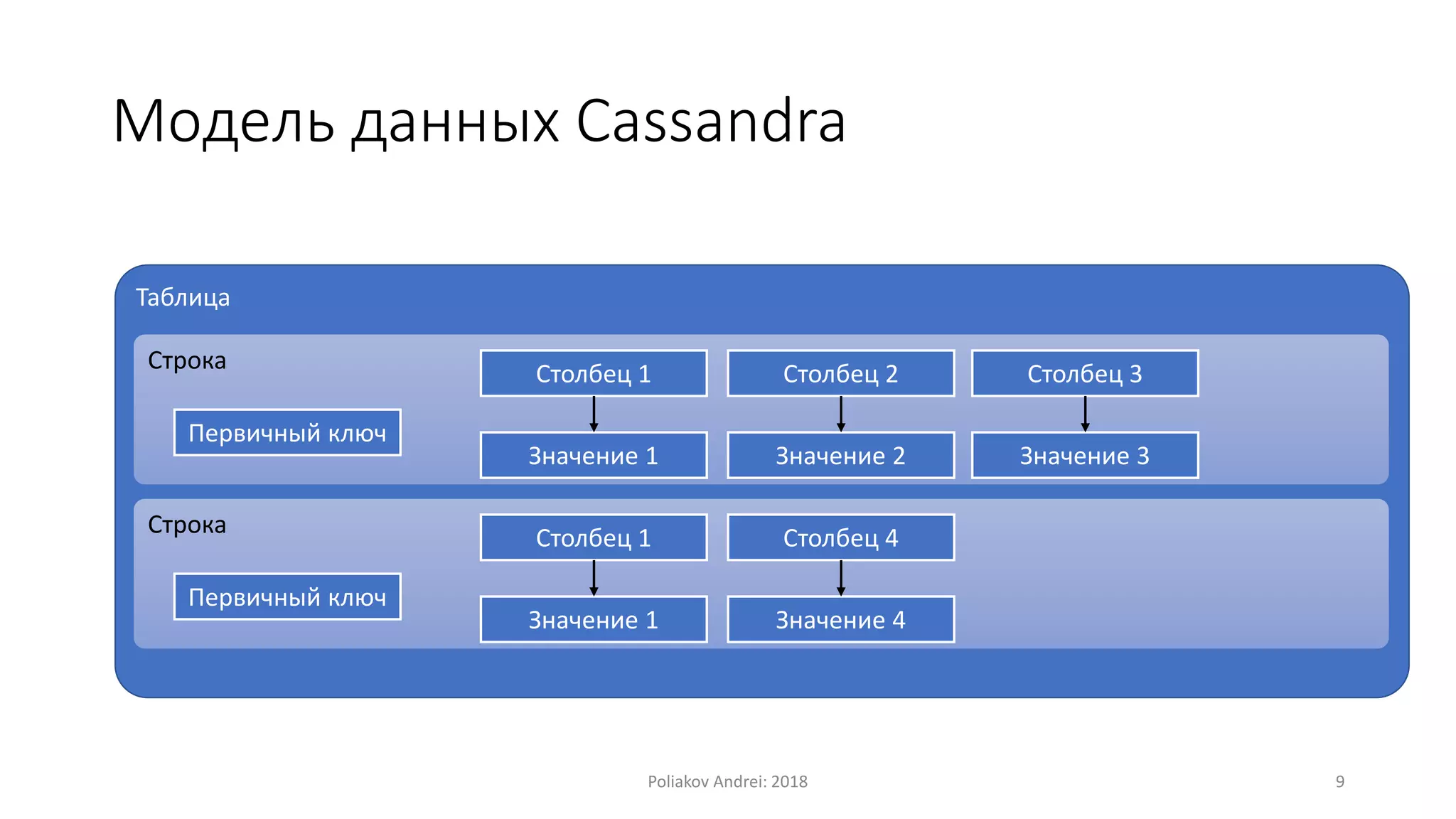
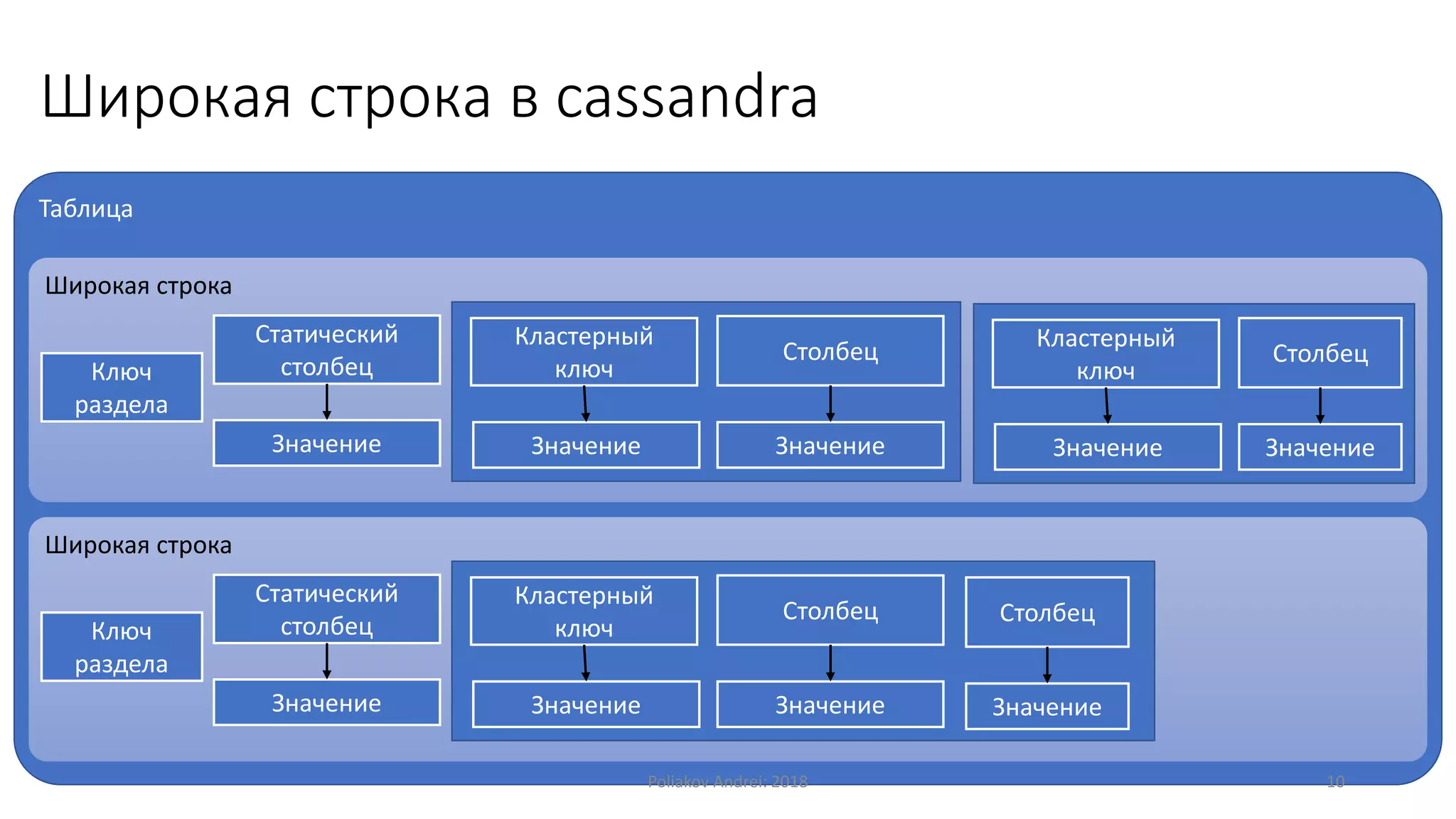
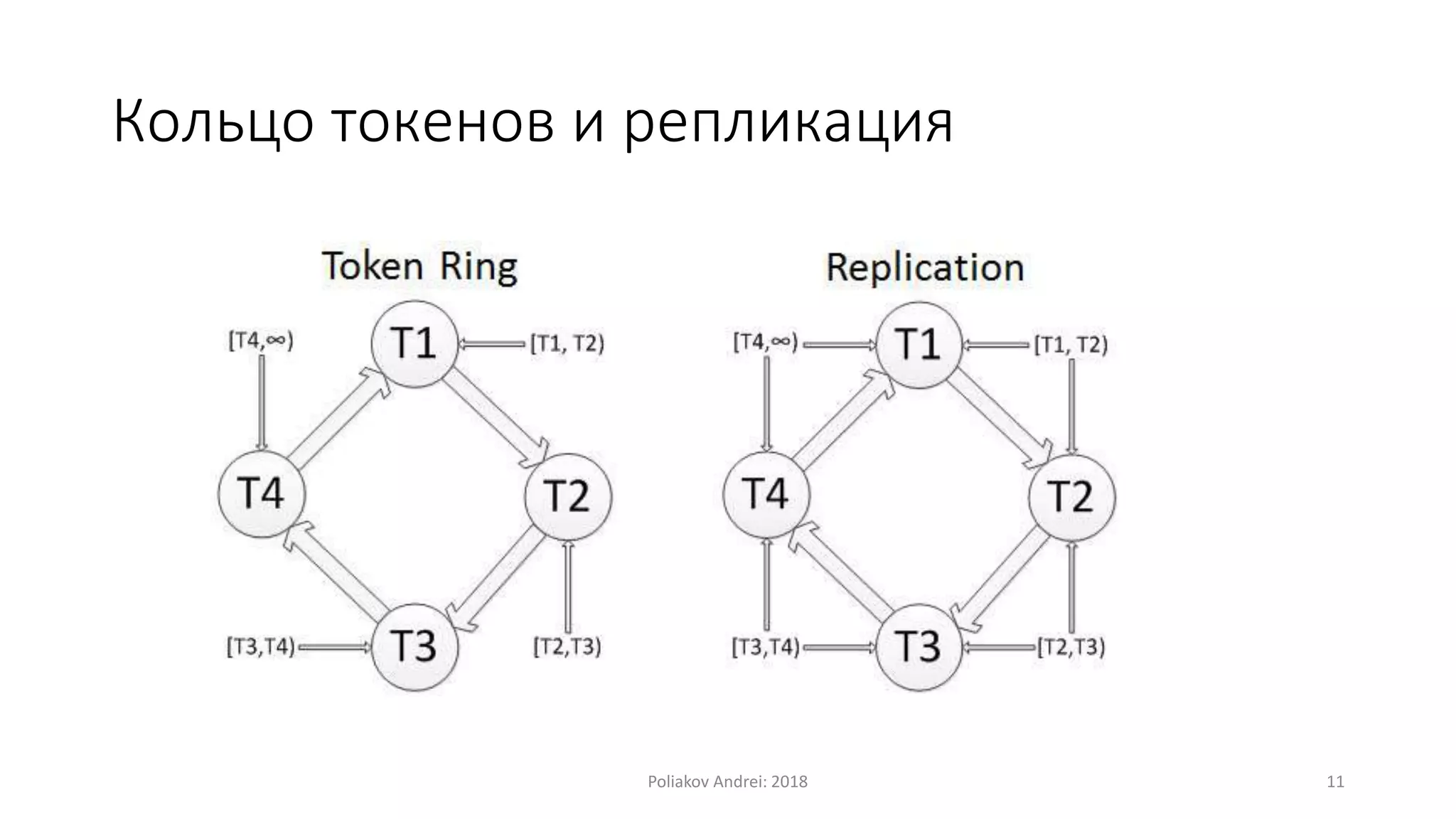

