
Downloaded 18 times













![Analyzing Citation Patterns
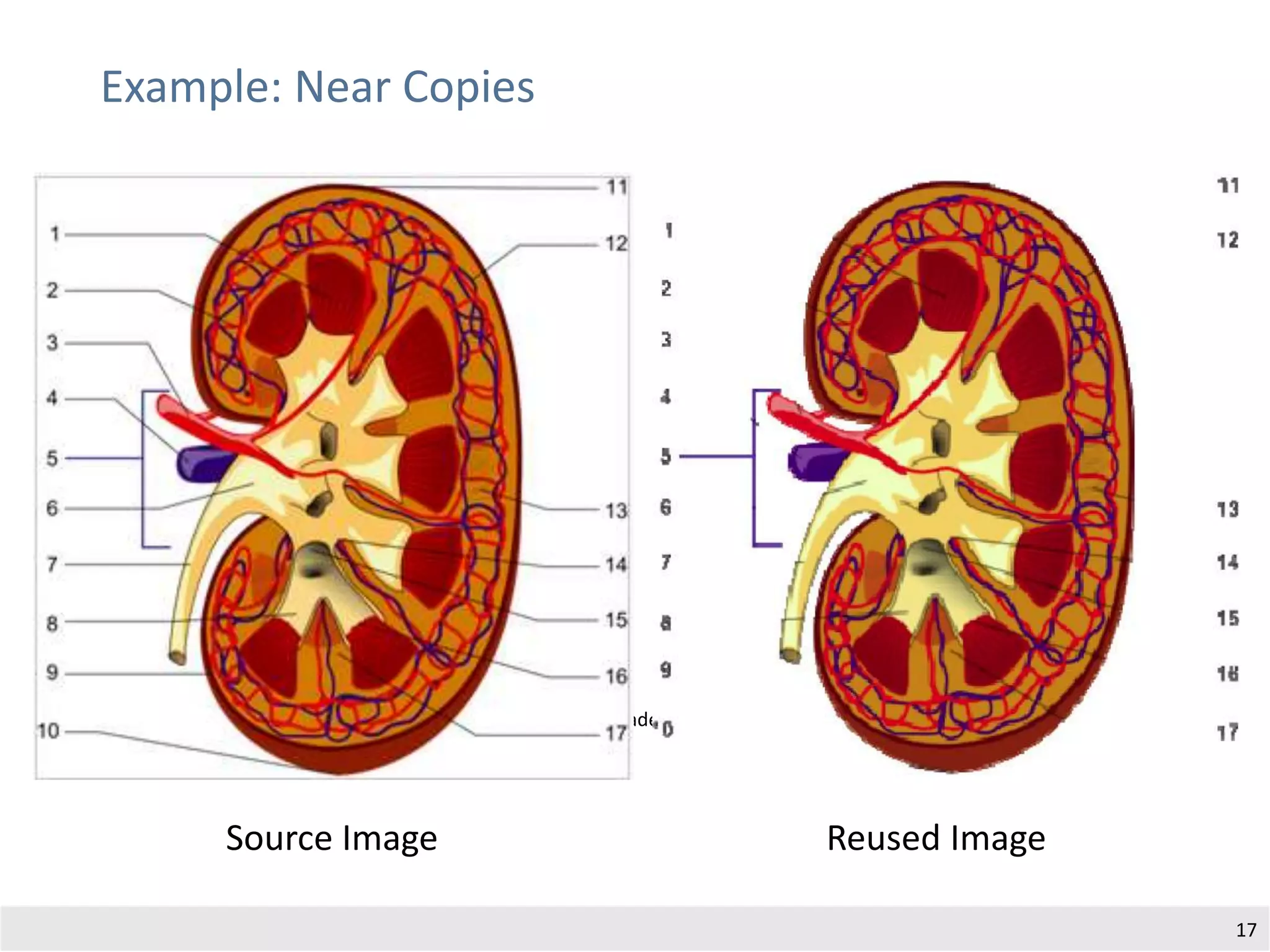
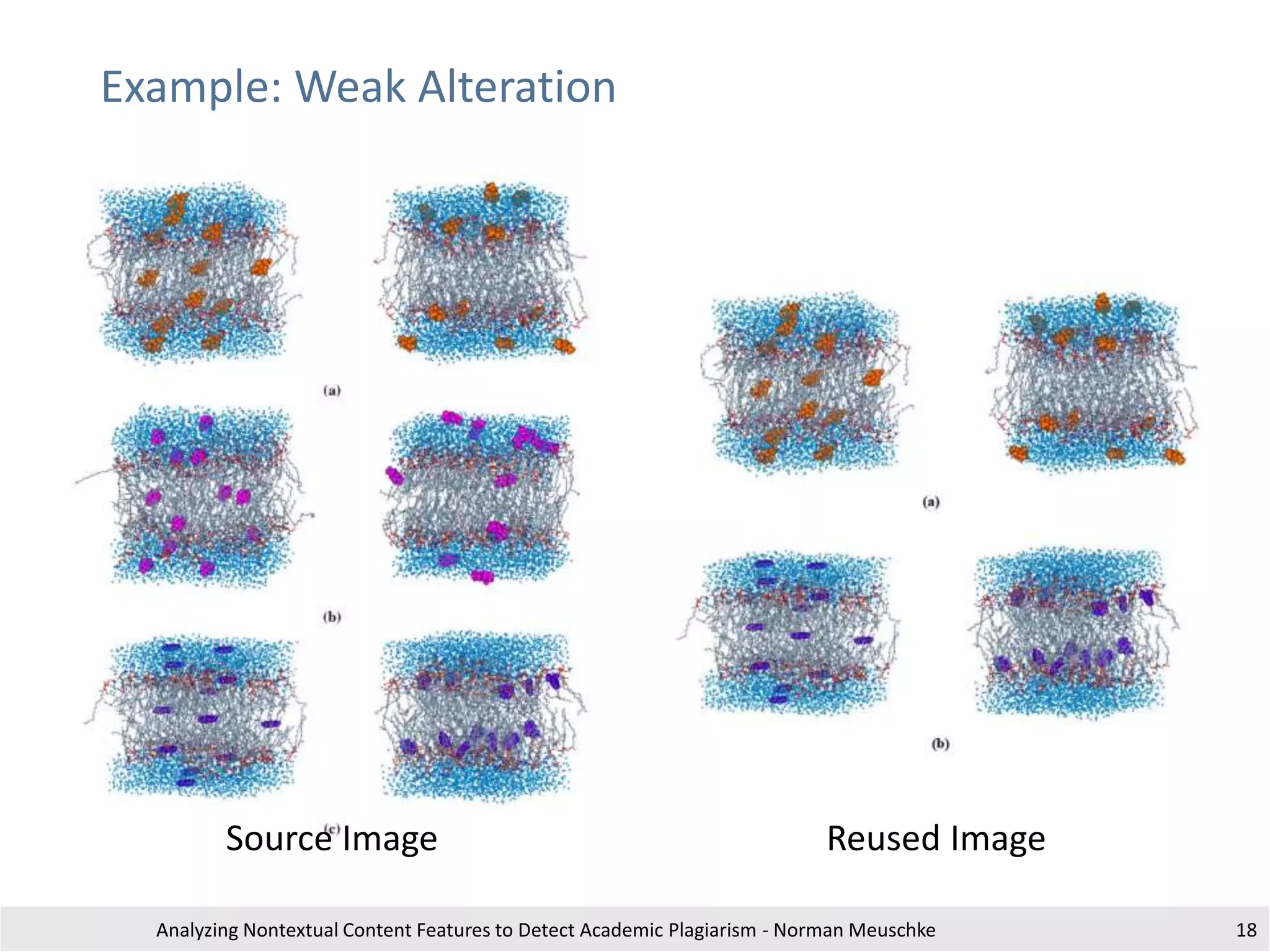
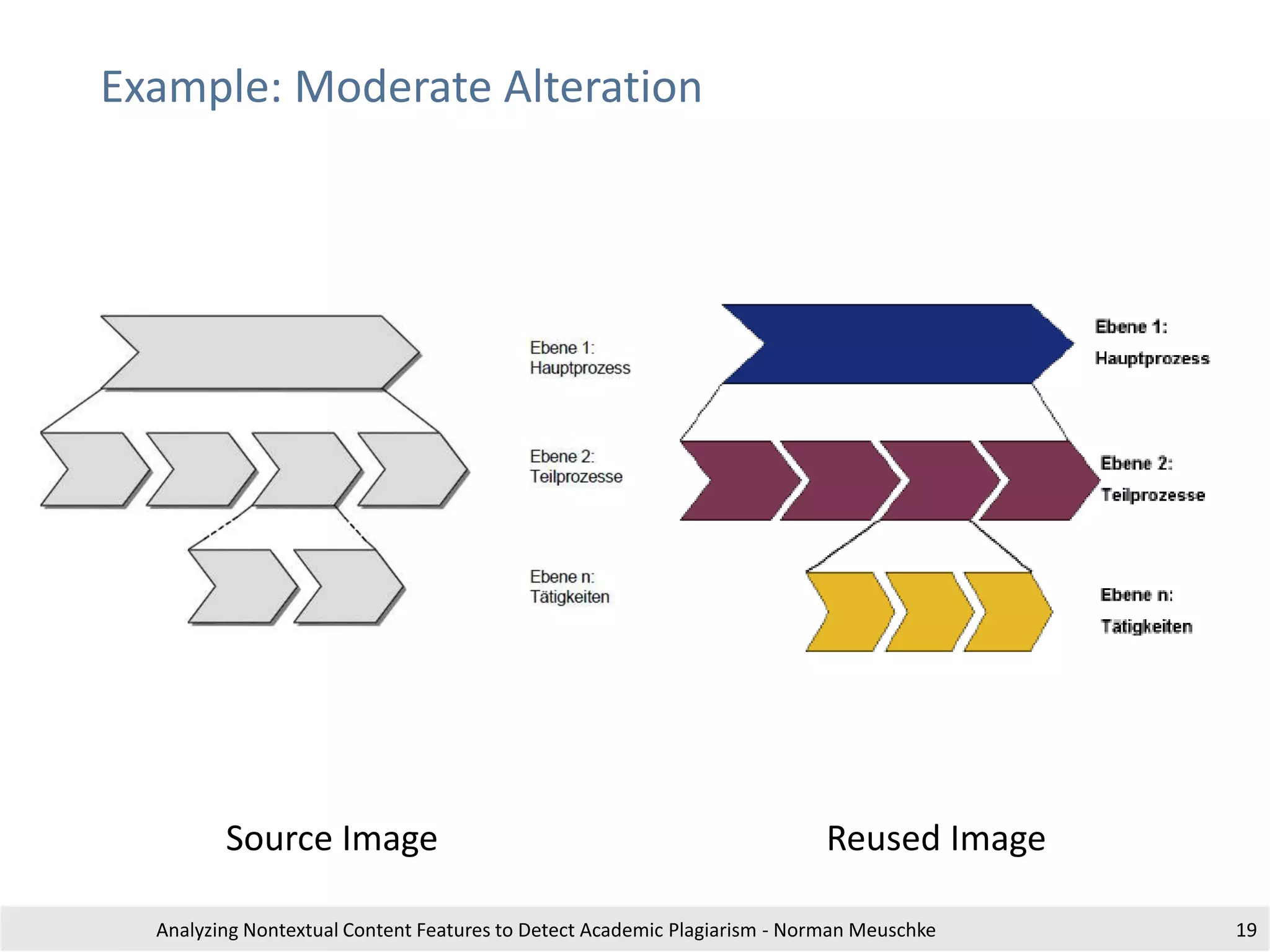
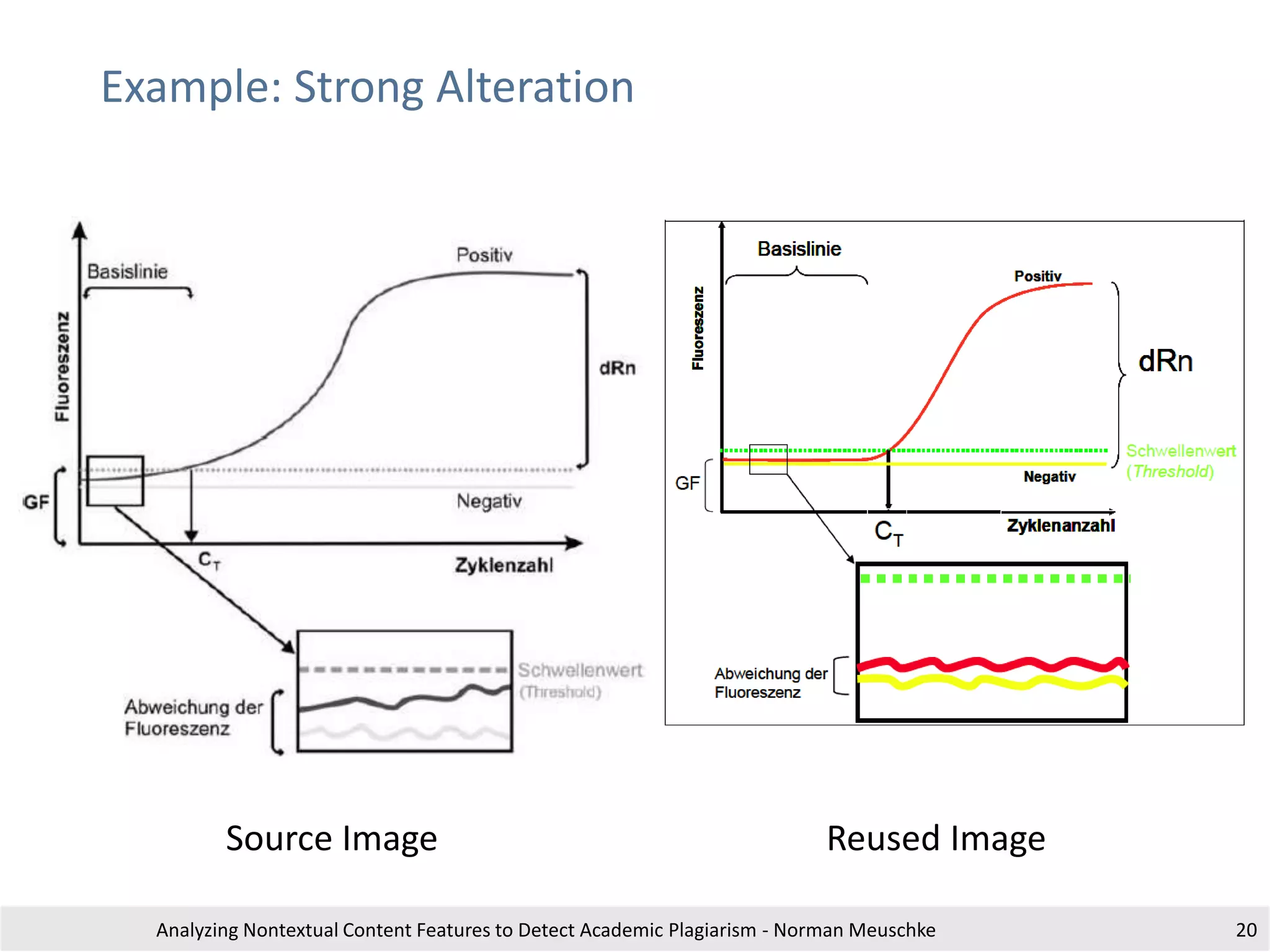
Analyzing Nontextual Content Features to Detect Academic Plagiarism - Norman Meuschke 17
Doc C
Doc E
Doc D
Section 1
This is an exampl etext withreferences to different documents for illustratingtheusageof
citation analysis for plagiari sm detection. This is an exampl etext withreferences to
different documents for illustrati ng the usage of citationanalysis forplagiarism detection .
This is ain-text citation [1].This is an exampl etext withreferences to different documents
