Download to read offline








































![51
More info
1. Inference series I: How to use Caffe with AWS’ Deep Learning AMI
for Semantic Segmentation
2. Inference series I [2nd round]: How to use Caffe with AWS’ Deep
Learning AMI for Semantic Segmentation](https://image.slidesharecdn.com/meetuppythonmadrid2018-180511073940/75/Meetup-Python-Madrid-2018-Segmentacion-semantica-Pero-de-que-me-estas-hablando-Ricardo-Guerrero-51-2048.jpg)





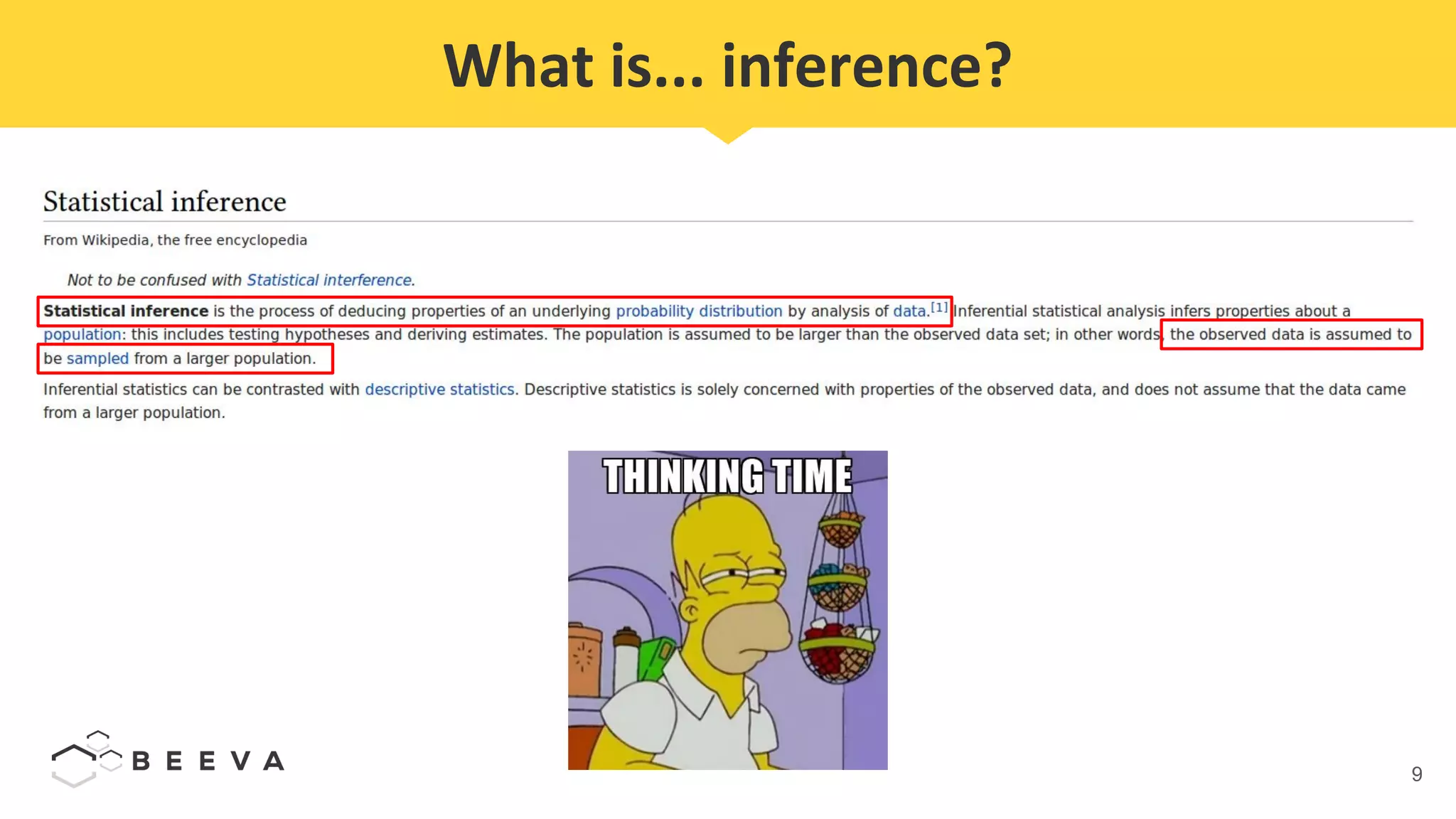
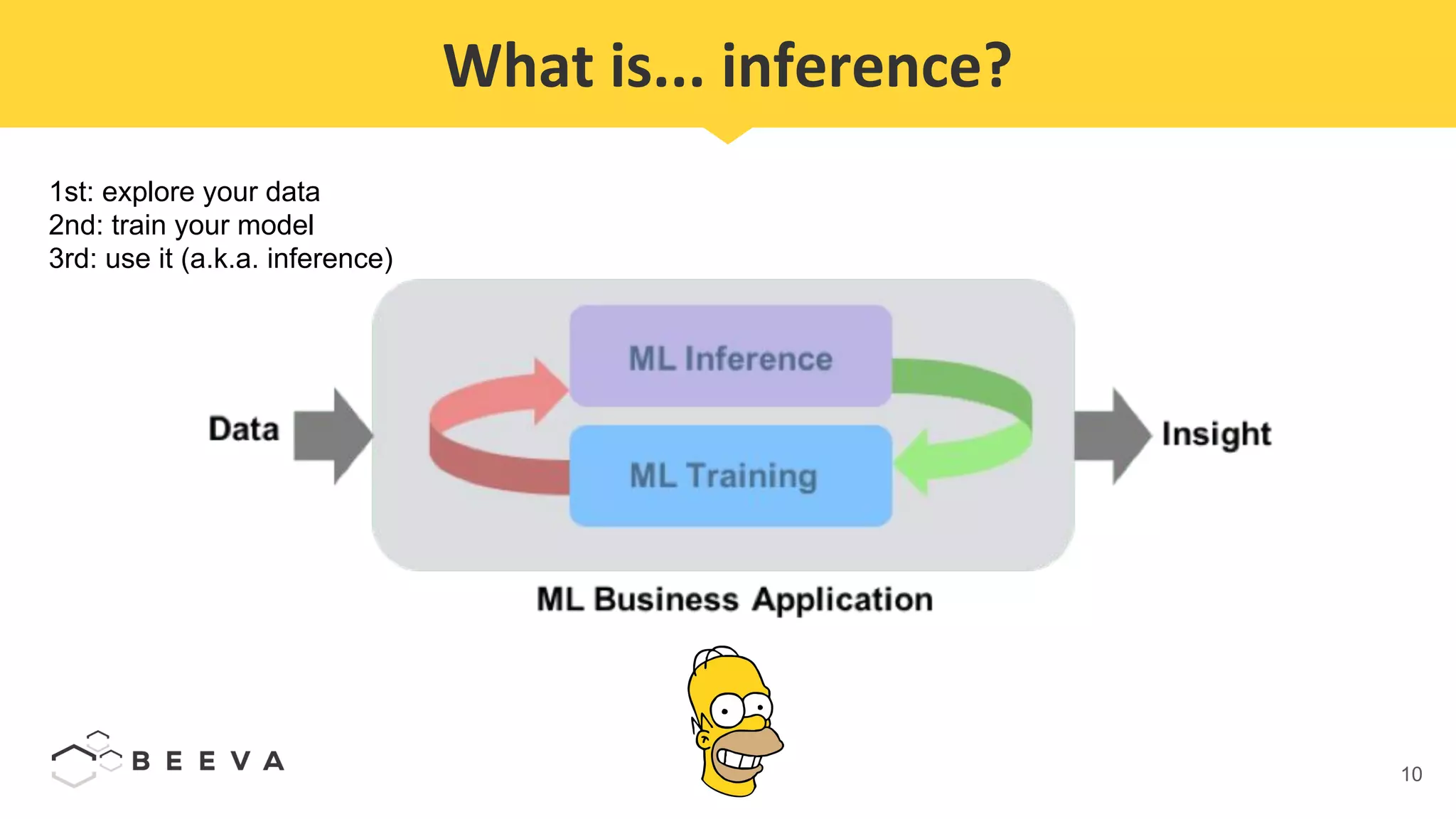