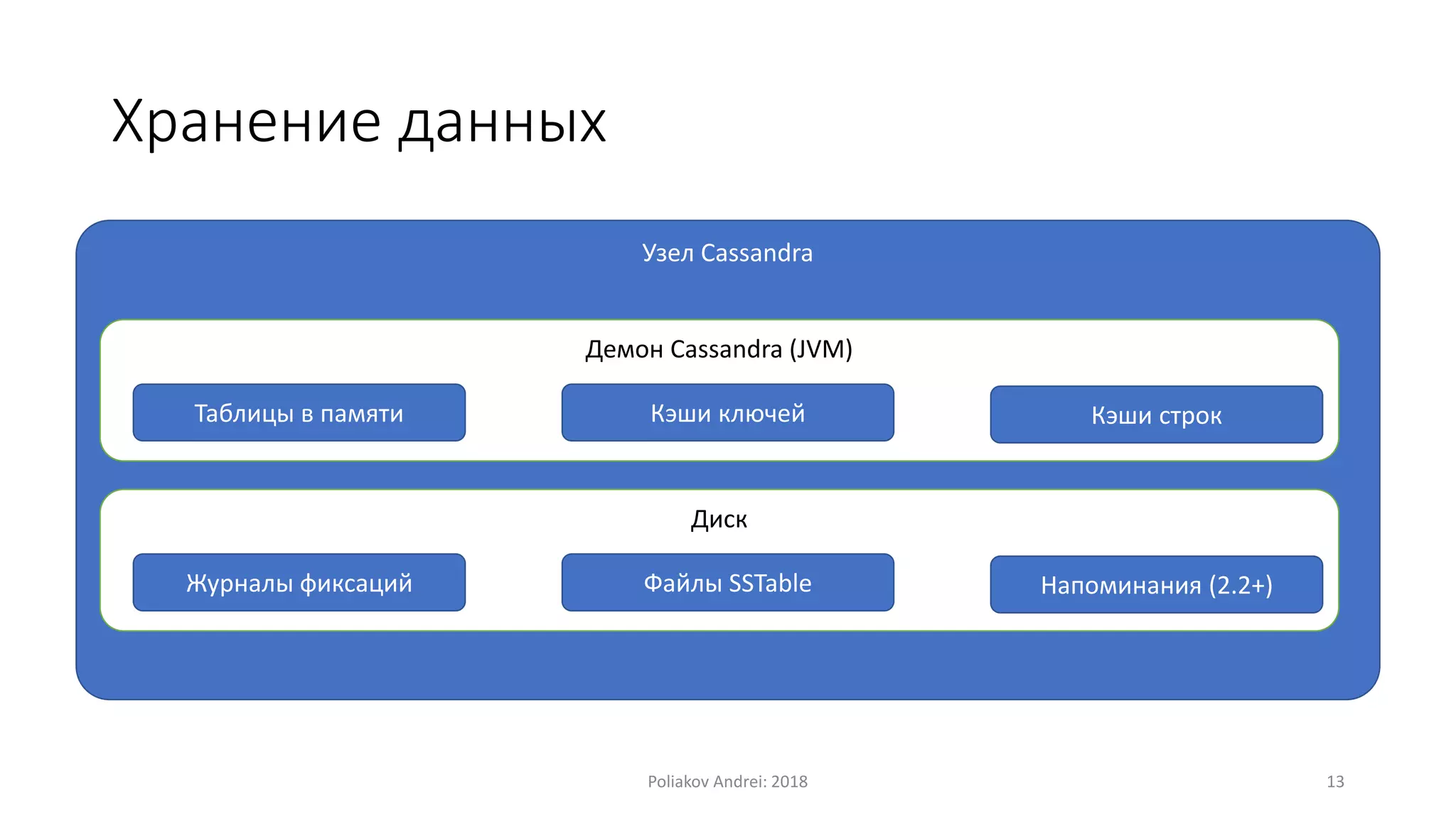





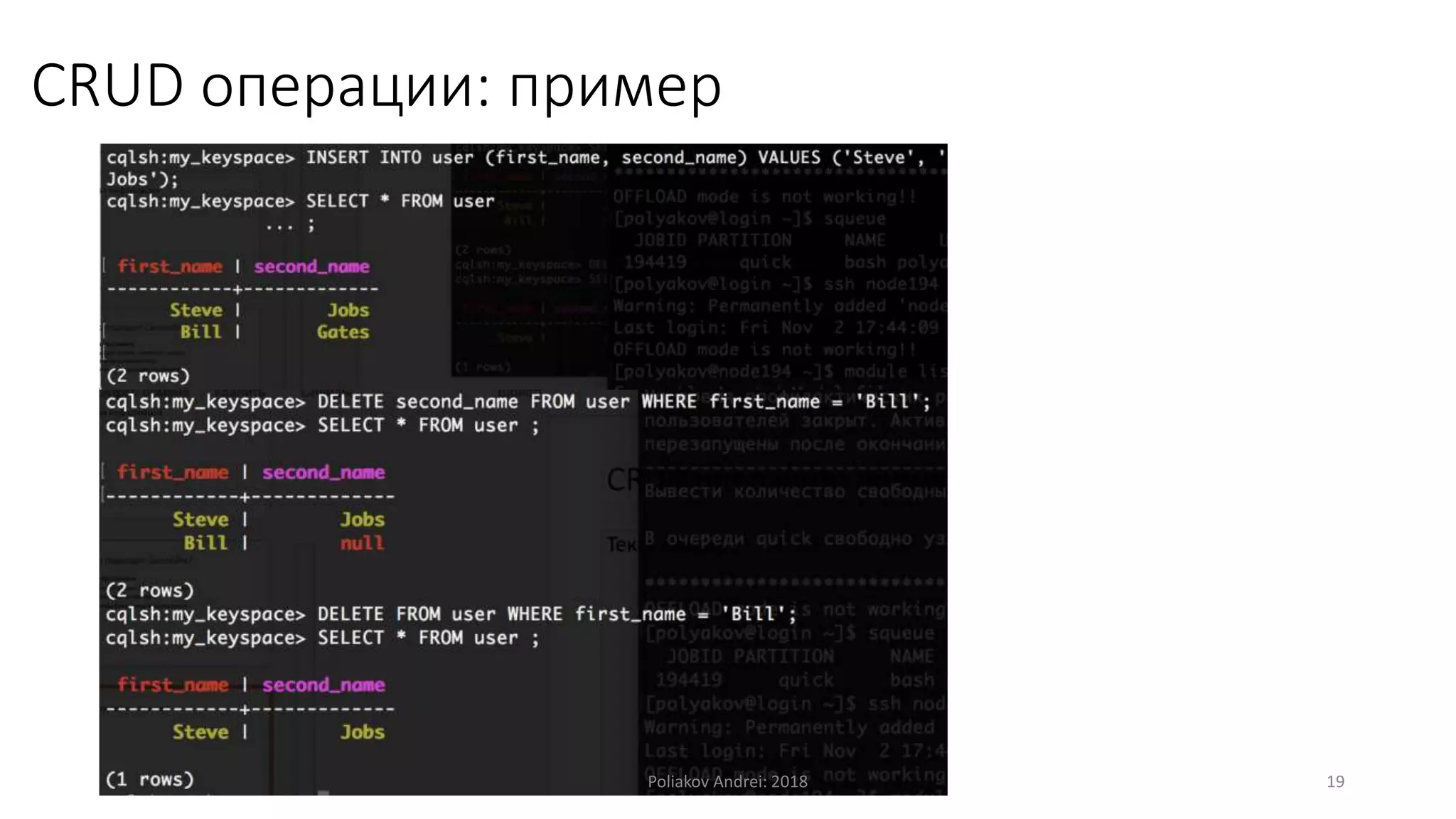







