Downloaded 17 times





![©2018 Logical Clocks AB. All Rights Reserved
ImageNet
[Image from https://www.slideshare.net/xavigiro/image-classification-on-imagenet-d1l4-2017-upc-deep-learning-for-computer-vision ]
6/38](https://image.slidesharecdn.com/dotai-dowling-logical-clocks-180604114144/75/All-AI-Roads-lead-to-Distribution-Dot-AI-6-2048.jpg)



![Faster Training of ImageNet
Single GPU
[Image from https://www.matroid.com/scaledml/2018/jeff.pdf]
Clustered GPUs](https://image.slidesharecdn.com/dotai-dowling-logical-clocks-180604114144/75/All-AI-Roads-lead-to-Distribution-Dot-AI-10-2048.jpg)







![import hops.hdfs as hdfs
features = ["Age", "Occupation", "Sex", …, "Country"]
with open(hdfs.project_path() +
"/TestJob/data/census/adult.data", "r") as trainFile:
train_data=pd.read_csv(trainFile, names=features,
sep=r's*,s*', engine='python', na_values="?")
Data Ingestion with Pandas
Right
Thumb
Here](https://image.slidesharecdn.com/dotai-dowling-logical-clocks-180604114144/75/All-AI-Roads-lead-to-Distribution-Dot-AI-22-2048.jpg)
![import hops.hdfs as hdfs
features = ["Age", "Occupation", "Sex", …, "Country"]
h = hdfs.get_fs()
with h.open_file(hdfs.project_path() +
"/TestJob/data/census/adult.data", "r") as trainFile:
train_data=pd.read_csv(trainFile, names=features,
sep=r's*,s*', engine='python', na_values="?")
Data Ingestion with Pandas on Hops
Right
Thumb
Here](https://image.slidesharecdn.com/dotai-dowling-logical-clocks-180604114144/75/All-AI-Roads-lead-to-Distribution-Dot-AI-23-2048.jpg)