for illustrating the usage of citation analysis for plagiari sm detection . This is an exampl e
text withreferenc es to differentdocuments fori llustratingthe usage ofci tation analysis
for plagiarism detection.
Section 2
Another in-text citation [2].tThis is anexample text with references todifferent
documents for illustrati ng the usage of citationanalysis forplagiarism detection. This is an
ex ampletext with references to different documents for illustrati ng the usageof citation
anal ysis for plagiarism detection. This is arepeated in-text citation [1].
This is an exampl etext withreferences to different documents for illustratingtheusageof
citation analysis for plagiari sm detection. This is an exampl etext withreferences to
different documents for illustrati ng the usage of citationanalysis forplagiarism detection .
Setion 3
A third in-text citation [3].This is an exampl etext withreferences to different documents
for illustrating the usage of citation analysis for plagiari sm detection . This is an exampl e
text withreferenc es to differentdocuments fori llustratingthe usage ofci tation analysis
for plagiarism detection. a final i n-text-citation[2].
References
[1]
[2]
[3]
Document B
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection. This is ain-text citation [1].This is an
ex ampletext with references to different documents for illustrati ng the usageof citation
anal ysis for plagiarism detection. Another exampl efor ani n-text citation [2].
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection.
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection. This is an exampl etext withreferences to
different documents for illustrati ng the usage of citationanalysis forplagiarism
detection. This is an exampl etext withreferences to different documents for illustrating
the usage ofcitation analysi s for pl agiarism detection.
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection. This is an exampl etext withreferences to
different documents for illustrati ng the usage of citationanalysis forplagiarism
detection. Here s a third in-text citation [3].This is an exampl etext withreferences to
different documents for illustrati ng the usage of citationanalysis forplagiarism
detection.
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection.