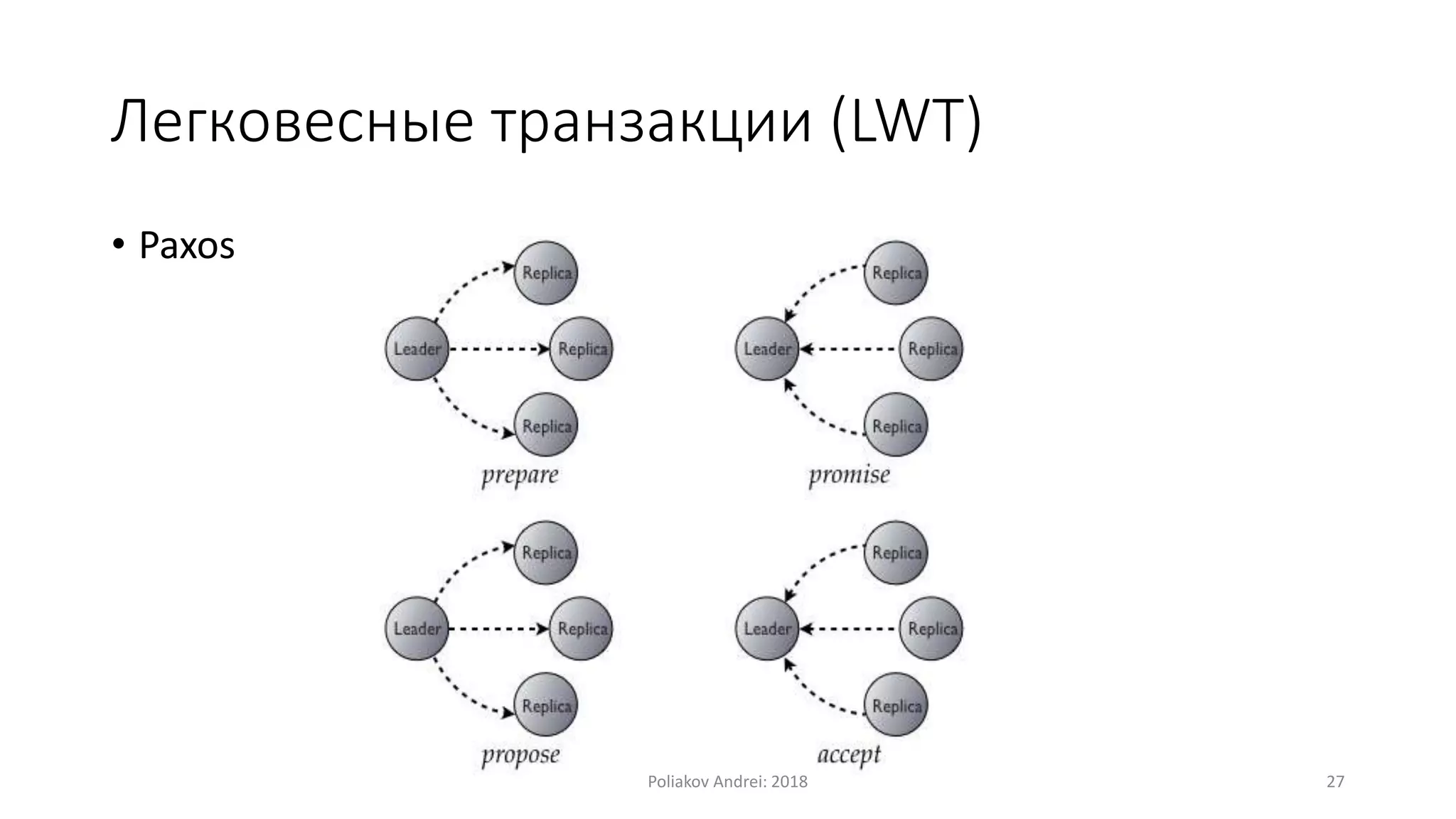
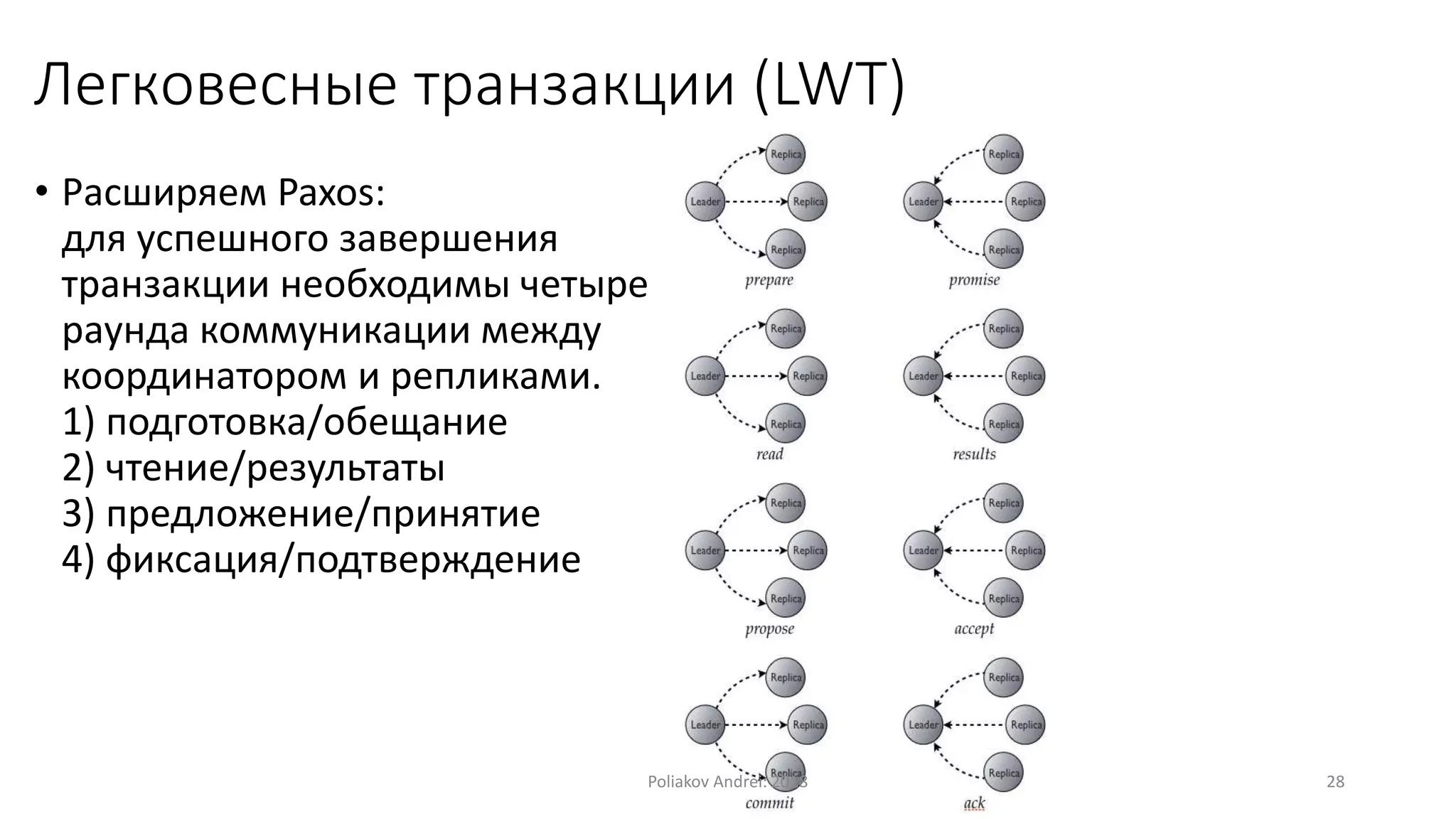































Документ описывает Apache Cassandra, распределенную и отказоустойчивую СУБД, созданную Facebook и поскольку используется многими крупными компаниями. Он охватывает основные характеристики, такие как модели данных, механизмы записи и чтения, вопросы масштабируемости, консистентности и легковесные транзакции. Также рассматриваются преимущества и недостатки Cassandra, а также учебные примеры и вопросы для самопроверки.














































