Downloaded 49 times





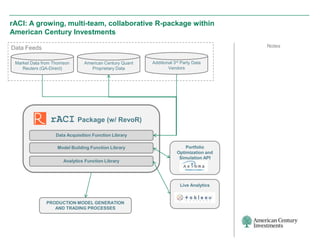


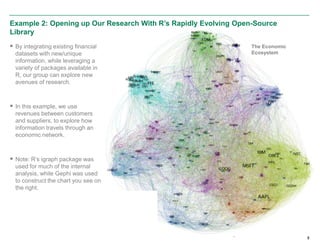



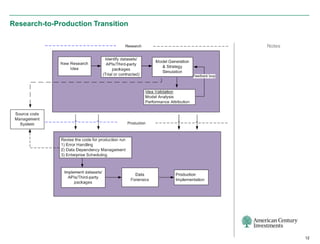

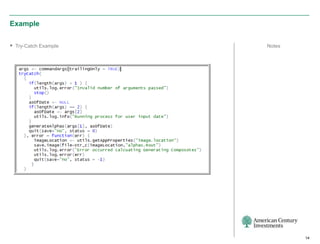





The document discusses the infrastructure overhaul undertaken by American Century Investments to enhance their quantitative research and portfolio management capabilities. It highlights the adoption of a new in-house quantitative research platform named Revor, which integrates advanced analytics, model building, and streamlined processes, resulting in improved performance and faster research turnaround. The transition is 75% complete, with positive outcomes and growing interest from other departments to utilize the new system.





































































