Document A
References
[1]
[2]
[3]
EDC DECDC
Citation Pattern Citation Pattern
Doc A Doc B
Ins.EIns.DC
DECDC
Pattern Comparison
Doc A
Doc B](https://image.slidesharecdn.com/niislideshareslides-180614042602/75/Analyzing-Nontextual-Content-Features-to-Detect-Academic-Plagiarism-17-2048.jpg)






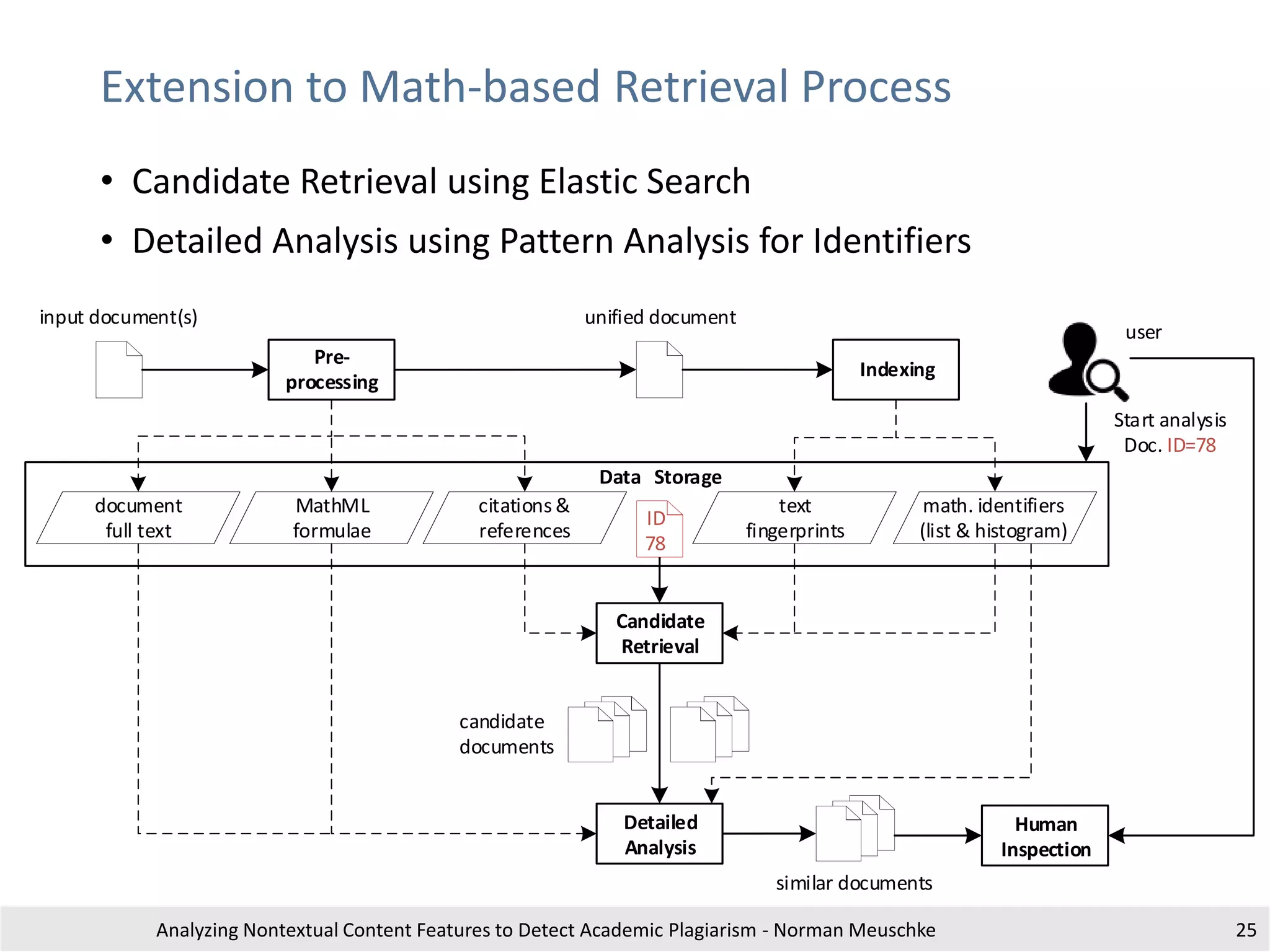