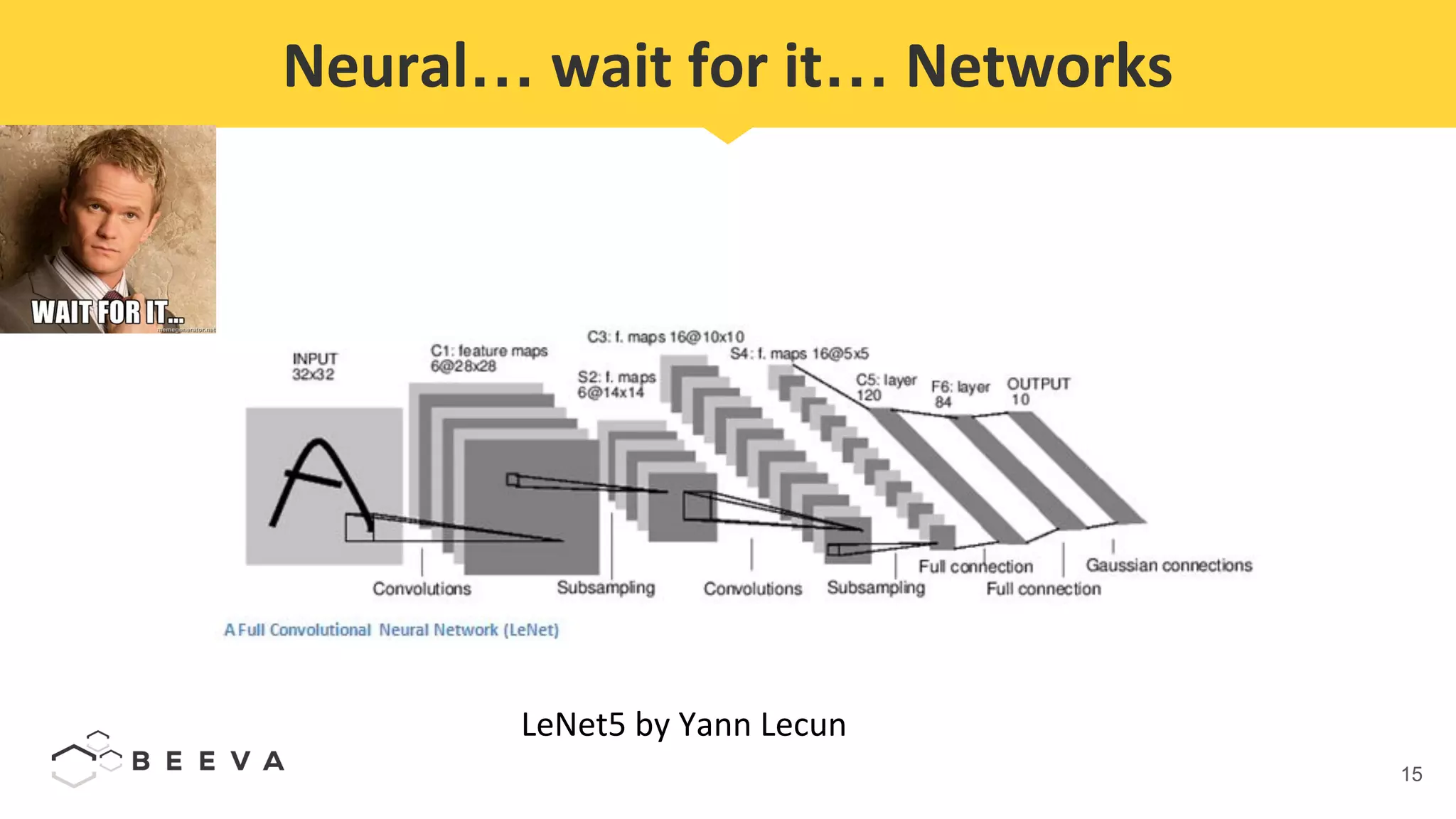
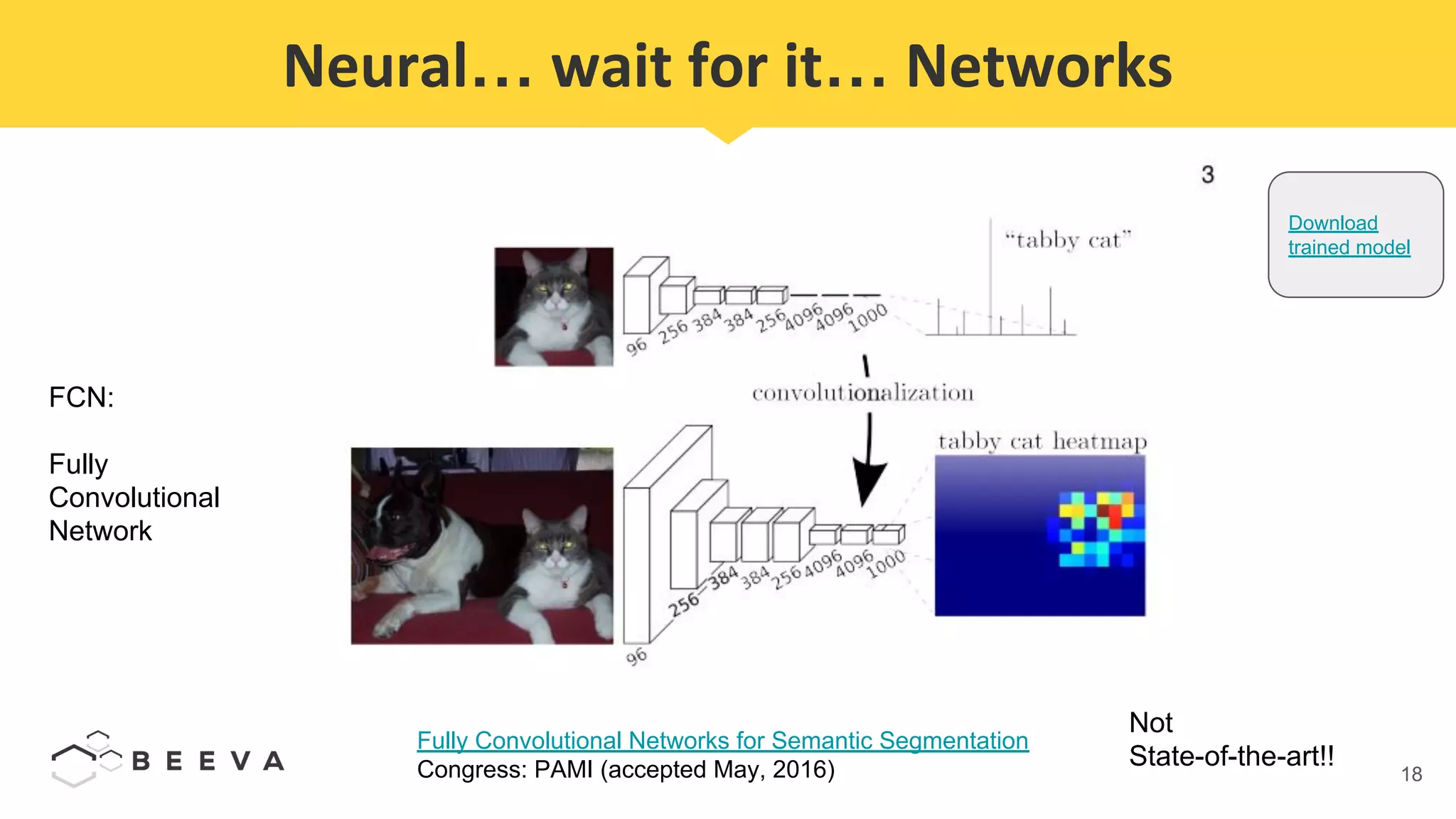
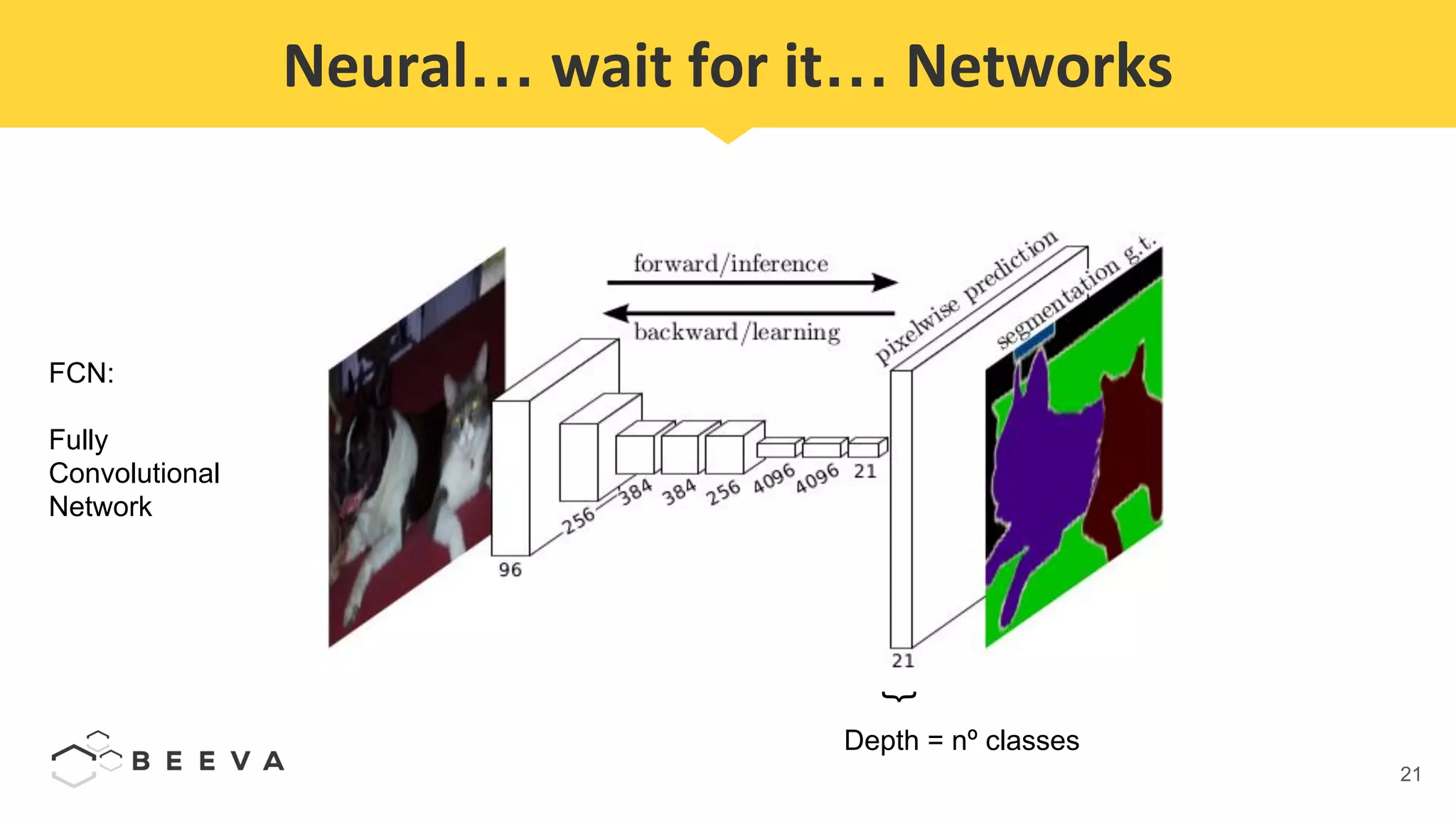
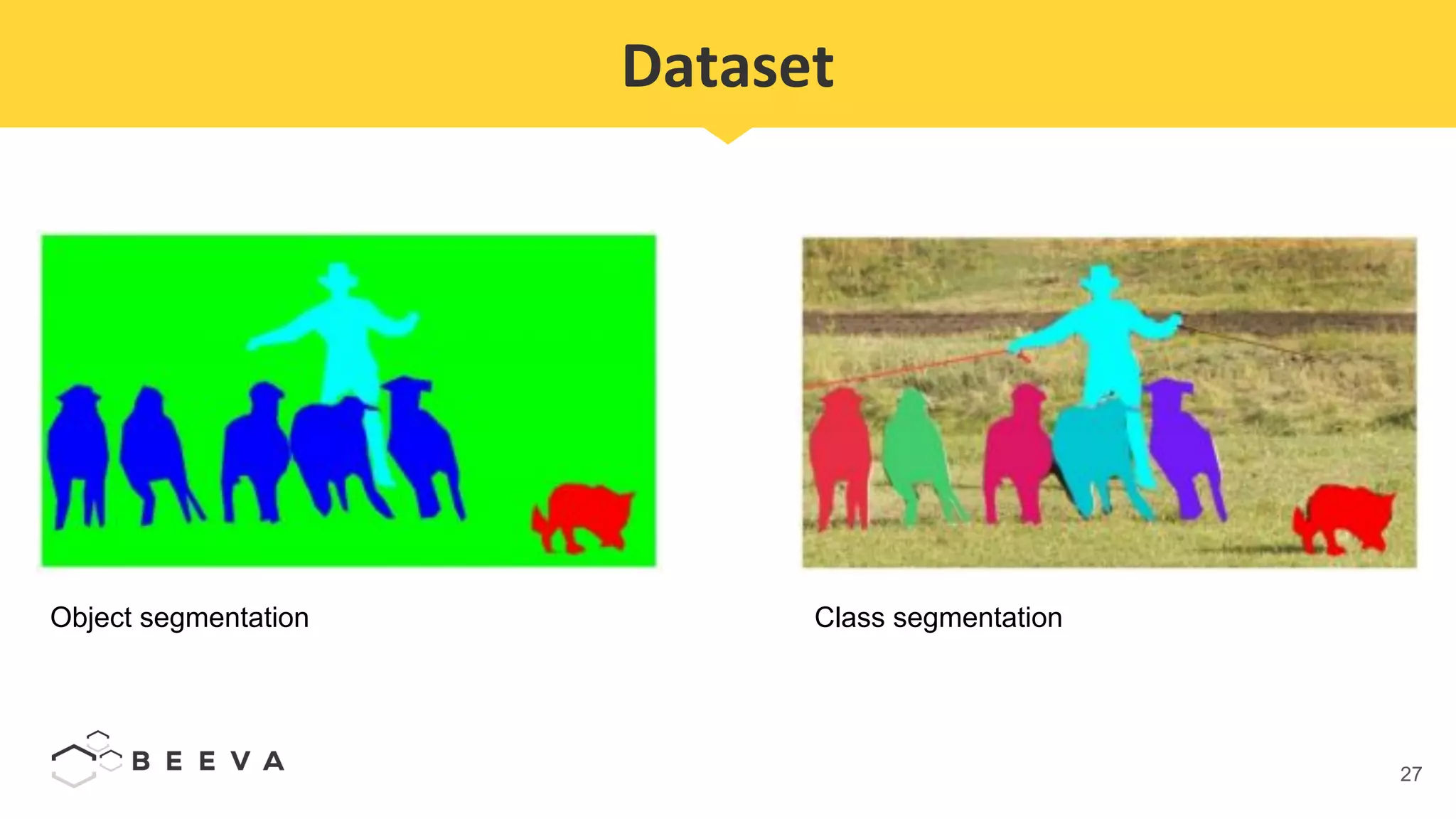