![GridSearch with TensorFlow/Spark on Hops
def train(learning_rate, dropout):
[TensorFlow Code here]
args_dict = {'learning_rate': [0.001, 0.005, 0.01],
'dropout': [0.5, 0.6]}
experiment.launch(spark, train, args_dict)
Launch 6 Spark Executors
28/38](https://image.slidesharecdn.com/dotai-dowling-logical-clocks-180604114144/75/All-AI-Roads-lead-to-Distribution-Dot-AI-28-2048.jpg)
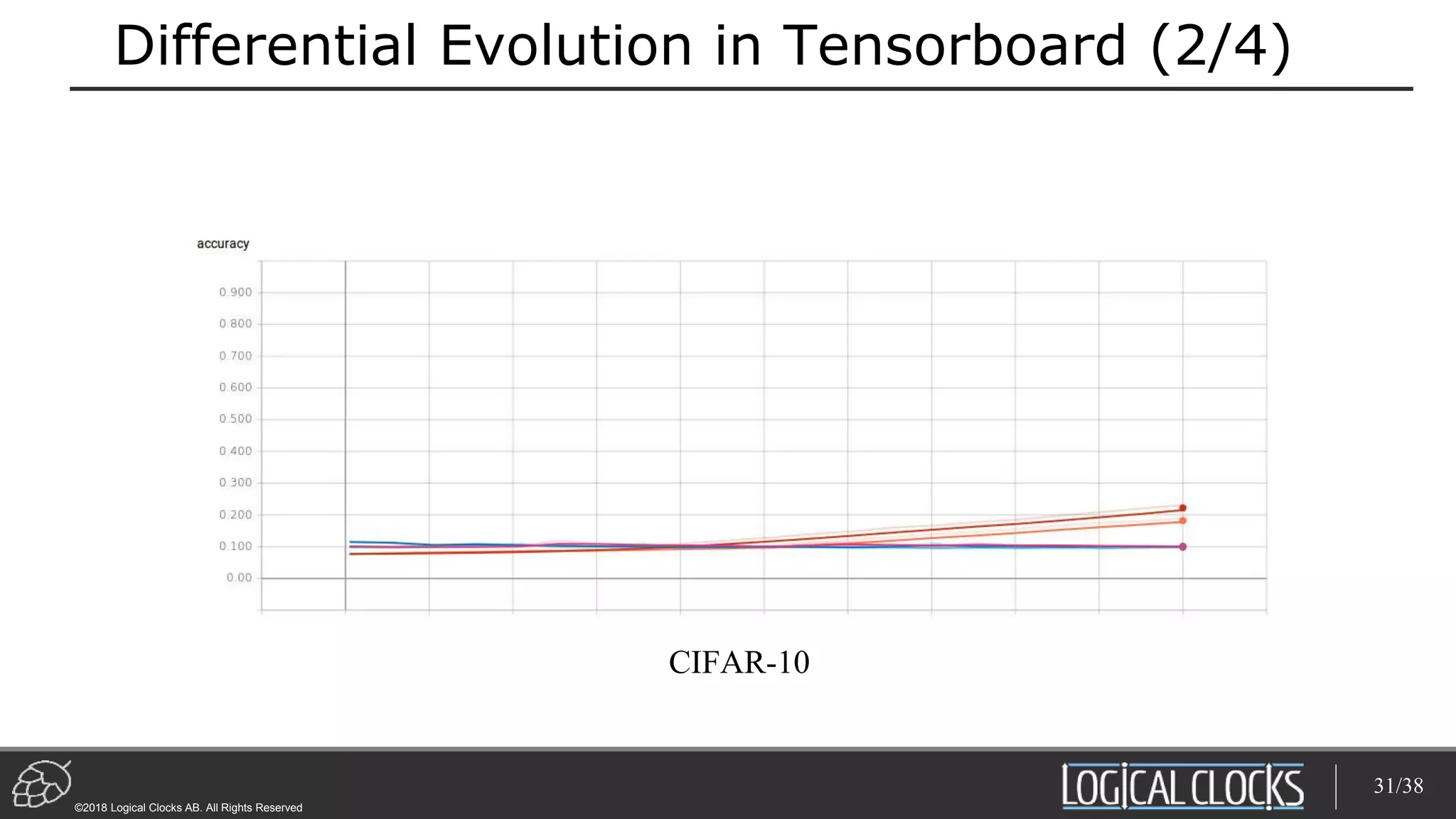
![Model Architecture Search on TensorFlow/Hops
def train_cifar10(learning_rate, dropout, num_layers):
[TensorFlow Code here]
dict = {'learning_rate': [0.005, 0.00005],
'dropout': [0.01, 0.99], 'num_layers': [1,3]}
experiment.evolutionary_search(spark, train, dict,
direction='max', popsize=10, generations=3, crossover=0.7,
mutation=0.5)
29/38
Launch 10 Spark Executors](https://image.slidesharecdn.com/dotai-dowling-logical-clocks-180604114144/75/All-AI-Roads-lead-to-Distribution-Dot-AI-29-2048.jpg)


![Distributed Training with Horovod
hvd.init()
opt = hvd.DistributedOptimizer(opt)
if hvd.local_rank()==0:
[TensorFlow Code here]
…..
else:
[TensorFlow Code here]
…..
34/38](https://image.slidesharecdn.com/dotai-dowling-logical-clocks-180604114144/75/All-AI-Roads-lead-to-Distribution-Dot-AI-34-2048.jpg)