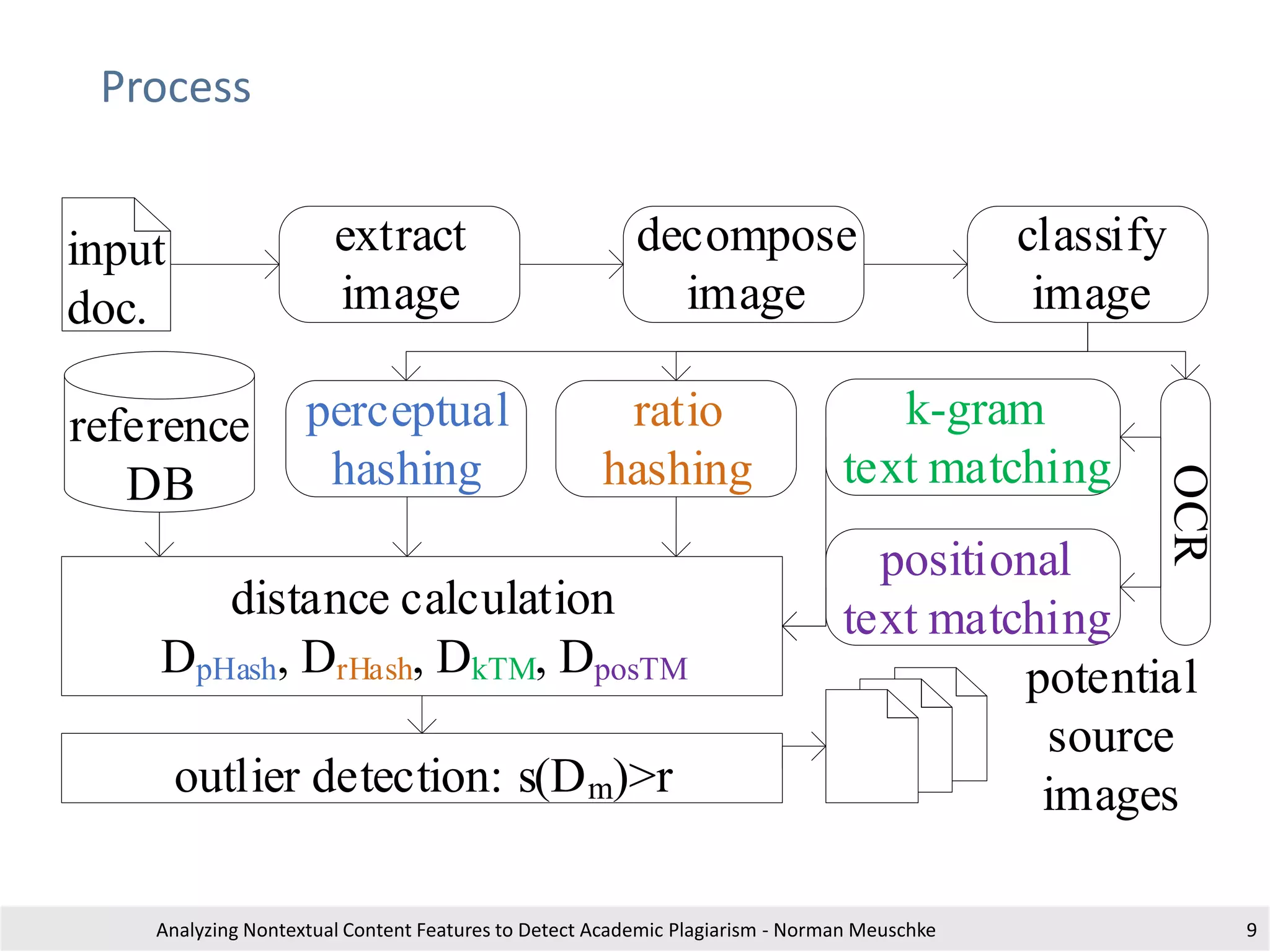


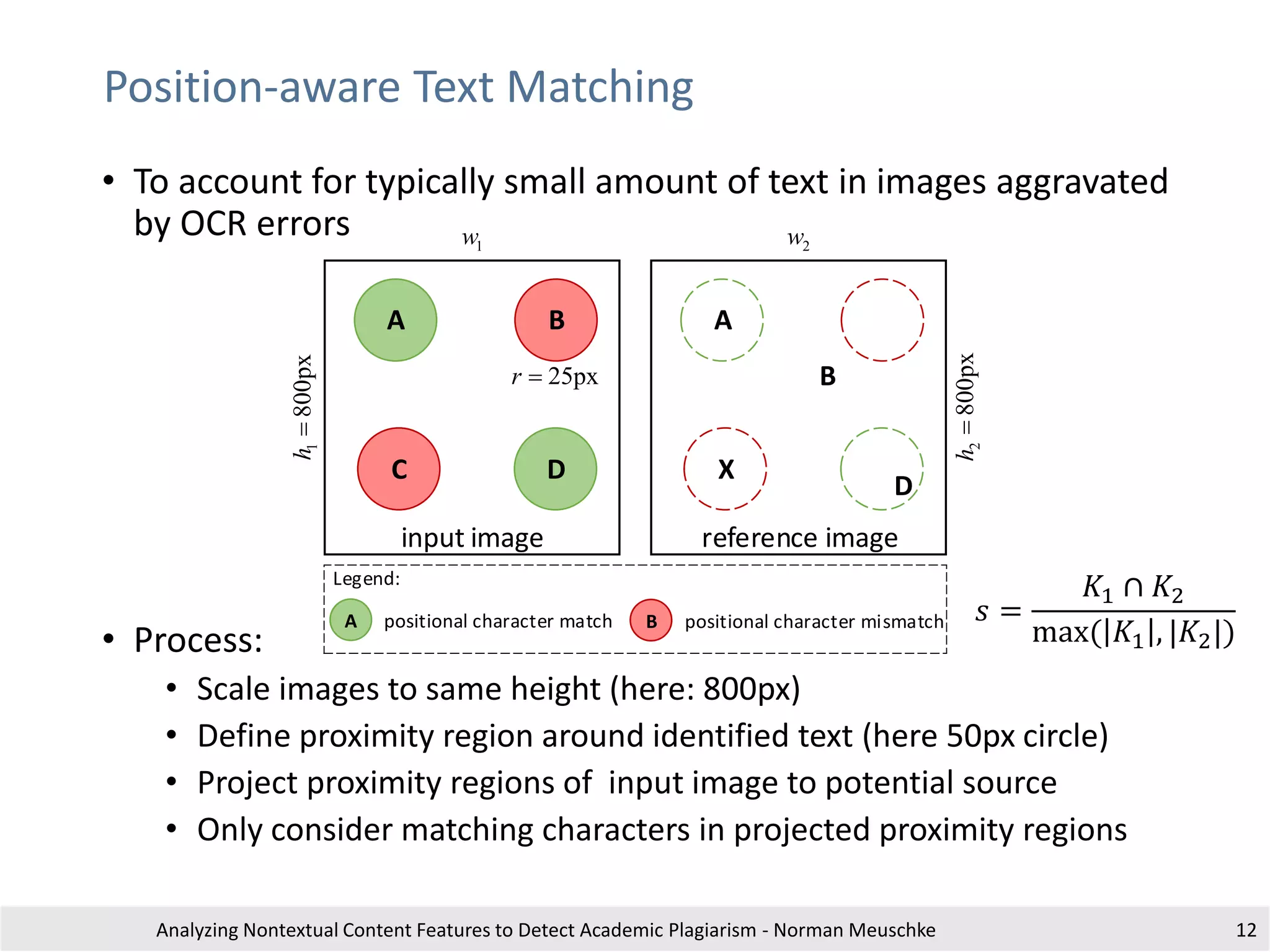
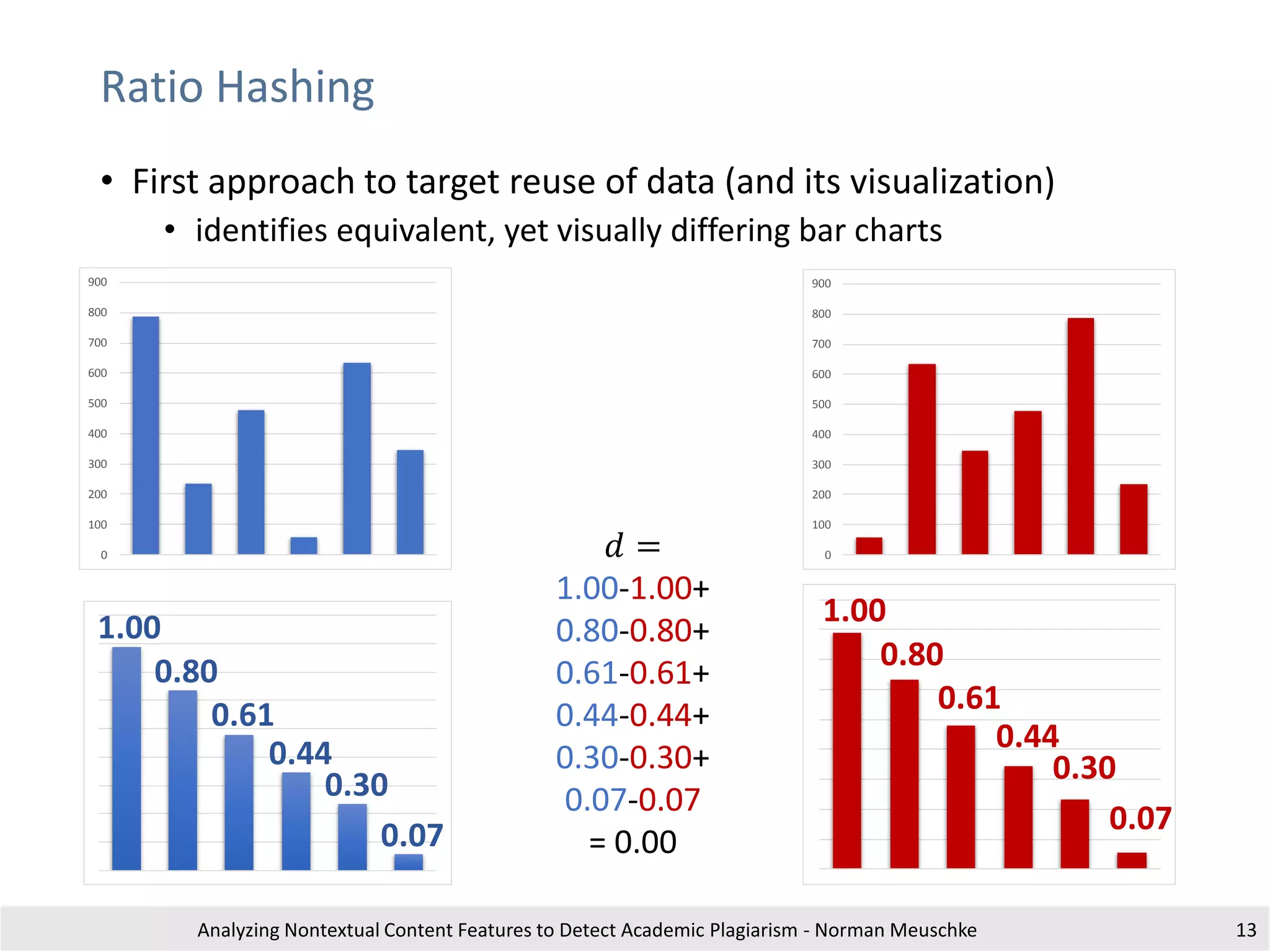






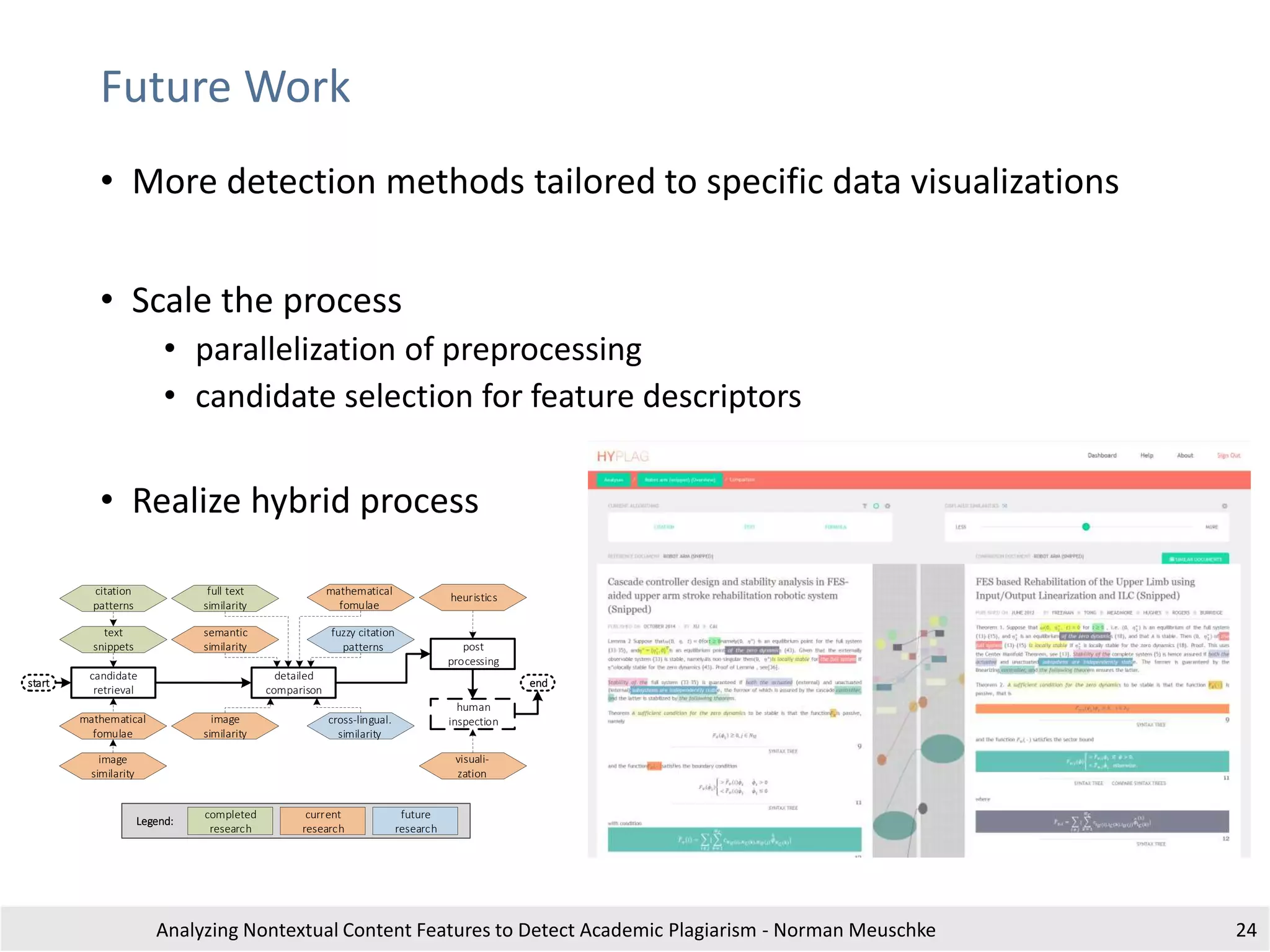


The document outlines research by Norman Meuschke on detecting academic plagiarism through analyzing nontextual content features, such as citations, mathematics, and images. It discusses various forms of plagiarism, the effectiveness of detection methods, and the research group's focus on semantic analysis and user-driven approaches. The study emphasizes the importance of innovative detection strategies to enhance the identification of disguised plagiarism in diverse academic disciplines.














![[IJET-V1I6P17] Authors : Mrs.R.Kalpana, Mrs.P.Padmapriya](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i6p17-160110012712-thumbnail.jpg?width=640&height=640&fit=bounds)








































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