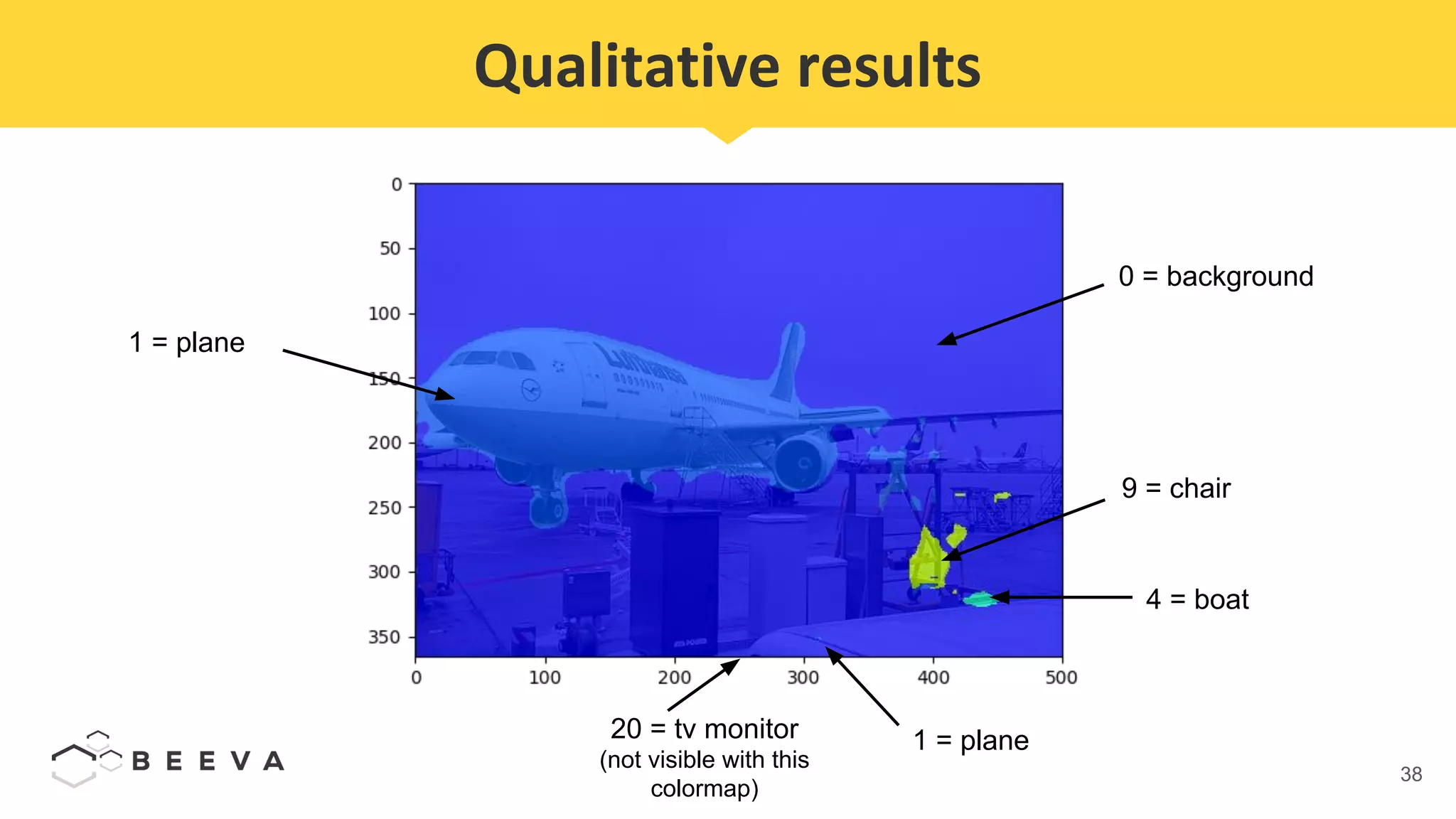
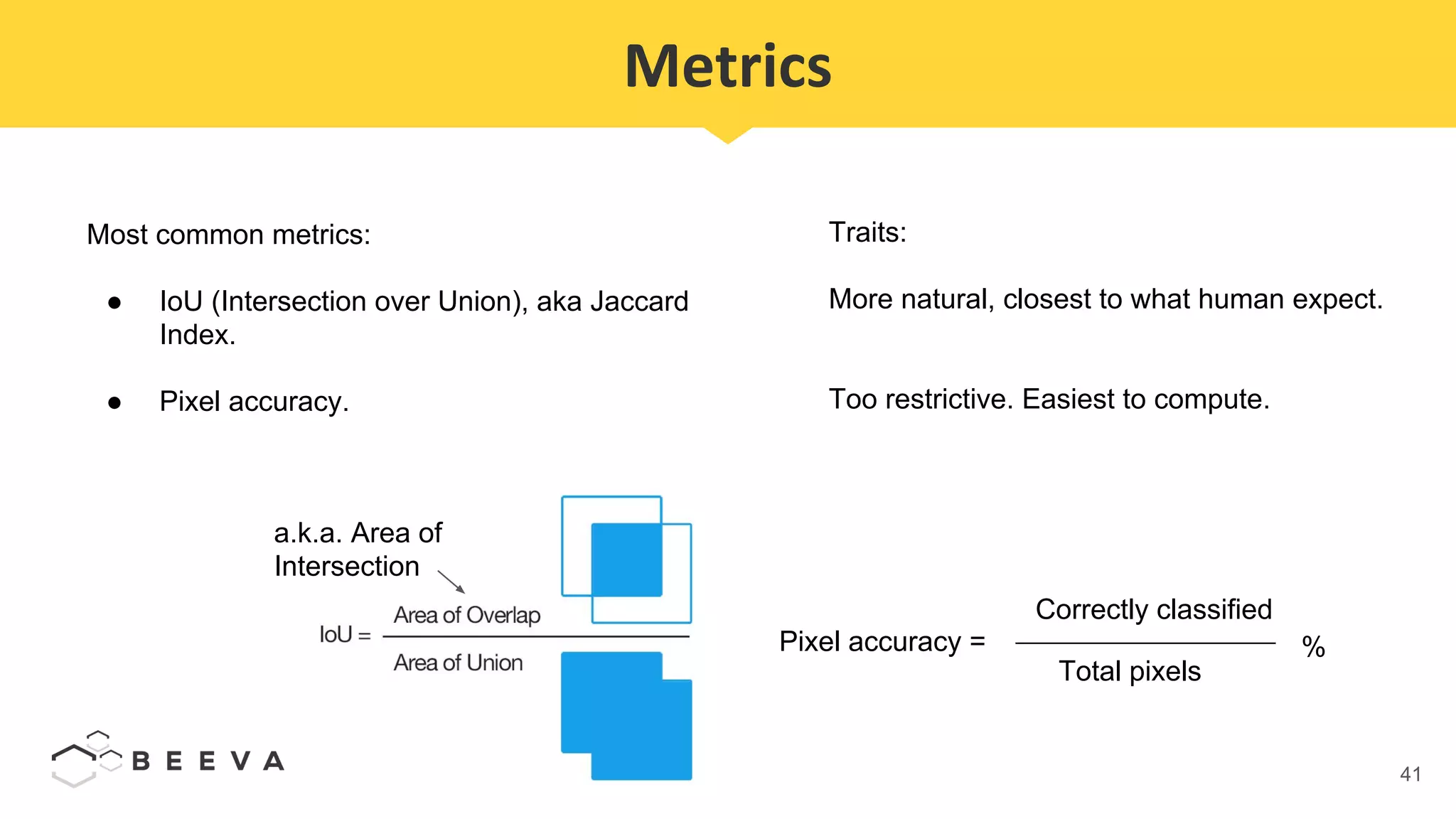
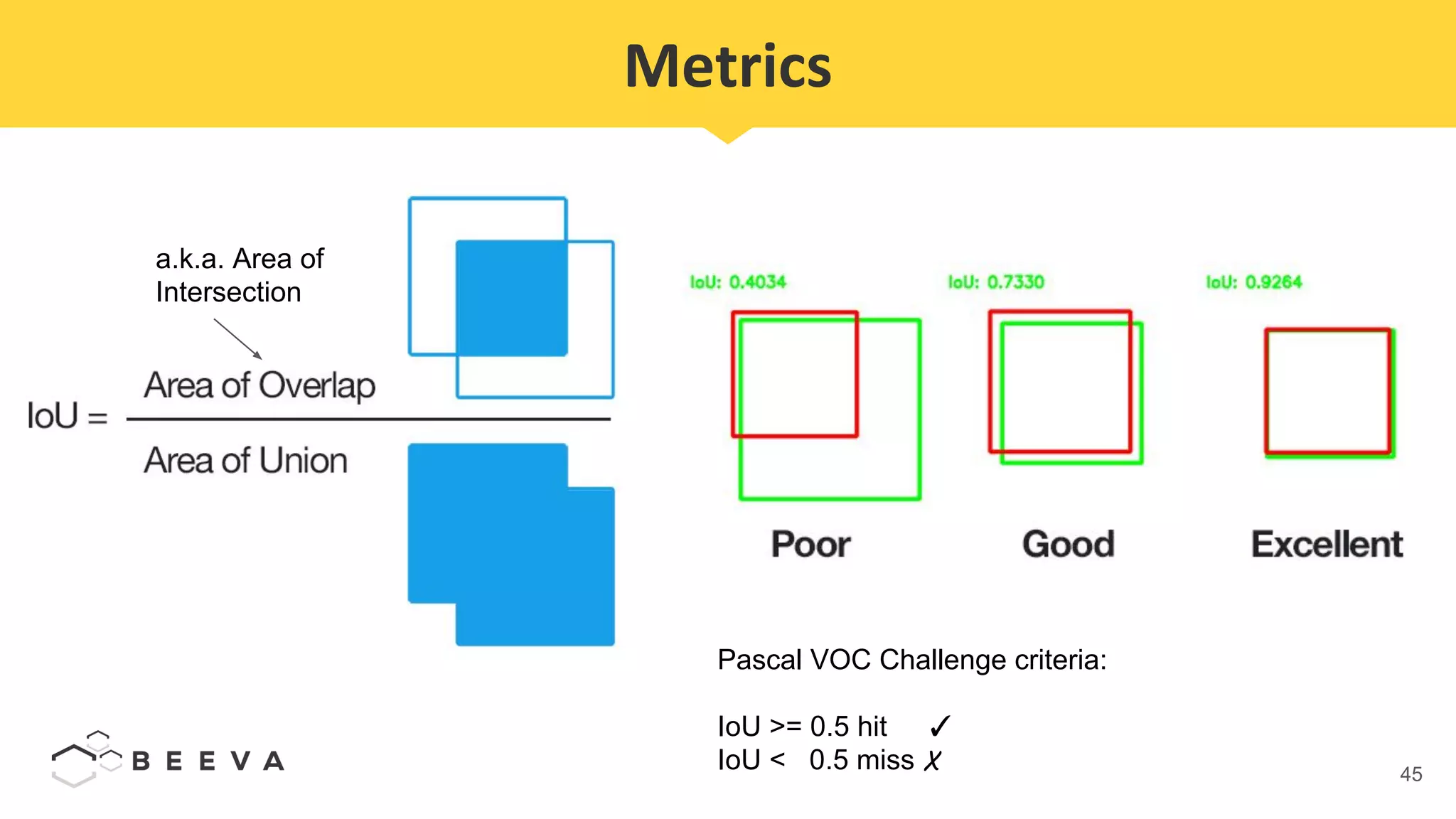
The document discusses semantic segmentation, which involves classifying each pixel in an image rather than just detecting objects. It describes using a Fully Convolutional Network model for semantic segmentation on the PASCAL VOC 2012 dataset. Quantitative results show a mean pixel accuracy of 68.5% without using ignore labels and 74.5% when using ignore labels. Processing each image for semantic segmentation takes approximately 7.6 seconds on an AWS M5.large virtual machine without a GPU.




























![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)