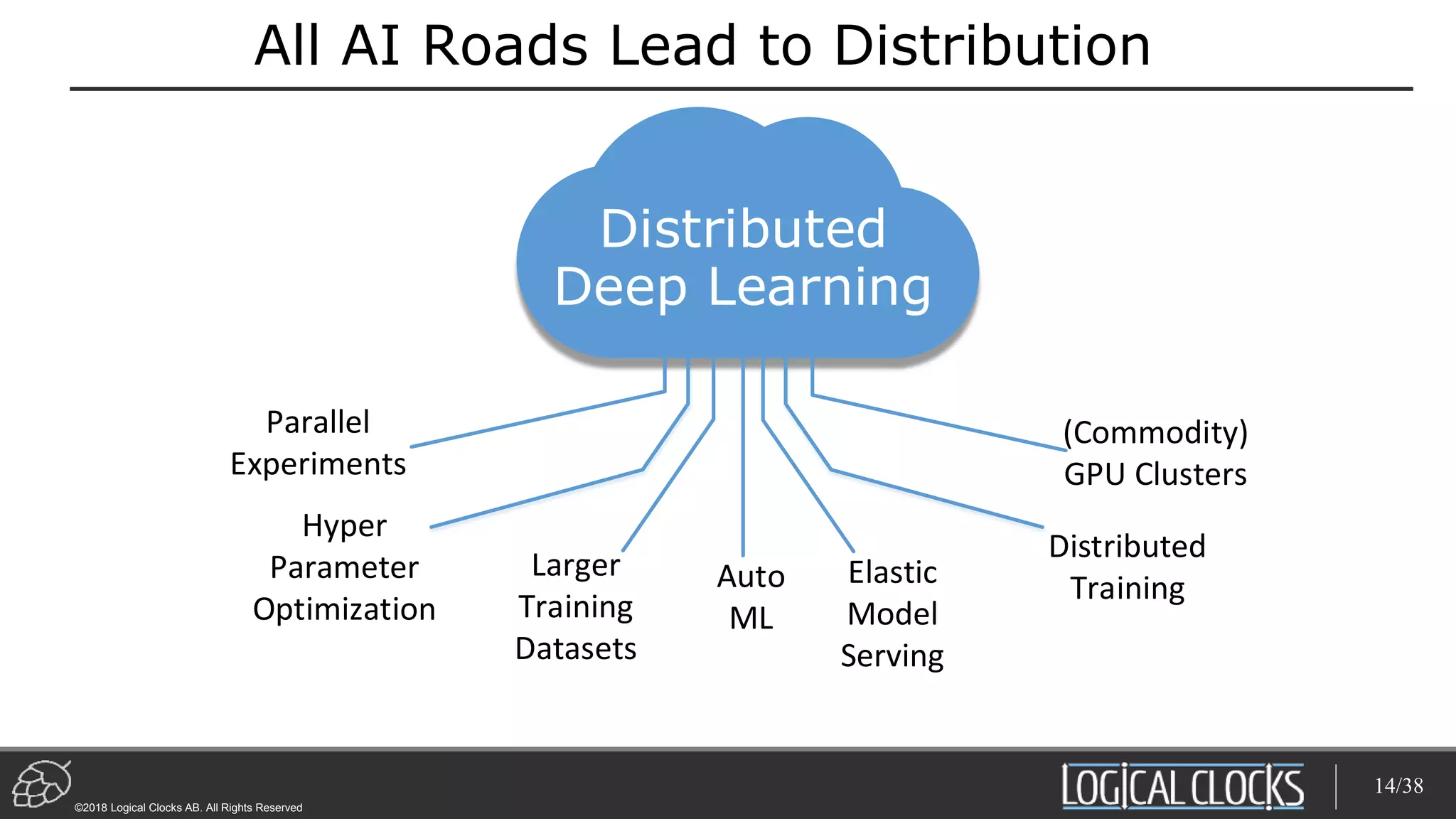
The document discusses how all roads of artificial intelligence lead to distributed systems and computing. It provides examples of how companies like Facebook and Google have improved the accuracy and training times of image recognition models by utilizing larger distributed training datasets and systems with thousands of GPUs and TPUs. The future of AI will rely on techniques like distributed deep learning, hyperparameter optimization, and elastic model serving that can scale computation across large computing clusters in the cloud or on-premise.




























![ARVC and flecainide case report[EI] Jim.docx.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/finalarvcandflecainidecasereporteijim-230918192356-cebc27e5-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)




